2016年7月にWatson APIの中核とされる「Conversation」*1が公開されてから、これまでに数多くの案件が生まれきた。公開からしばらくは、PoC(Proof of Concept:概念実証)の一環としてのデモ開発が多かったが、最近は本番導入を前提とした案件も増えつつある。今後は本番導入へ向けた取り組みや、本番環境における活用の内容が重要になる。
筆者は、これまでにConversationの案件を多数経験し、その試行錯誤をとおして、Conversationを本番導入する際のポイントや注意点について知見を蓄えてきた。本番環境では、PoCでは見落とされがちな重要な問題がさまざまある。本稿では、Conversationの本番導入で留意すべきポイントを紹介する。
*1:2018年3月に「IBM Watson Assistant」に改称されたが、本稿では馴染みのある「Conversation」を使用する。
インテントとエンティティ
最初に、本稿の説明に必要な「インテント(Intent)」と「エンティティ(Entity)」について紹介したい。
インテントとは、入力されたテキストがどのような意図をもつのか、カテゴリー分けするための概念である(一般的な機械学習用語の「クラス」に相当する)。一方、エンティティは、入力されたテキストに含まれる言葉を、事前に定義されたキーワードにカテゴリー分けするための概念だ。そしてConversationのDialogでは、インテントとエンティティの組み合わせによってメッセージを設定することができる。
たとえば、インテントに「#年間購読料」、インテントの例文として「年間購読料を教えて下さい」、エンティティに「@magazine」、エンティティのvalueとして「IS magazine」「i Magazine」を用意したとする。
この条件で、ユーザーが「IS magazineの年間購読料を教えて下さい」と入力すると、インテントとしては「#年間購読料」、エンティティは「@magazine:IS maga
zine」が検知される。そしてDialogには、インテントが「#年間購読料」で、かつエンティティが「@magazine:IS magazine」であれば、「IS magazineの年間購読料は1万9440円です。」という応答メッセージを表示するように設定する。
