画像を規則性に従って計算し、何であるかを判別する「特徴量」に変換
佐藤 大輔
日本アイ・ビー・エム
システムズ・エンジニアリング株式会社
ワトソン・ソリューション
シニアITスペシャリスト
なぜ画像解析が注目されているのか
なぜ今、画像解析が注目されているのか。
画像解析で必ずと言っていいほど話題になるのは、ILSVRC(ImageNet Large Scale Visual Recognition Challenge)という画像解析のコンテストで、2012年にディープラーニングを用いた機械学習モデルがほかのモデルにエラー率10%以上の差をつけて圧勝した、という出来事である。
これによって研究者たちがディープラーニングの可能性に気づき始め、さまざまな研究が進められてきた。同じく2012年にはディープラーニングにより、「コンピュータが、教えられなくても猫を判別できるようになった」と、Googleが発表した(図表1)。これもまた、ディープラーニングと画像解析に注目が集まった大きなトピックスであった。
【図表1】Googleによって学習された猫の特徴

https://googleblog.blogspot.jp/2012/06/using-large-scale-brain-simulations-for.html
それから5年。多くの研究が重ねられ、より使いやすいように工夫を凝らした結果、ディープラーニングを使って画像解析が簡単に実行できるように、多彩なライブラリやツールが生み出されてきた。
また、さまざまな画像解析のサービスやAPIも提供され、今や画像解析やディープラーニングは一部の研究者だけのものではなく、一般のユーザーも手軽に扱える技術となっている。
画像解析とは、そもそも何なのか
そもそも画像解析とは、何をするものだろうか。
画像解析とは画像を解析し、そこに写っているものの意味を理解することである。意味を理解するときの観点によって、さらに細かく分類される。その代表例に、「分類(Classification)」(または「認識(Recognition)」)と「検出(Detection)」の2種類がある(図表2)。
