類似画像検索のビジネス利用
具体的な活用例
今週の業務時間中、「探す」作業にどれぐらいの時間を使っただろうか。
実際に何かを入力したり、作成したりする作業ではないため、探す作業にかかる時間はあまり正確に把握されていないが、実際には探す作業に多大な時間を費やしていると考えられる。
単語(キーワード)から文書を探したり、日付や分類から文書や画像、もしくは実物を探すなど、業種・業界を問わず、誰かが常に何かを探している。つまり、探す作業の高速化・高度化はさまざまな業務の時間短縮、精度向上につながる可能性を秘めている。
そこで本稿では、画像から画像を探すタスクである「類似画像検索」について取り上げる。
ここ数年、Deep Learningによる画像解析への取り組みが本格化し、ビジネスでも多くの場面で用いられている。適用される技術はDeep Learning以外にもあるが、画像認識による代表的なタスクとしては以下が挙げられる。
分類:画像に何があるかを分類する(良品・不良品の判別など)
物体検出:画像の中に何があるかを見つけ出す(疵検出など)
顔認識:画像から顔を認識し、年齢や性別、同一人物かを判定する(入場ゲートなど)
類似画像検索:指定した画像に似た画像を検索する
物体検出:画像の中に何があるかを見つけ出す(疵検出など)
顔認識:画像から顔を認識し、年齢や性別、同一人物かを判定する(入場ゲートなど)
類似画像検索:指定した画像に似た画像を検索する
これらのタスクのうち、類似画像検索はビジネスの現場、とくに製造業からのニーズが多い。ある程度は一般化されている技術であるが、ビジネス現場特有の考慮点も存在する。本稿ではいくつかの手法の解説に加えて、ビジネス現場特有の課題と解決策を記載する。
ここであらためて、類似画像検索が必要な事例を紹介しよう。
1つ目の事例として、部品を特定したい場合がある。自社やグループ会社、関連会社も含めると、数千から数万点以上の部品が存在することは多々ある。これには製品のタイプや製造年月で候補を絞り込んだり、熟練者が探すといった対応が一般的である。しかし数が多すぎたり、タイプで分けづらい場合には、満足に絞り込めず、特定に時間を要する。このようなケースでは、類似画像検索が解決策になる。
2つ目の事例は、異常判定の属人化を避ける場合である。製造業では見た目で異常を判定するケースがよく見られる。経験の豊富な人が見れば、その様子から異常の種類や原因がわかる。しかし経験が浅い場合は、異常であることを判定できたとしても、その種類や原因の推測までは難しい。そこで異常と判断された画像から過去の同じような異常を探せれば、属人化を避けられる。
3つ目の事例は、サービス提供の高速化である。近年は多品種少量生産が進み、すべての製品を管理するのが困難であるため、同じような製品が多く存在している。顧客から製品そのものや写真を提示されて、「これの、このあたりの形状がもっと大きいもの」という注文に対して、設計から始めて100%要件に合う製品を納品先に提供するまで1カ月かかるよりは、提供されたものの類似品を顧客に提示し、それを1週間で提供できたほうがいい場合もある。このようなケースでも、類似画像検索は解決策になりうる。
類似画像検索の3つの手法
メリットとデメリット
次に、類似画像検索の3つの手法について具体的に解説する。
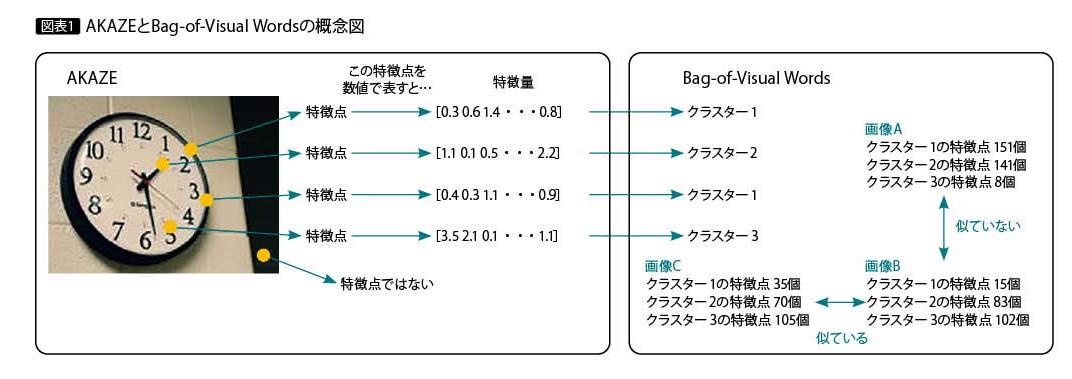