同様の条件で、ユーザーが「年間購読料について教えて下さい」という入力を行った場合は、インテントとしては「#年間購読料」が出力されるが、エンティティは検知されない。そこでDialogには、インテントが「#年間購読料」で、かつエンティティが検知されないときは、応答メッセージに「アイマガジン株式会社が販売する雑誌には、IS magazineとi Magazineがあります。どちらを確認したいですか?」という選択肢を提示し、ユーザーによる選択後に、雑誌の購読料を表示する設定を行う。
このようにConversationではインテントとエンティティの組み合わせによって、ユーザーが求めるさまざまな応答を設定することが可能である。
対話フロー設計のパターン
対話フローの実装方法は、無数に存在するように思えるが、3つパターンの組み合わせで実装が可能である。
1つ目のパターンは図表1の「一問一答型」で、問いと答えが一対となった最も基本的な会話パターンである。このパターンであれば、対話フローを階層的にしなくても、問いと答えの繰り返しで一連の会話を実装できる。

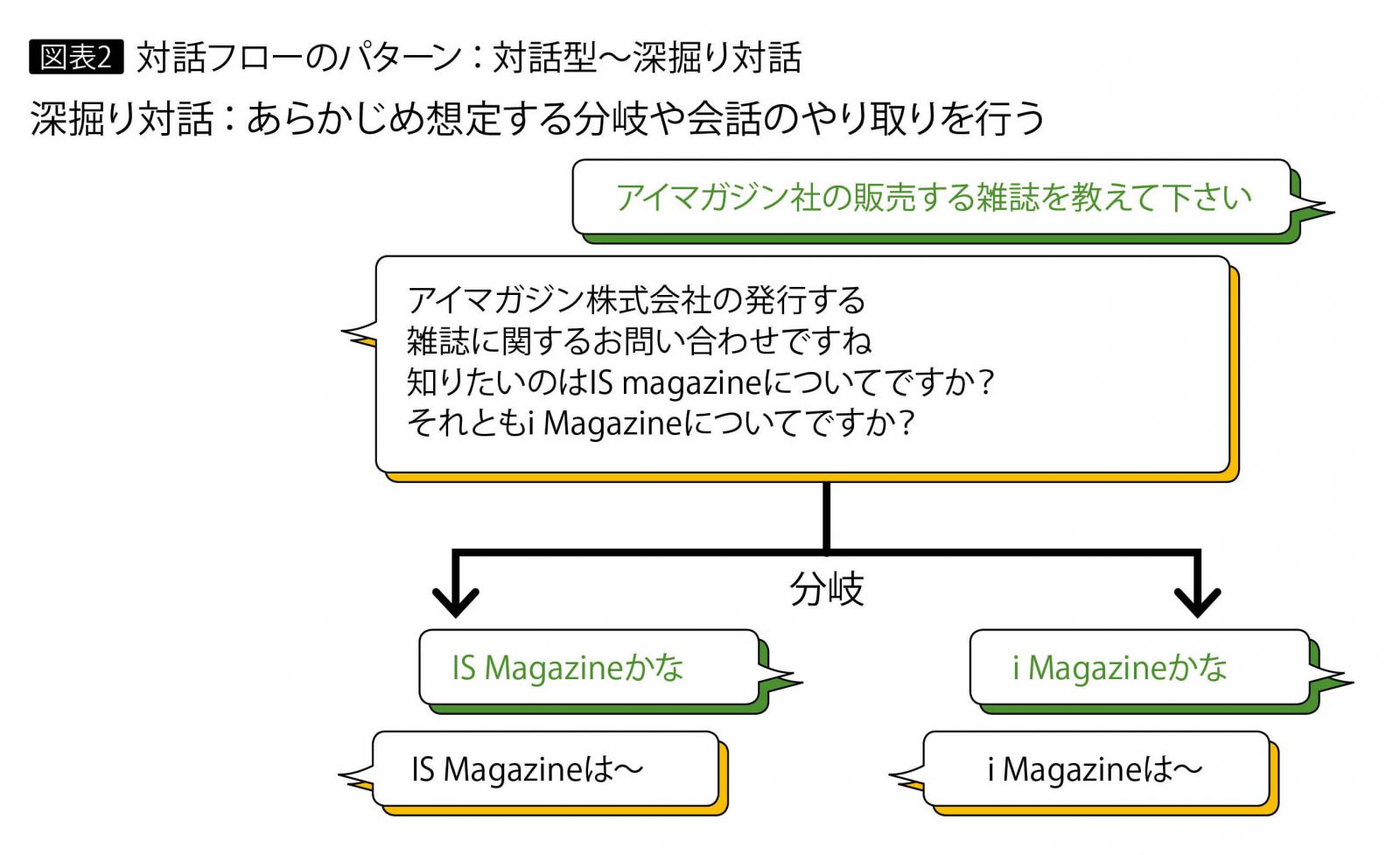
2つ目は図表2の「対話型」で、会話に複数の分岐が存在する。このパターン(「深掘り対話」)では、対話のトリガーとなるインテントを検知すると、応答メッセージで分岐の数だけ選択肢を提示する。そして質問者が選択肢の表現に近いインテントを入力すると、それに応じたメッセージが返される。
3つ目の「インテント × エンティティ」は、トリガーとなるインテントと、回答を絞り込むためのエンティティが入力されると、回答が行われるというパターンである。ただし入力がインテントのみの場合は、分岐の数だけ選択肢を提示し、次に選択肢と一致するエンティティが入力されると、それに応じた回答が行われる(図表3)。
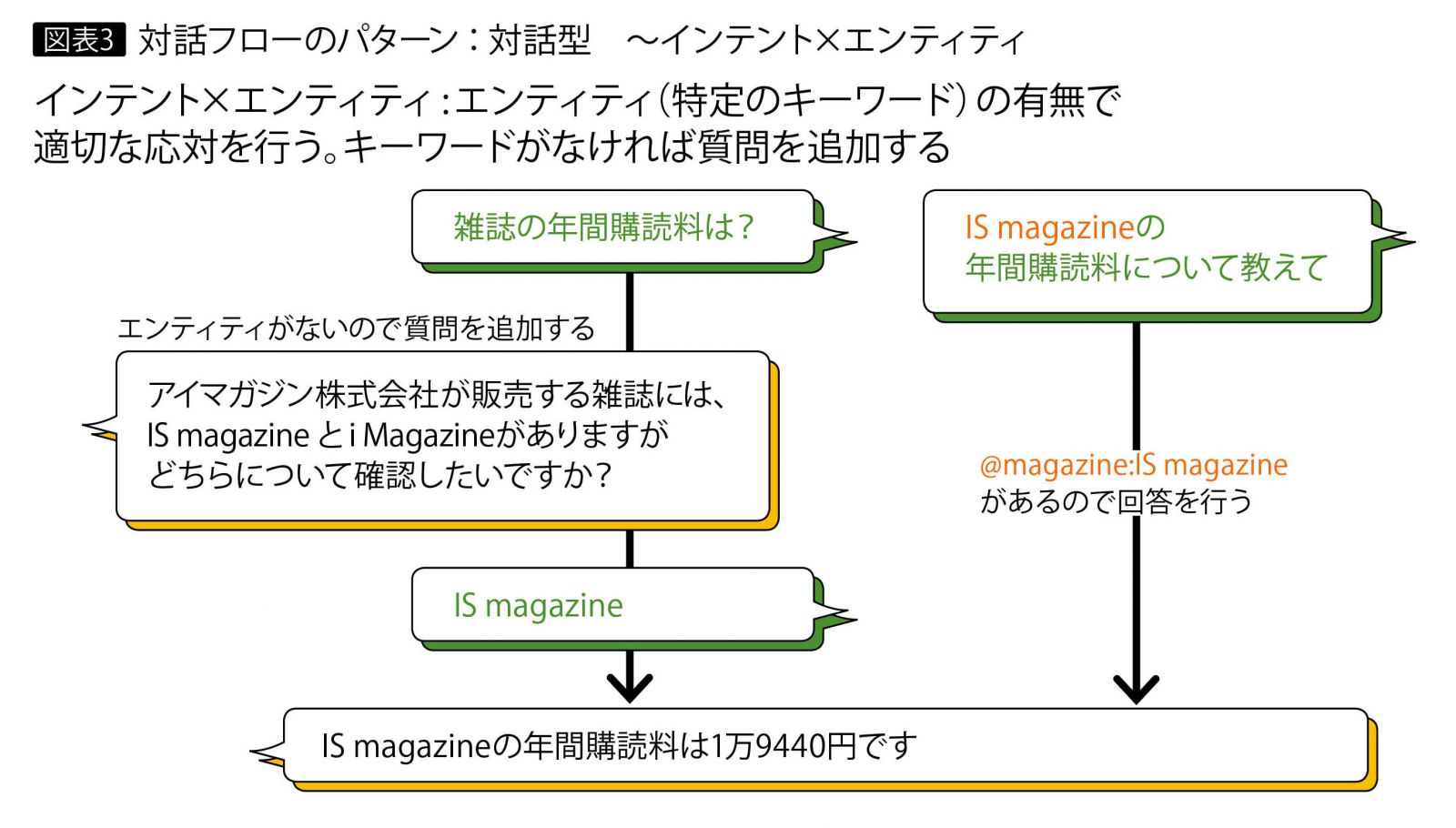
2つ目のパターンの対話型では、選択肢でインテントを判別するので曖昧な表現でも選択できるが、選択するという手間が避けられない。3つ目のインテント × エンティティでは、条件がそろえば回答されるのでのでエンドユーザーの煩わしさは軽減されるが、選択肢をキーワードで判別する必要がある。
回答の入力方法
