Text=細野 友基 日本IBM
昨今、データの種類は構造化・半構造化データだけでなく、ドキュメント、画像、音声、動画など多岐にわたっている。また、活用においても生成系AIに代表されるように、進化を続けている。
このようなデータ種類の多様化・データ量の増加・データ活用の進化に伴い、長らくデータレイク(以下、DL)・データウェアハウス(以下、DWH)の2層アーキテクチャに頼ってきたデータ基盤も、徐々に課題を抱えるようになってきた。
これら解決のため、レイクハウス(以下、LH)アーキテクチャが提唱されている。watsonx.dataはLHアーキテクチャを採用しており、現代のデータ基盤が抱える課題を解決できるソリューションとなっている。その一端を今回、ハンズオンも含めてご紹介する。
LH/watsonx.dataとは
LHアーキテクチャとは、一言で表すとDWHのもつデータの信頼性や性能といったメリットをDLにもたらした次世代アーキテクチャである。従来の2層データアーキテクチャでは不可欠であった、DLからDWHにデータをロード・変換するためのETL処理を削減できる。また、スキーマの適用と展開をDL上でサポートし、タイムトラベル機能もサポートするなど、従来のDLの欠点を補填している。さらに、DWH層を排除することで、DLに入ってくるリアルタイムデータと本来バッチ処理後にDWHに格納されるデータを即時的にマージできるため、アナリストやデータサイエンティストは常に最新のデータを分析に活用できる。
watsonx.dataとは、IBMが提供する、次世代LHアーキテクチャを搭載したデータ基盤である。後述する各種技術によって、すべてのデータをDWHに格納する必要がなくなり、DWHとデータレイク間のデータ移動やそれにかかるコスト、時間、資源を削減できる。またワークロードに応じてクエリエンジンを切替ることにより、ベンダーロックインされることなく、肥大化するDWHコストの最適化を図ることができるようになっている。将来的にはIBM Watson Knowledge Catalog(WKC)との統合も予定されており、データガバナンスも本データ基盤上で実施できる予定である。