1つ目はAKAZEという手法である。AKAZEは特徴点およびその特徴量を抽出するアルゴリズムの1つで、本稿で紹介する手法では唯一、Deep Learningを利用していない。
Deep Learningを利用した手法と比較すると、拡大縮小や回転に強い、学習の必要がなくすぐに利用できるなどのメリットがある。またPythonのOpenCVに実装されている点や、AKAZE以前の特徴点・特徴量抽出アルゴリズムと違って無償で商用利用できる点など、使いやすさという面でのメリットも大きい。
ただしAKAZE自体は特徴点・特徴量を抽出するだけで、類似画像検索を実行する際は、特徴量の類似度を計算する必要がある。類似度の計算には、特徴点マッチングやBag-of-Visual Wordsなどの手法が使われる。Bag-of-Visual Wordsは特徴量をクラスタリングし、特徴点がいくつ、どのクラスターに分類されるかを求める。AKAZEとBag-of-Visual Wordsの概念を図表1に記載した。
2つ目の手法は、Deep Learningの学習済みモデルを用いた特徴抽出である。学習済みモデルは誰でも入手でき、そのまま利用すればトラなどの動物、扇風機などの物体といった判別が可能である。Deep Learningは入力データを何十もの層で順次処理し、「トラ」などの分類結果を出力するが、最終結果出力の手前の層の時点で、すでに似た者同士は近い出力結果になる(図表2)。
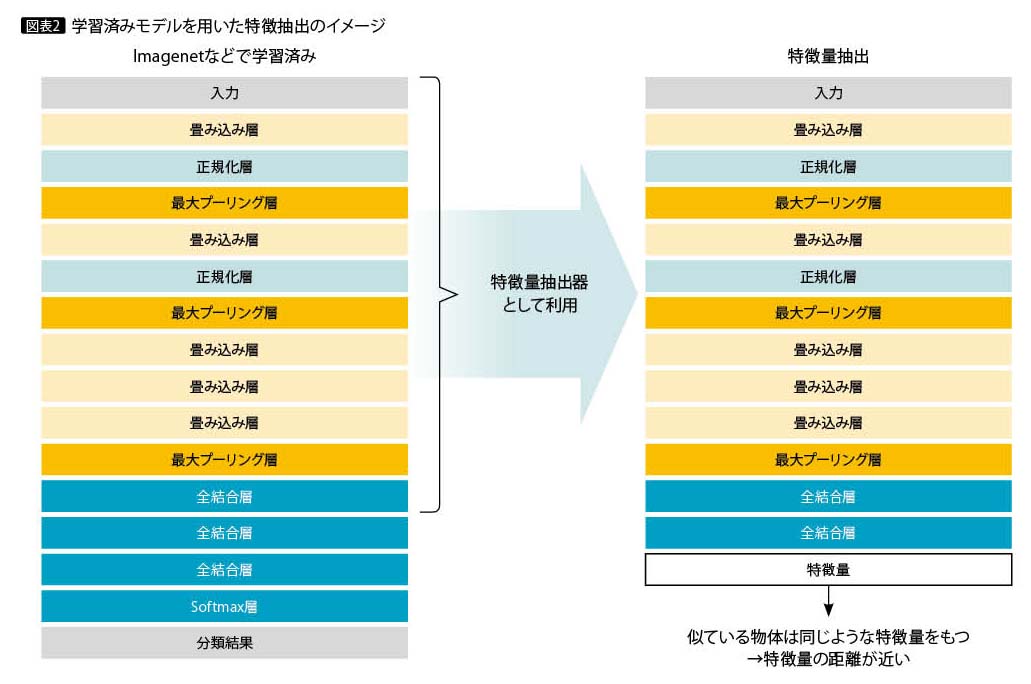
本手法では出力結果が近ければ近いほど、類似画像として扱う。AKAZEと同様、学習が不要なので、すぐに使えるというメリットがある。また得られる結果は、主観ではあるが、かなり人間に近い感覚で似ていると判断しているように見える。
一方で、どこに注目して似ていると判断したのかがわからないというデメリットがあり、実は人が注目するのとまったく別のところを見ている可能性もある。そして類似画像検索自体の難しさとして、「似ているか、似ていないか」が人の主観で判断される。そのため類似画像検索には正解がない。
一般的な利用ではそれでも問題ないかもしれないが、ビジネス利用では主観ではなく業務観点での類似が求められる。たとえば図表3の2つの時計は、主観的には「似ている」と言える。

しかし左は明らかに屋外に設置する時計であり、右は置き時計である。そのため業務的にこれらを「類似」とするのは、まったく検討違いの可能性がある。
そこで、このような業務的な都合を類似画像検索に取り入れる手法を3つ目の手法として紹介する。
この3つ目の手法は、「Triplet loss」と呼ばれる。Triplet lossは、「似ている」としたい画像間の特徴量同士の距離を近くし、「似ていない」としたい画像間の特徴量同士の距離は遠くなるように、ネットワークのパラメータを取得するために使用されるロス関数である。
つまり「画像Aは画像Bと似ているが、画像Cとは似ていない」としたい場合に、AとBを近づけるように、AとCを遠ざけるように学習する手法であり、常に3枚セットで行うため、名称に「Triplet」という単語を冠している。
この手法を適用することで、業務的な都合に合わせた類似画像検索が可能になる。ただし、かなりの数の学習が必要になる点がデメリットとなる。前述したとおり3枚セットで学習するので、そう定義する必要があるが、画像数が多くなると、その組み合わせは膨大である。もともとカテゴリごとに分かれたデータであれば、機械的に3枚セットを定義していけるが、そもそもカテゴリに分けられるのであれば、画像解析手法のみに頼るのではなく、カテゴリで絞り込めばよい。