本番環境で、Conversationのインテント数が数百になることはよくある。そうした場合、Dialog上で応答メッセージごとにノードを作成すると、数百ノードを管理する必要が生じる。そこで、1つのノードに複数の応答メッセージを入力するための1つの方法を紹介したい。
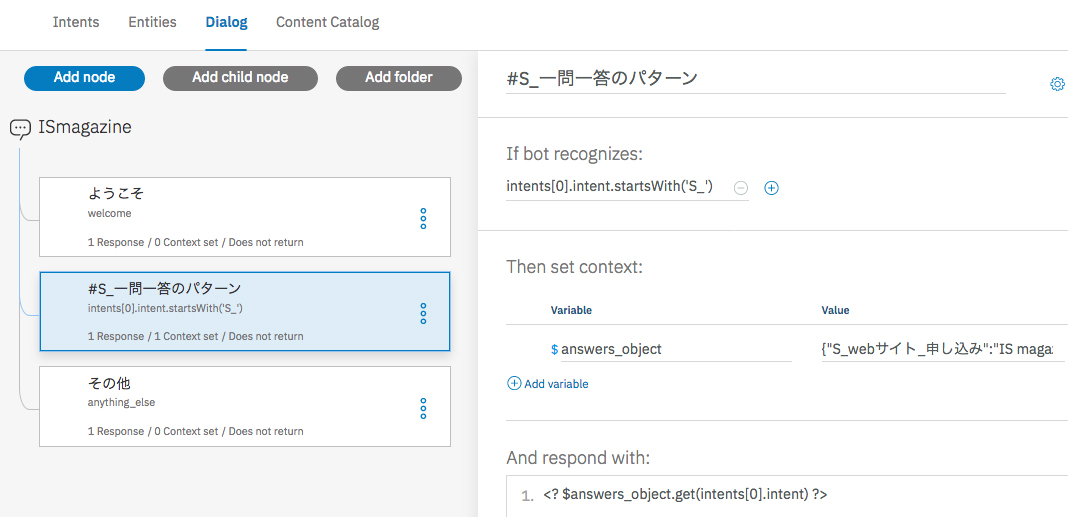
最初に、一問一答で回答するべきインテントの接頭語に「S_」を付けて命名規則を統一する。If bot recognizesで、「intents[0].intent.startsWith(’S_’)」とすると、Conversationのclassifierの確信度がもっとも高いインテントの名前に接頭語に「S_」がついていれば、trueとなる(図表4)。
[図表4]インテントの接頭語に「S_」を付けて命名規則を統一
次に、Open JSON editorを選択して、”answers_object”というふうに、図表5のような応答メッセージ用のコンテキスト変数を作成する。
[図表5]応答メッセージ用のコンテキスト変数を作成する
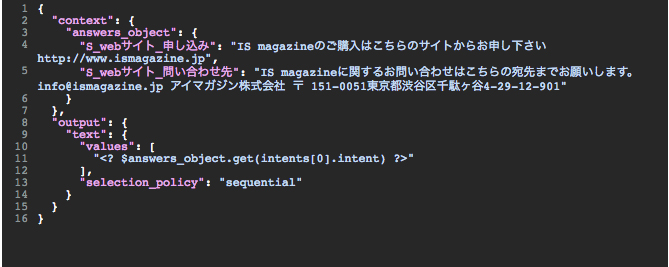
Then respond withを、<? $answers_object.get(intents[0].intent) ?>とすると、コンテキスト変数である”answers_object”のclassifierの確信度が最も高いインテント用の応答メッセージが出力されるようになる。これで応答メッセージごとにノードを作成しなくても、応答メッセージを切り替えられるようになり、ノードの管理が容易になる。
インテントの命名規則
PoCのデモ開発ではインテント数が数十程度なので命名規則に神経質になる必要はないが、本番環境では数百に上るケースもあり、インテント管理を念頭においた命名規則が重要になる(システム上は、一対の問いと答えを1レコードとして、20000レコードまで学習可能)。
後あとのインテント管理を容易にする命名規則は、類似の業務などでインテントのグループを作成し、「#□□業務_◯◯処理_△△操作」といった3階層程度で命名することである。さらに、Dialog上のどのノードで応答メッセージを返すかの管理を行うときは、「#S_一問一答_□□業務_◯◯処理_△△操作」のように接頭語を付けるとよい。