具体的には、WKCの有するビジネス用語割り当て機能により、カラムがもつ意味を逐一調査する必要がなくなるため、検索の工数が削減できる。また、WKCで設定した個人情報のマスキングルールをwatsonx.data上でも適用することで、セキュアなデータ活用を1つのプラットフォーム上で実施できるようになる。WKCに関する詳細な機能については、IBMの製品ドキュメントやWeb上にさまざまな解説記事などがあるため、そちらを参照していただきたい。
watsonx.dataに利用されている主な技術と特徴
watsonx.dataで利用されている技術はすべてオープンソース技術である。あらゆるところで広く使われており、製品固有の技術に縛られることがないため、ベンダーロックインがない。
利用できるクエリエンジンはいくつか存在するが、代表的なものはPrestoとSparkになっている。Prestoは次世代のオープンソースSQLクエリエンジンで、アドホックなクエリ実行やさまざまなデータソースに対するクエリ実行を得意としている。Sparkは巨大なデータに対して高速に分散処理を行うオープンソースのフレームワークである。扱うデータが大量である場合や、データの高速処理が必要な場合に有効である。このようにwatsonx.dataでは、クエリの使い分けが可能であり、最適なワークロードで処理を実行できる基盤という特徴がある。
また、テーブルフォーマットにはIcebergを採用している。オープンなテーブルフォーマットのため、Presto、Sparkといったwatsonx.data内でサポートしているクエリエンジンからのアクセスが可能である。また、サポートしているファイルフォーマットもParquet、ORC、Avro、CSVなどデータ基盤で主に利用される形式はすべてカバーしている。そのほか、Icebergはオブジェクトストレージ上のトランザクションをサポートしている。スキーマ変更の追従やタイムトラベル機能も有しているため、従来のDL上のデータよりも格段に扱いやすさが向上している。
最後に、watsonx.dataにはカタログと呼ばれるメタストア層が存在する。これは複数の目的別クエリエンジンがさまざまなデータソースに対してクエリを実行し、LH内でデータを共有するための共有メタストアを表す。