【図表2】画像解析の種類

● 「分類」:何が写っているかを理解する
画像に写っているのが何なのかを当てるのが、「分類」である。たとえば、「車」「人間」などを見分けることだ。「分類」にはさらに、「物体分類」と「シーン認識」がある。
物体分類は、前述の「車」や「人間」のように、写っている物体が何であるかを答えることである(図表3)。
【図表3】物体分類の例:1つの対象物として何が写っているか(この場合は「車」)を分類する

これに対してシーン認識は、景色の認識である。画像内のある物体に注目するのではなく、全体としてどんな景色であるかを答えるタイプの分類である(厳密にはシーン認識は景色に限らない)。たとえば、車や人間に加えてビルがそびえ立っているような画像を見て、「車」と答えずに、「街」「都市」と答えるタイプの分類が、シーン認識である(図表4)。
【図表4】シーン認識の例:車も写っているが、写真全体を見て「街」と認識する

● 「検出」:どこに写っているかを理解する
「検出」は、「何が」だけでなく、「どこに」写っているか、までを当てるものである。よくある例は「顔検出」で、デジタルカメラなどで写真を撮る際に、顔が四角い枠で囲われることがあるだろう(図表5)。このように、「どこに」「何が」あるのかを答えるのが検出である。
【図表5】顔検出の例:「顔」がどこにあるかを検出している

検出にはさらに、「物体の検出」と「領域(セグメンテーション)の検出」がある。物体の検出は、前述の顔検出のように、「写っている物体が何であるか」と「その位置」を当てる(図表6)。たとえばタブレットで商品棚を写すと、どこに何の商品があるか検出して表示する、あるいは防犯カメラの映像をサーチして怪しい人物として登録された人間がどこに写っていたかを検出する、などの使用例がある。
【図表6】物体検出の例:写っている物体と位置を検出している

これに対して領域の検出とは、画像のなかで同じものを表す領域の境界線を見つけることである(図表7)。たとえば塗り絵で、境界線を引くことを考えてみよう。写真にトレーシングペーパーを重ねて、下絵のうち同じものを表す領域は同じ色で塗る。