コメントの入れ方
プログラミングを行った際、コードをリーダブルにするためにコメントを記述するが、Conversationでも同様に、第三者から見てわかりづらい対話フローだろうと思える実装を行った場合は、チームメンバーで状況を共有するためにコメントが必要である。
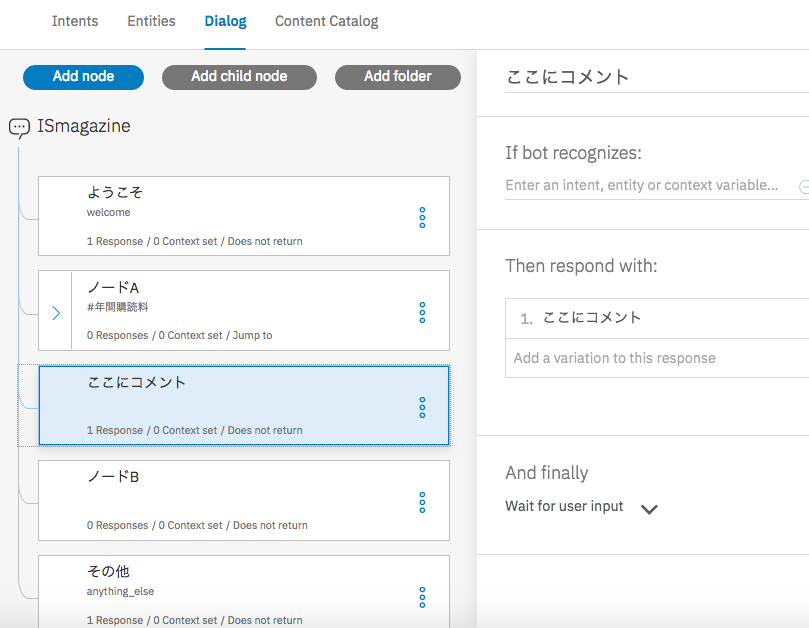
Conversation GUIのDialogにはコメントを記述する機能はないが、図表6のようにコメント用のノードを作成するとよい。ノードの判別条件であるIf bot recognizesにfalseを入れておけば問題はない。注意すべきは、同じ親をもつ並列なノードは、エクスポート/インポートを行うと順番が入れ替わる恐れがあることである。図表7のようにすると、ノードAとノードBとコメントの順序が入れ替わるおそれがある。順序が入れ替わらないように親子関係を意識することと、ノードの遷移をjump toで明示的に指定することがポイントである。
[図表6]コメント用ノードの作成
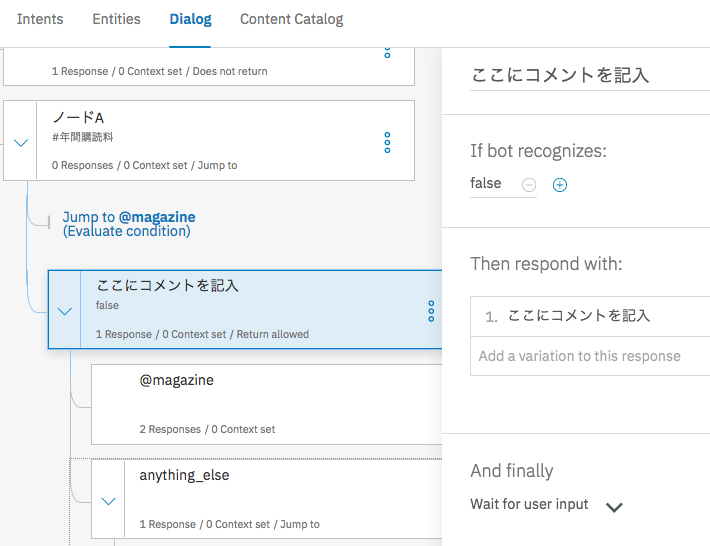
[図表7]親子関係を念頭に入れ、コメント用ノードを配置する
早い段階で実際のユーザーに使ってもらう
Conversationの導入計画を立てる際、Conversationをしっかりと学習させて正答率を上げてから、段階的に部門やユーザー数を増やしていこうと考えるだろう。しかしConversationは、できるだけ早い段階で利用を想定するユーザーに使用してもらうべきである。理由は2つある。
1つは、Conversationのインテントにおける例文は、ユーザーが実際に入力するであろう文章やフレーズを含んでいる必要があるからである。ユーザーが業界用語を用いて問い合わせをするなら、業界用語を用いた例文をConversationのインテントに学習させる必要がある。ユーザーが一般的な用語も使うなら、一般用語にも対応する必要がある。つまり、逆を言えば、想定するユーザーと属性が異なる人間がいくらConversationを学習させても、本番で的確な答えを返せないおそれがあるということである。それゆえ、できるだけ早い段階で想定するユーザーに使ってもらうべきなのである。