カタログはオブジェクトストレージや、watsonx.dataに繋がれているデータベースに格納される。
watsonx.dataを使ってみる
ではwatsonx.dataをどう使っていくのか、実際の画面を通じて見ていきたいと思う。紙面の都合上、一部の重要な機能に絞って紹介させていただければ幸甚である。また、前提として本ハンズオンで利用するS3互換のオブジェクトストレージはすでにwatsonx.dataと連携済みであり、クエリエンジンとも紐付けたところからスタートする。
①DB・オブジェクトストレージの登録
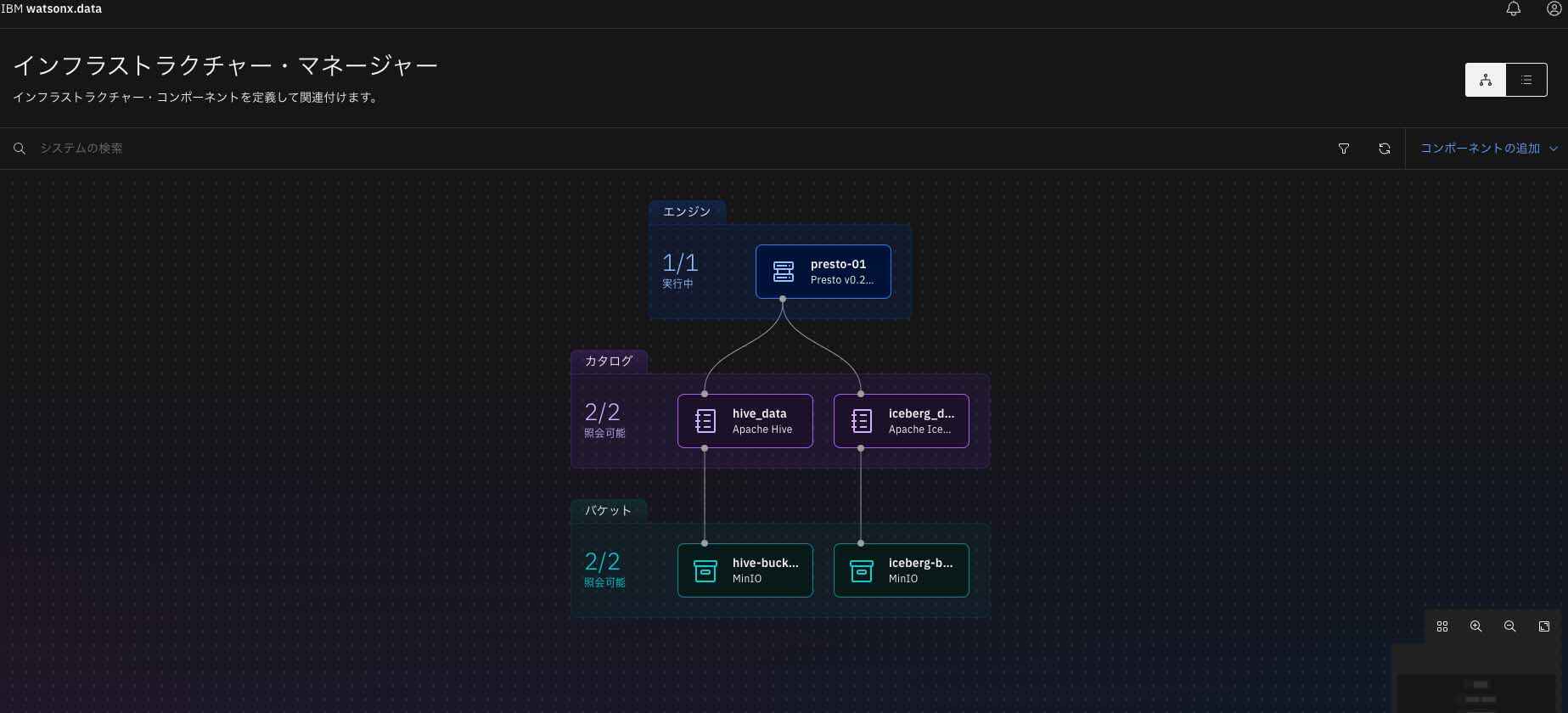
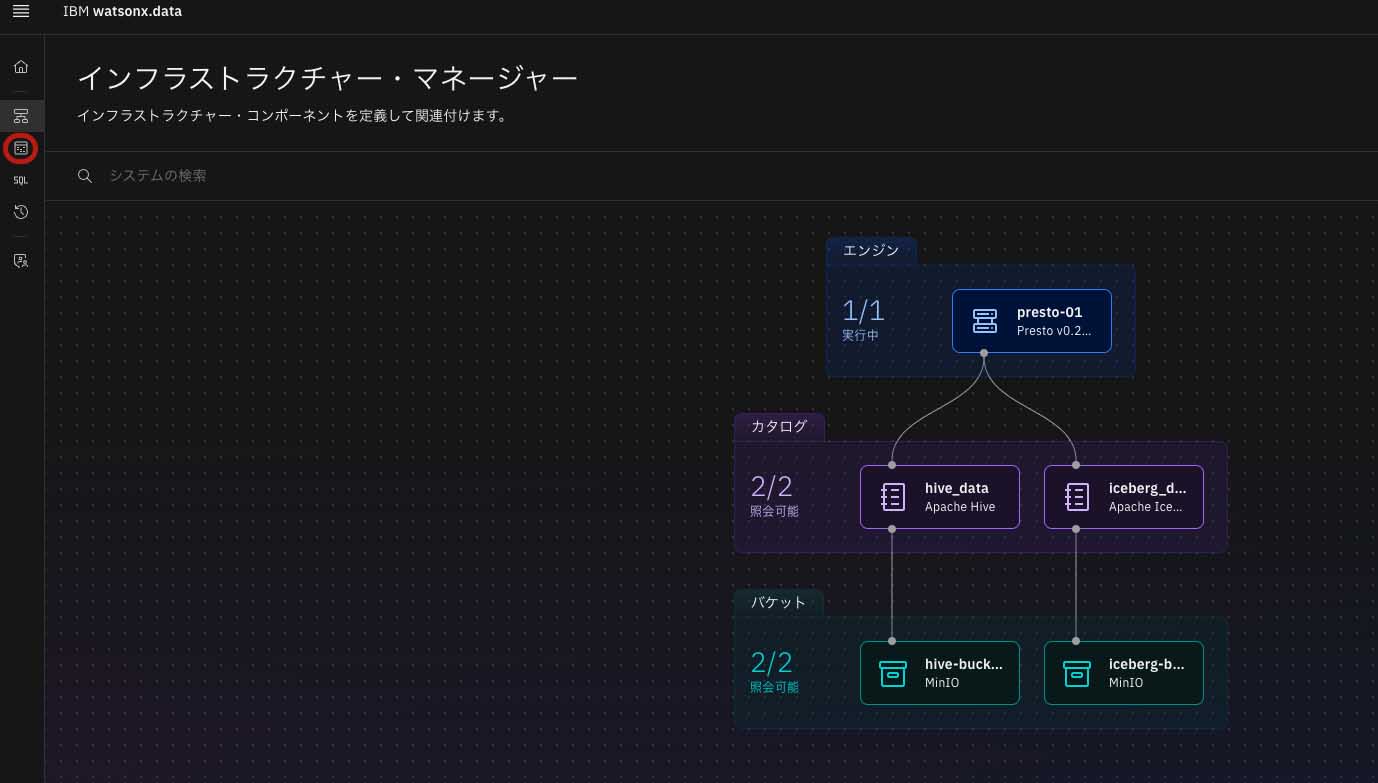
watsonx.dataにログインしたらまず、インフラストラクチャー・マネージャー画面に遷移する。ここでは、登録ずみのオブジェクトストレージやクエリエンジン、カタログが見えていることがわかる(図表1)。