【図表7】領域検出の例
http://jamie.shotton.org/work/research.html

それと同じことを行うのが領域の検出である。この技術は自動運転の分野でよく使われており、走行ルート決定のための材料として道、空、壁、歩行者、他の車などをエリア分けするのに使われている。
画像の規則性(特徴量)の発見
それでは、画像解析の基本的な部分である分類の考え方について少し掘り下げてみよう。
画像に何が写っているかをコンピュータが分類するには、まず分類対象を知る必要がある。さらに、分類対象の間の違いを知る必要がある。
イメージを掴むために、人間と車の写真を分類する作業について考えてみよう。ただし前提として、あなたは人間や車というものを知らないとする。仕分けの参考に2つのグループに分けられた複数の写真を渡されたとしたら、それらを眺め、どういう場合にどちらのグループであるか、その規則性を探そうとするだろう(図表8)。
【図表8】写真から違いを学習する
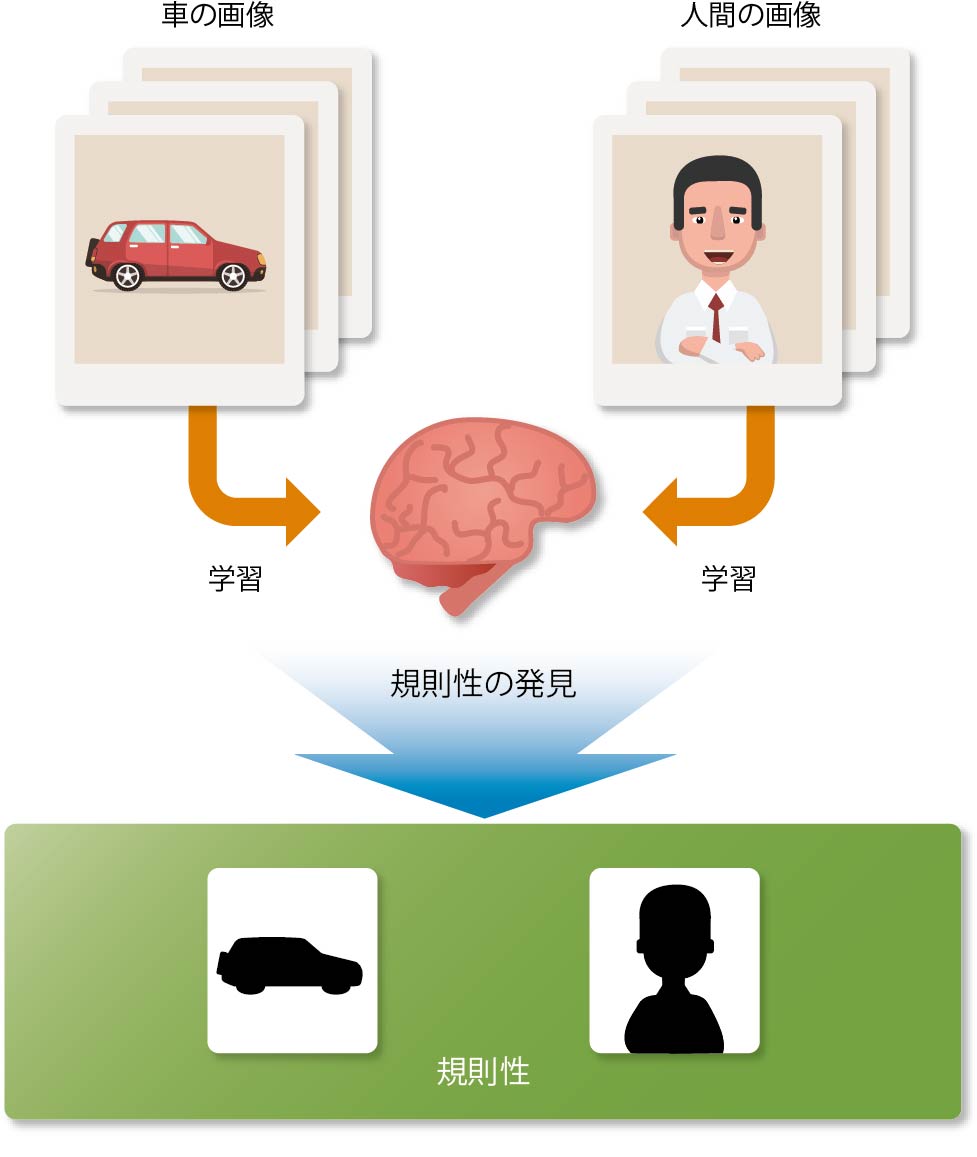
コンピュータによる画像解析の場合も同様に、大量の画像データから分類したいものの共通点や差異、すなわち規則性を探していく。ひとたび規則性が発見できれば、あとは新しい画像を分類するときに、その規則に従って分類していけばよい(図表9)。
【図表9】見つけた規則に従って分類する
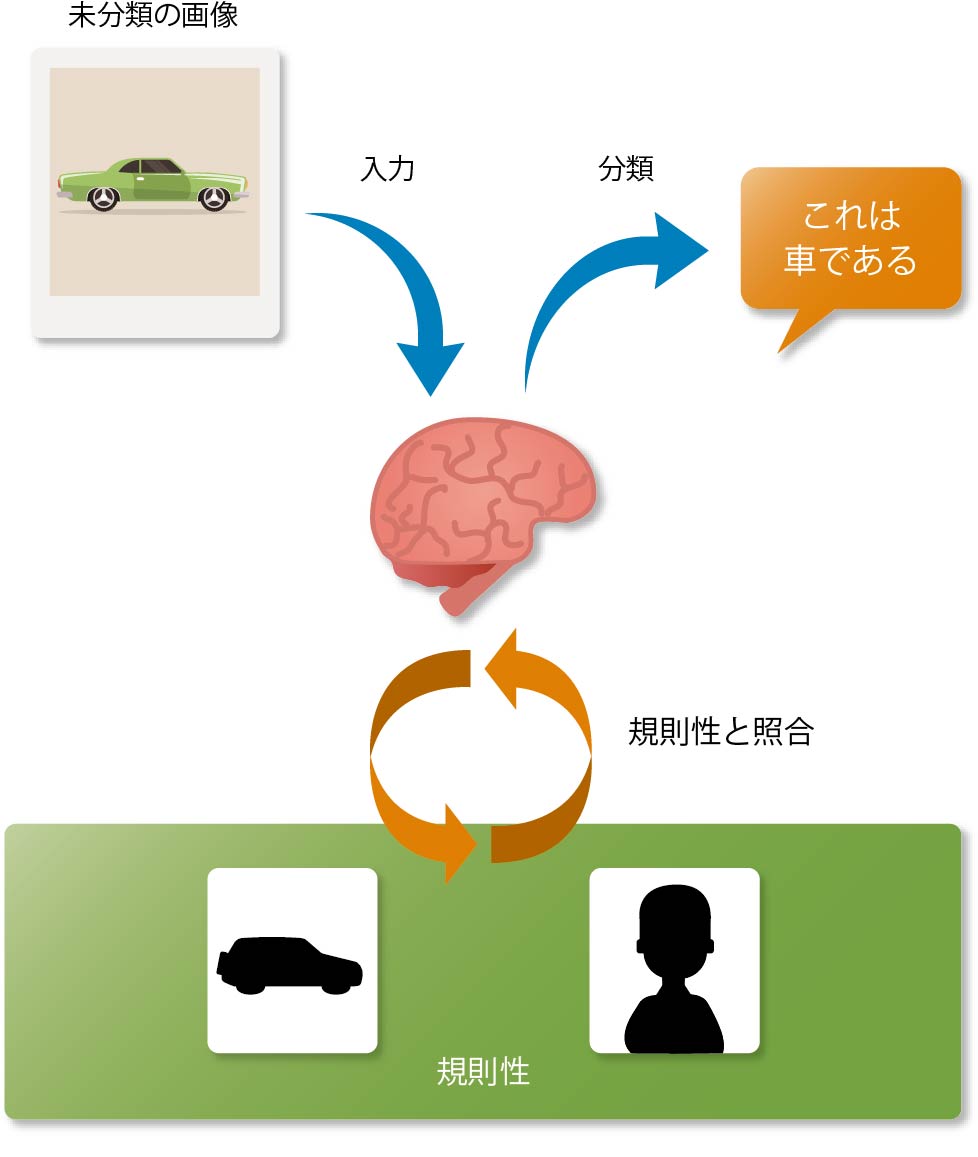
この分類に使った規則性のことを、機械学習の用語では「特徴量」と呼ぶ。あまり聞き慣れない言葉であるが、簡単に言えば、「見分けるための規則性=特徴」を数値化したものである。そして、いったん特徴量が定まってしまえば、あとはその特徴量を使って計算するだけでよい。
ディープラーニングは
特徴量をより簡単に発見するための秘密兵器
では、この特徴量をどうやって発見すればよいだろうか。