とはいえ、一般のユーザー(消費者)へConversationを提供する場合は、正答率が低いものをいきなり公開することはできない。そこは、モニターなどを募って正答率が80%を超えるまで試行を繰り返すなど慎重な手続きが必要になるが、大事なことは想定するユーザーを常に意識し、どこから手を付けるかを見積もることである。開発側の考えや思惑だけでユーザーを広げるようなことは厳禁である。
もう1つは、データ収集の観点からである。Conversationに学習やテストをさせるために一定量以上のデータが必要になるが、それを開発メンバーだけで用意するのは、量的にも質的・バリエーション的にも限度がある。そこで、エンドユーザーに実際に使ってもらいながらデータを集めるのである。
UIを統一する
前項で、Conversationのインテントにおける例文は、ユーザーが実際に使用するであろう文章やフレーズを使って学習させる必要があることを説明した。そのユーザーのログでデータを収集する際に、気をつけるべきポイントが2つある。
1つ目は、ユーザーの属性によって業界用語や一般用語などが異なること、2つ目は、UIによって入力される内容が変化することである。
たとえばLINEのようなインターフェースの場合は、入力されるテキストは極端に短くなる傾向がある。また、テキスト入力がボタン化されていると、言葉のゆらぎへの対応が不要になる。UIの違いによって収集されるデータが大きく変わることに注意しなければならない。
従来の開発では、アプリを作りながら画面の要件をまとめていき、プロジェクトの後半でUIを作り込むことが多かった。しかし、ユーザーが使用する文章やフレーズを効果的に収集するならば、できる限り早い段階で統一的なUIの実装をお勧めする。
著者|張 貴光氏
日本アイ・ビー・エム システムズ・エンジニアリング株式会社
ワトソンソリューション
ITスペシャリスト

2015年4月、日本IBMへ入社。SoftlayerやBlue Boxのテクニカルセールスとして、クラウドのインフラ構築の技術支援に携わる。2017年1月にISEへ出向。Watson製品を中心としたコグニティブ・ソリューションのプロジェクト参画、セミナー講師、アセット開発などに従事。
[IS magazine No.19(2018年4月)掲載]