ここで、図表2右端「コンポーネントの追加」から新しいオブジェクトストレージを追加したい場合は「バケットの追加」を、データベースを追加したい場合は「データベースの追加」をクリックする。
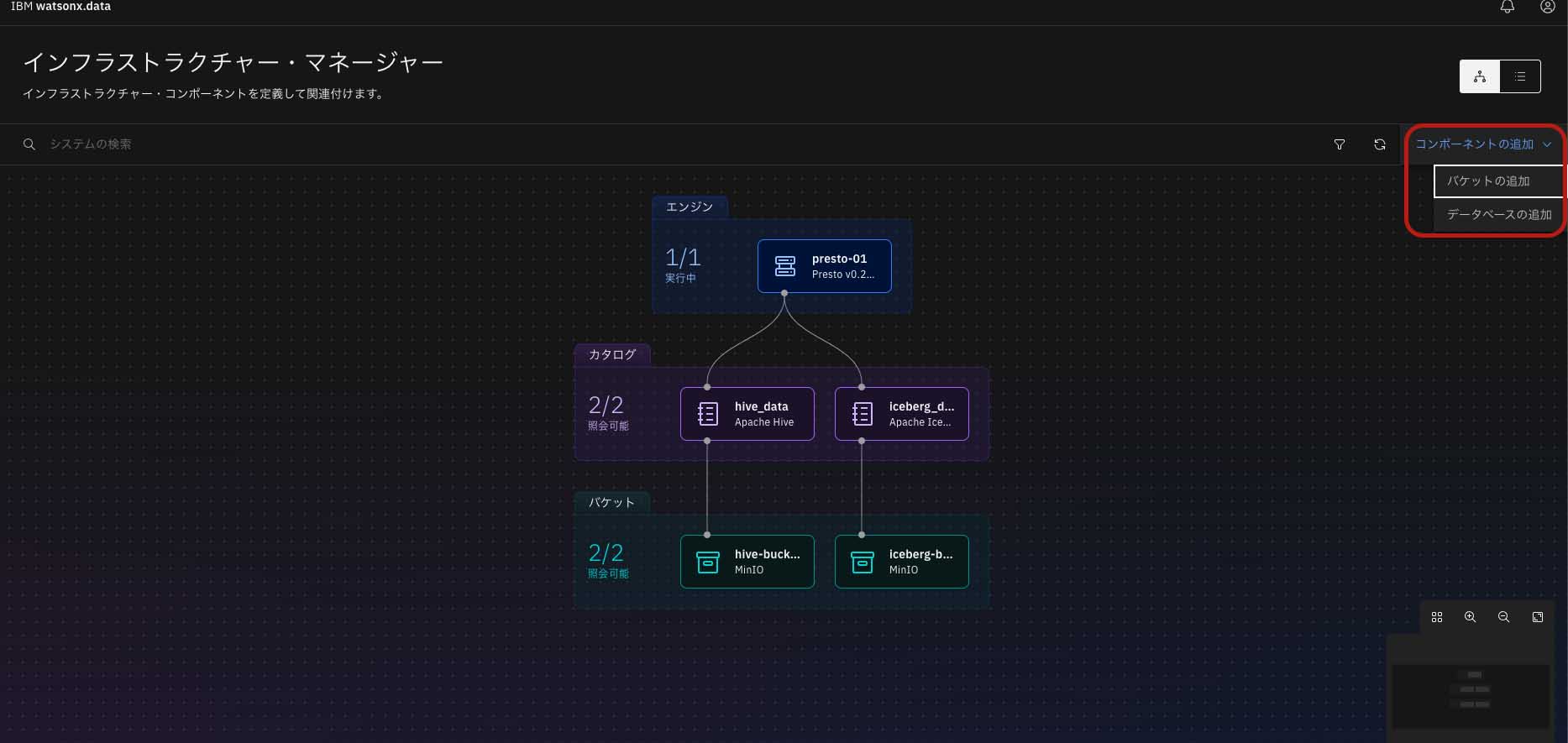
ここでは、バケットを追加すると想定してバケット登録画面に遷移する(図表3)。
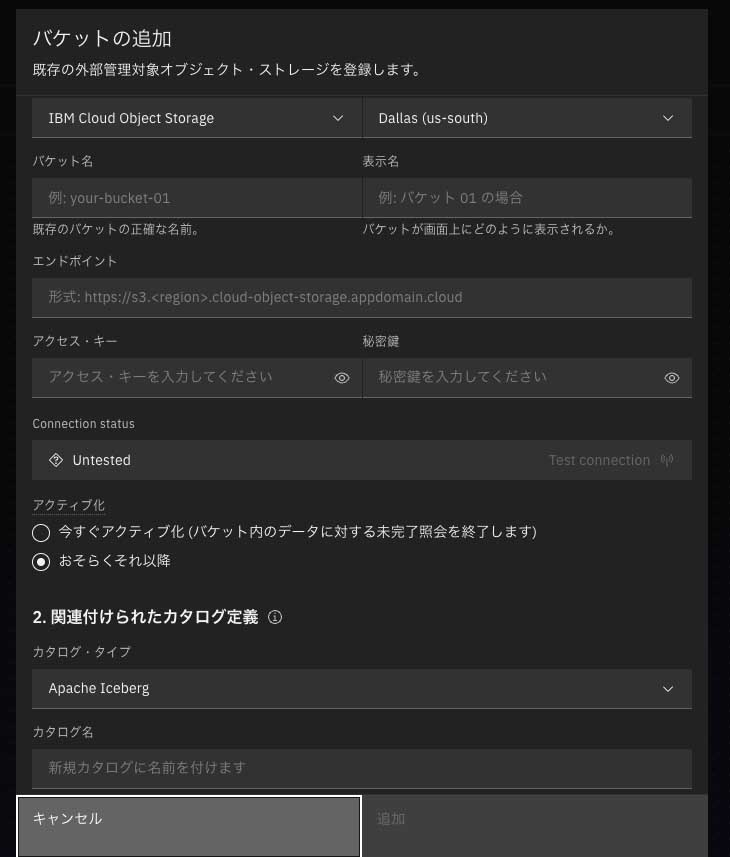
バケット名やバケットのエンドポイント、アクセスキー等を入力するほか、カタログを定義する。カタログ・タイプでは執筆時点でApache Icebergのほか、Apache Hive、Apache Hudiが選択できる。右下の追加ボタンを押下すると、図表1のインフラストラクチャ・マネージャー画面に戻る。その後、作成されたカタログとクエリエンジンを紐づければ、watsonx.data内部でデータが扱えるようになる(この手順は誌面の都合上、省略させていただく)。
②スキーマ・テーブル作成
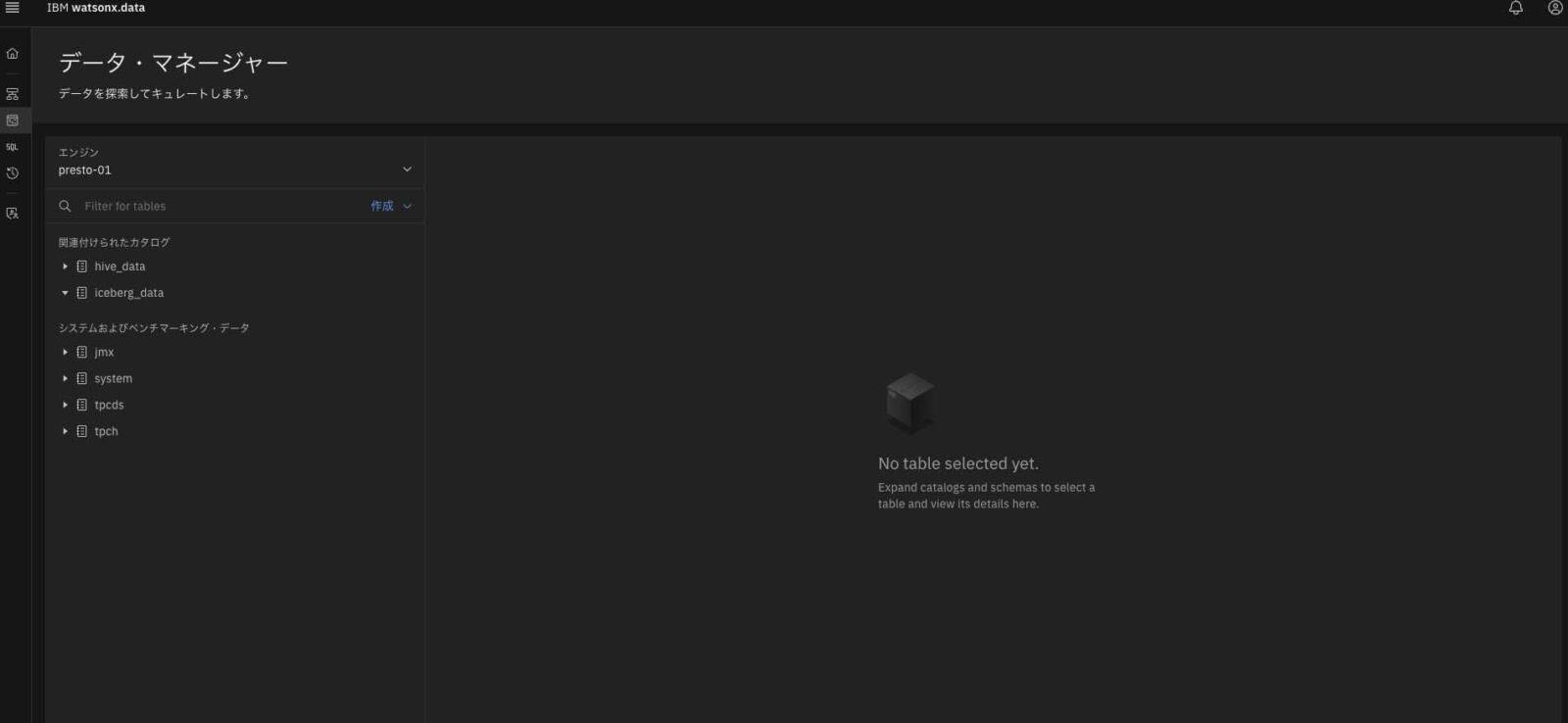