特徴量を発見する際に大きな力を発揮するのが、ディープラーニング(深層学習)である。ディープラーニングとは学習方法の一種で、ニューラルネットワーク(NN)の層(レイヤー)と呼ばれるものを、何重にも深く(ディープに)した「ディープニューラルネットワーク」(DNN、図表10)と呼ばれるモデルの学習に使われる(ときどきDNNとディープラーニングを混同して使っているケースもあるので注意が必要である)。
【図表10】ニューラルネットワークとディープニューラルネットワーク
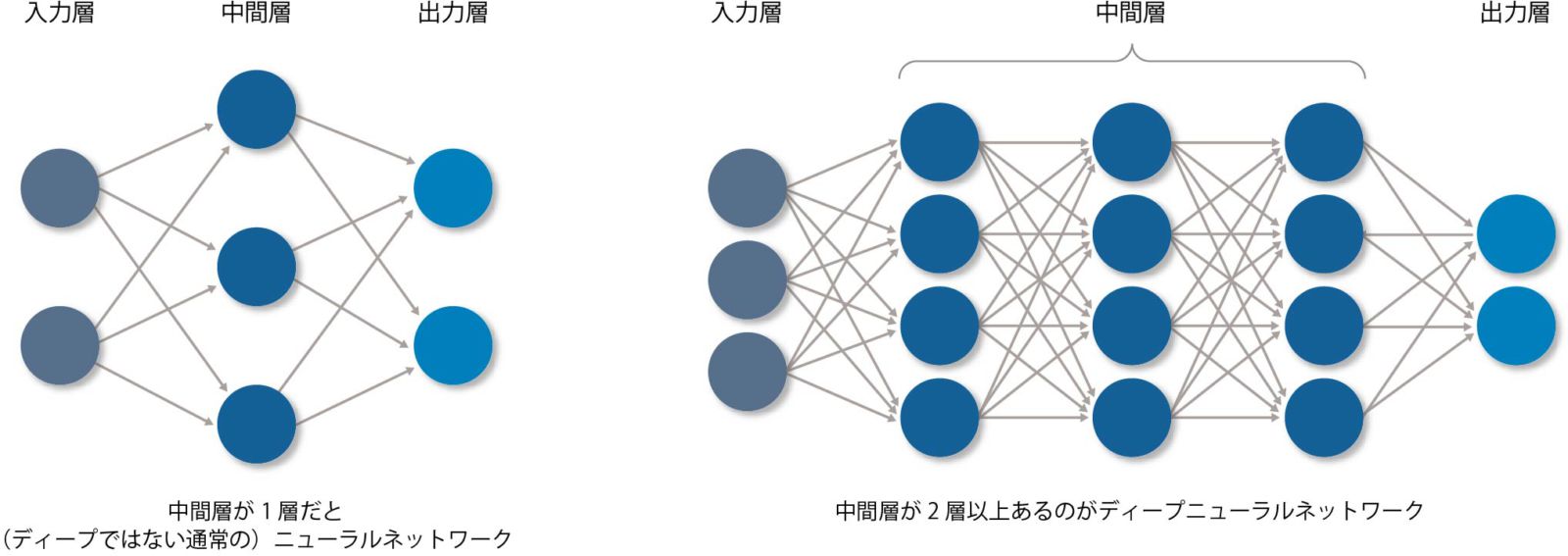
ディープラーニングを使用して大量の画像データを学習することにより、従来の機械学習に比べて特徴量の獲得がより簡単になる。
「別にそんなことをしなくても、人間と車を見分けるのは簡単。手足のあるのが人間で、タイヤのあるのが車だ」と思う人がいるかもしれない。確かに、分類のための共通点や差異がはっきりと言語化でき、またそれをコンピュータのロジックで書きやすく記述できるのであれば、ディープラーニングに頼らなくてもよいだろう。
しかし画像の分析では、たとえ言語化できたとしても、それをロジックとして記述するのは大変である。たとえば車の場合で考えると、「タイヤが付いていれば車。タイヤというのは、車体が地面と接する部分にある黒くて丸い物体のこと。車体というのは……。地面というのは……。接するというのは……。丸いというのは……」など、説明に説明を重ねる必要があり、無限ループになってしまうかもしれない。
ディープラーニングはそれぞれの違いを言語化して表現するのではなく、画像としての特徴で違いを表現する。それは形かもしれないし、色かもしれない。もしかしたら、私たちでは考えられないような特徴を見つけるかもしれない。しかもそれを数値データで表現して、コンピュータにとって扱いやすいようにしているのである。
ディープラーニングの学習の進め方は
私たちの勉強方法と同じ
ディープラーニングであっても、学習の進め方の本質はほかの機械学習と変わらない。