そのため、まずはDeep Learningの学習済みモデルを用いた特徴抽出によってサービスを提供し、運用を通してTriplet lossにより業務に合わせたモデルに更新していくのが現実的な使い方であろう。
類似画像検索
精度向上のカギは背景除去
以上、類似画像検索の手法を3つ紹介したが、とくにDeep Learningを用いて類似画像検索を利用する際の注意点が1つある。背景の除去である。以下の例を見てみよう。
図表4は、学習済みモデルを用いた特徴抽出による類似画像検索の結果である。

一見すると、それなりに正確な検索であるように見える。しかし、「赤」という色に注目してみると、背景色に引きずられているのでは、という懸念が出てくる。
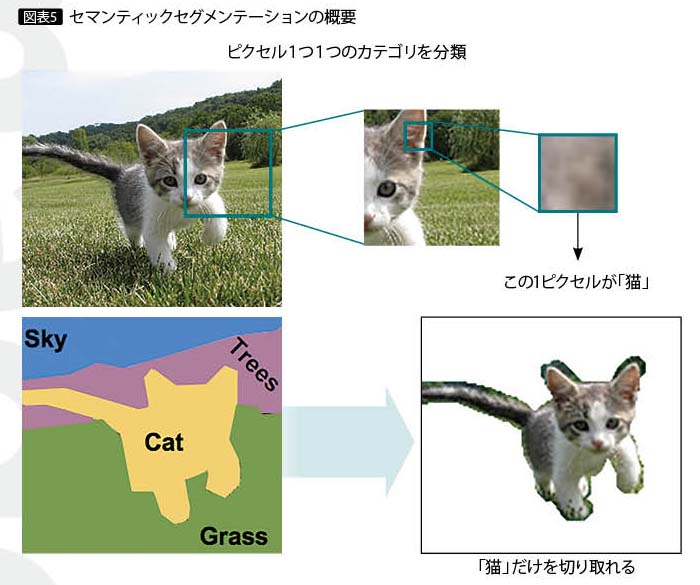
そのため、より精度を向上させるには、背景を除去したほうがよいと考えられる。背景の除去では、従来からある画像処理で輪郭抽出する手法も考えられるが、さまざまなバリエーションがある場合は、物体そのものをDeep Learningで学習させるのがよい。このときに使える手法が、「セマンティックセグメンテーション」である。セマンティックセグメンテーションでは図表5のとおり、1ピクセル単位で判定することで、必要な部分だけを切り取る。
もちろん学習が必要で、その学習では対象物をアノテーションする(この場合はツールを用いて対象物を塗りつぶす)必要があるので、地道な作業が求められる。しかし利用時にはモデルを通すだけで背景を除去できるので、対象物のバリエーションが多く、画像処理だけでは除去が難しい場合に有用である。セマンティックセグメンテーションにより背景除去して類似画像検索を行った結果が、図表6である。

背景除去を行った結果、「赤」に引きずられることがなくなり、より近いものを検索できるようになる。一部の画像でセマンティックセグメンテーションによる背景除去がうまくいっていないが、これはさらに多くの画像を準備し学習することで改善される。
以上、類似画像検索のための3つの手法と精度向上のテクニックを紹介した。まずはAKAZEとDeep Learningの学習済みモデルを用いた特徴抽出により、それぞれがどの程度、業務要件に合致した検索ができるかを試してみよう。そして背景が邪魔しているのであれば、セマンティックセグメンテーションによる背景除去を考える。トライアル期間や実運用など、人の判定結果を取り入れる場合は、Triplet lossによる学習を組み込めば理想である。
またすべてを類似画像検索のみに頼るのではなく、可能な限りカテゴリなどのロジックで絞り込む仕組みを組み合わせれば、類似画像検索の精度をかなり安定させられる。
ビジネス変革に向けたソリューションの1つとして、本稿が類似画像検索の参考になれば幸いである。
著者|
野口 洋平氏
日本アイ・ビー・エム システムズ・エンジニアリング株式会社
先進AIテクノロジー
シニアITスペシャリスト
先進AIテクノロジー
シニアITスペシャリスト
2002年に日本IBM入社。2009年より日本アイ・ビー・エム システムズ・エンジニアリングへ出向し、主にレプリケーションやフェデレーションなどのデータ統合製品を担当。現在は画像解析案件やSPSSを活用したデータ分析案件を手がけている。

[IS magazine No.27(2020年5月)掲載]