まず仮説としてのDNNを作成する。学習用の大量の画像データ(正解がわかっているもの)をDNNにかけて計算し、得られた結果と正解を比べる。その間に乖離(=誤差)がある場合は、誤差が減るように特徴量の計算式のパラメータを修正する。
これを何度か繰り返して、誤差にほとんど変化が見られなくなったところで学習を完了させる(図表11)。
【図表11】学習の進め方
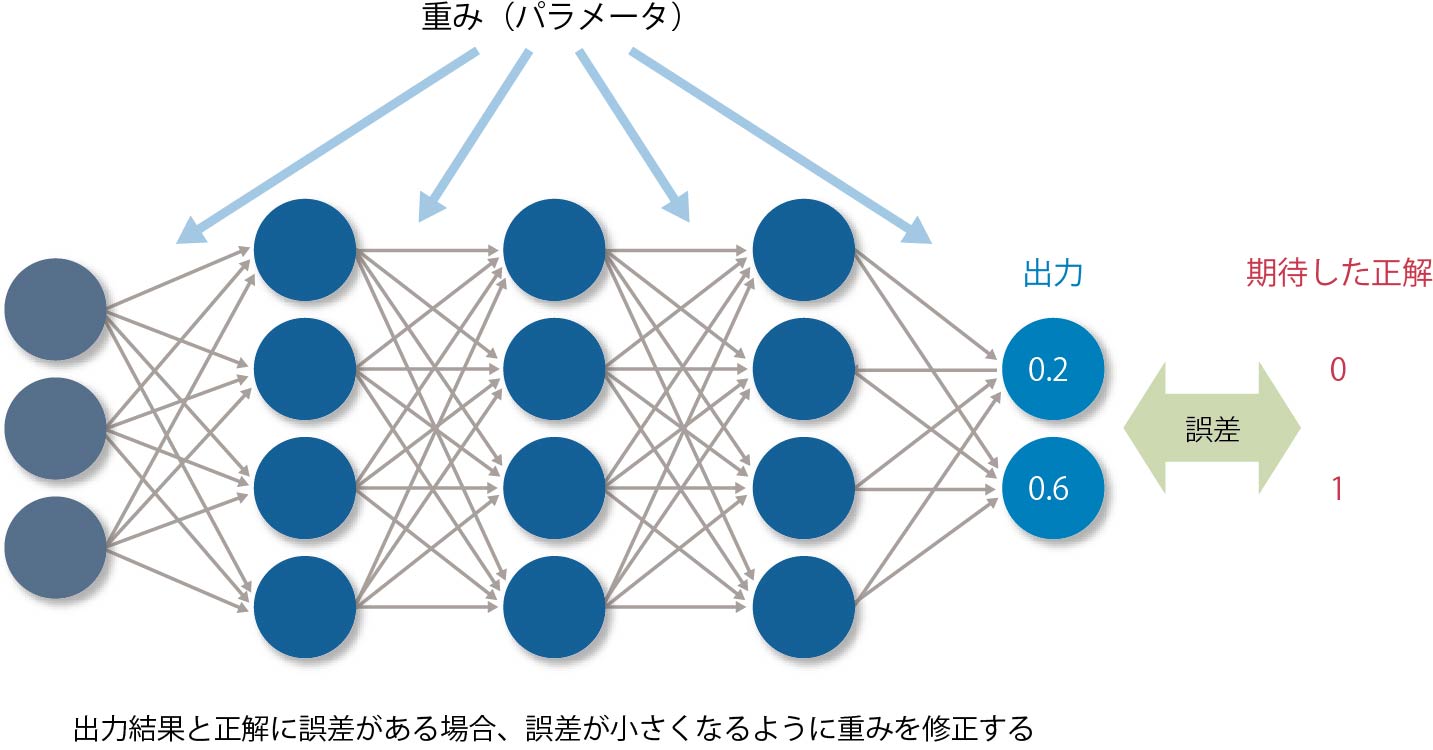
よくイメージできないのであれば、勉強するときのことを考えてみよう。問題集を解いて答え合わせをし、間違ったところを直しては解き直し、間違いがなくなるまで何度も繰り返す。機械学習は、それと同じことをやっているのである。
誤差からパラメータを修正するにはさまざまな方法があり、ディープラーニングの場合によく使われるものに「誤差逆伝播」があるが、誌面の関係もあり本稿では割愛する。
特徴量は聞き慣れない言葉なので、機械学習やディープラーニングの説明はわかりづらく感じられるかもしれない。まずはむずかしいことは考えずに、「入力画像を規則性に従って計算すると、それが何であるかを判別可能なデータ(=特徴量)に変換できる」ということ、そして「その規則(=特徴量)は、ディープラーニングによって学習することで得られる」とわかれば、ファーストステップとしては十分である。
脚光を浴びる
「畳み込みニューラルネットワーク」
「畳み込みニューラルネットワーク」(Convolutional Neural Network:CNN)は、ILSVRC 2012で優勝したチームが使用して一躍脚光を浴びた。
CNNの特徴は、ニューラルネットワークの層を「畳み込み層」と「プーリング層」という2種類の層に分けて定義し、それぞれの層で異なる操作を実行する点である(図表12)。
【図表12】畳み込みニューラルネットワークの例
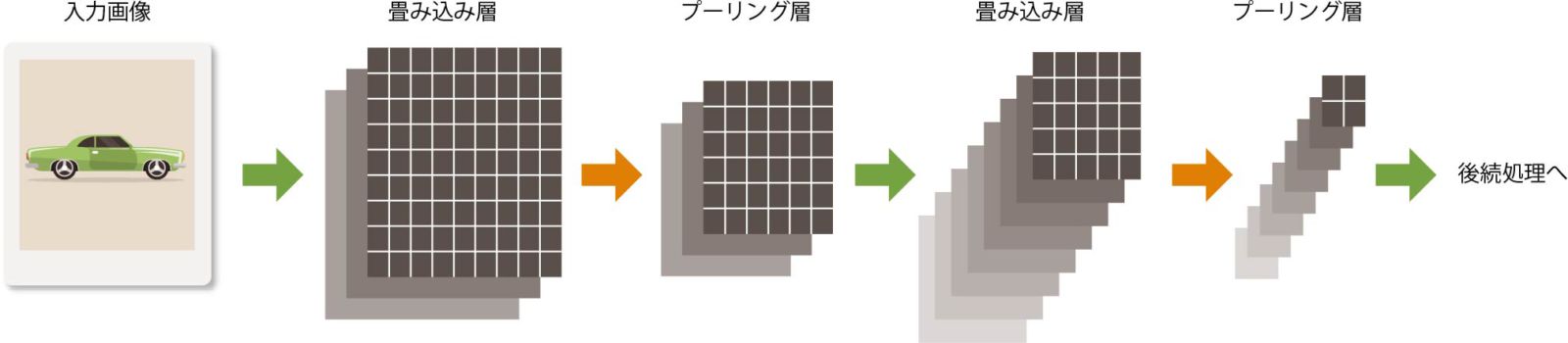
畳み込み層では、さまざまなフィルタと特徴量を使った計算により、何パターンかの新しい画像データを作り出す。これに対してプーリング層では、簡単に言えば、画像の解像度を下げて抽象化した画像データを作り出す。
そして、また畳み込み層の処理を実行し……と繰り返していくことで、元画像は特徴を残したままデータ量が少なくなり、最終的に何の画像なのかを分類できるようになる(CNNについては、IS magazine No.13の技術連載「ディープラーニング入門」第2回に詳しいので、参照されたい)。
ディープラーニングを知らなくても
画像解析に挑戦できる
「ディープラーニングって、何だかむずかしそうだ。これを理解しないと、画像解析はできないのか」と思う人がいるかもしれないが、心配はいらない。
画像解析のAPIや多彩なツール/ソリューションの利用によって、ディープラーニングの複雑な内部処理を意識することなく、手軽に解析できる時代が来ている。
たとえば、Watson APIの1つである「Visual Recognition」を使うと、学習用の画像を用意するだけで、物体分類のためのモデルを学習させることが可能である。
そのほかにも、GUIを使って簡単にネットワーク設定、学習、テストを実行できるツールなどもあり、手軽に画像解析を始められる。もちろんネットワークを自分で作りたいという場合は、ディープラーニングのライブラリを使ってモデルを自作し、学習することも可能である。
*
以上本稿では、画像解析のエッセンスをなるべくわかりやすく解説した。もっと詳しい情報を知りたいなら、さまざまな専門書、参考書、解説サイトがあるので、チャレンジしてほしい。さらなるディープな世界が待っていることだろう。
・・・・・・・・
著者プロフィール
佐藤 大輔 氏
2003年、日本アイ・ビー・エム システムズ・エンジニアリングに入社。以来、メインフレームのトランザクション製品のエンジニアとして主に金融系システムを担当。2015年、Watsonの日本展開と時を同じくしてWatsonの技術支援を開始。Watson APIやWatson Explorerを利用するプロジェクトでシステムの設計・開発を担当する。
・・・・・・・・
IS magazine No.17(2017年9月)掲載