次にデータ・マネージャー画面に移り、先ほど登録したデータソース先のデータに対して、watsonx.data内でスキーマ・テーブルを作成し、データをクエリできるようにしていく。まず、インフラストラクチャ・マネージャー画面からデータ・マネージャー画面に遷移する(図表4)。
データ・マネージャー画面では、あらかじめ作成していた「iceberg_data」カタログが見えている(図表5)。
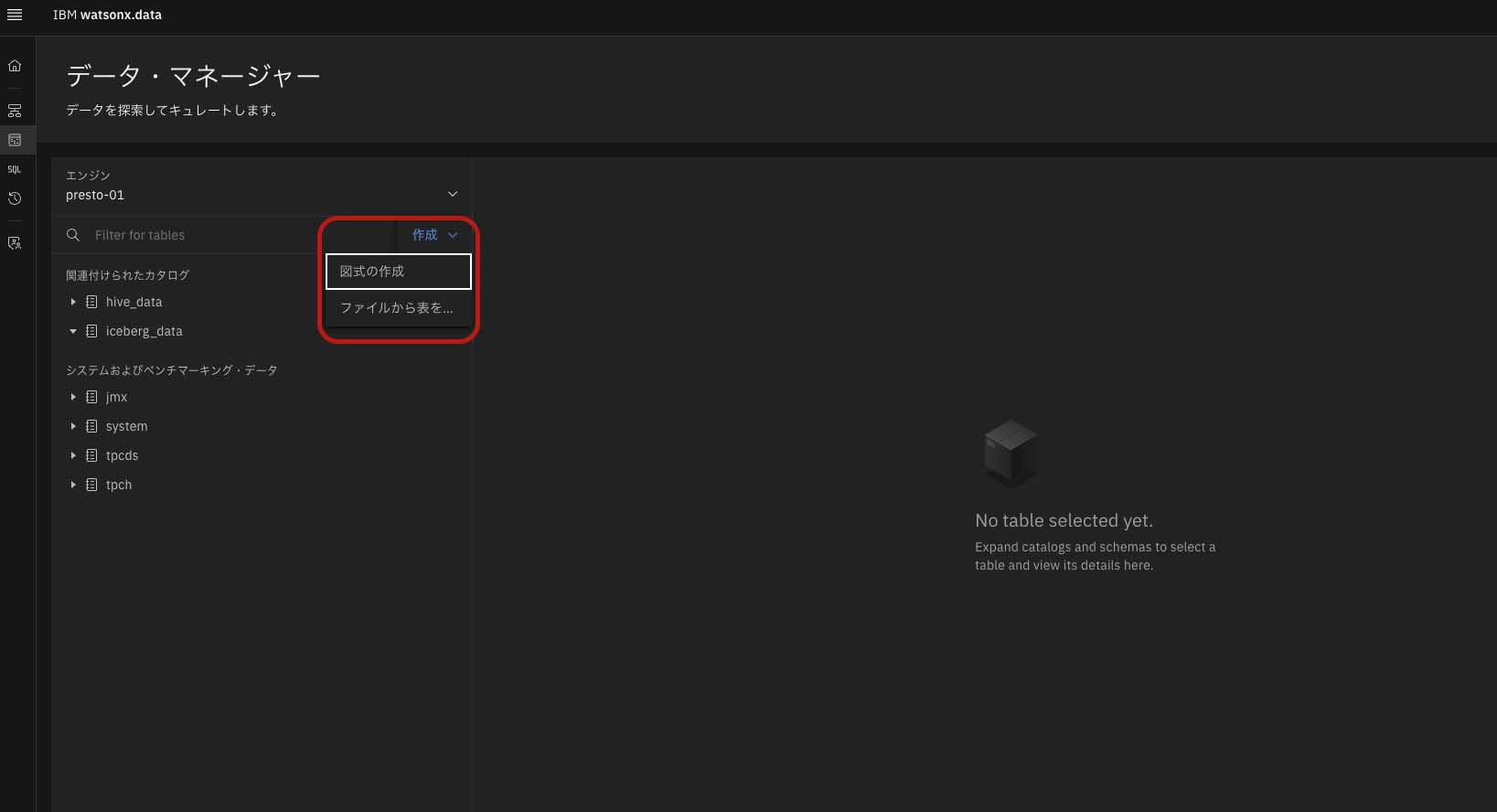
ここにスキーマやテーブルを順次作成するため、左に見えるバー右側「作成」から「スキーマの作成」を選択する(図表6)。
遷移先のスキーマ作成画面でスキーマ名を入力する。Path欄は自動入力されるため、作成ボタンを押下すると、データ・マネージャー画面に戻る。すると、作成したスキーマが表示されていることがわかる(図表7)。
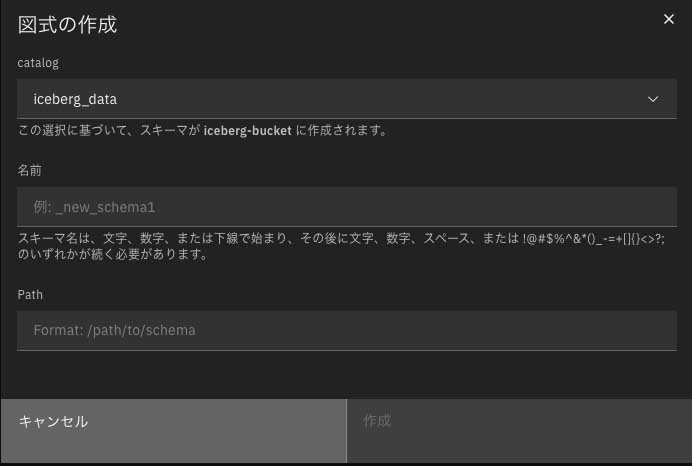
ここでは、「my_schema」という名前でスキーマを作成した(図表8)。
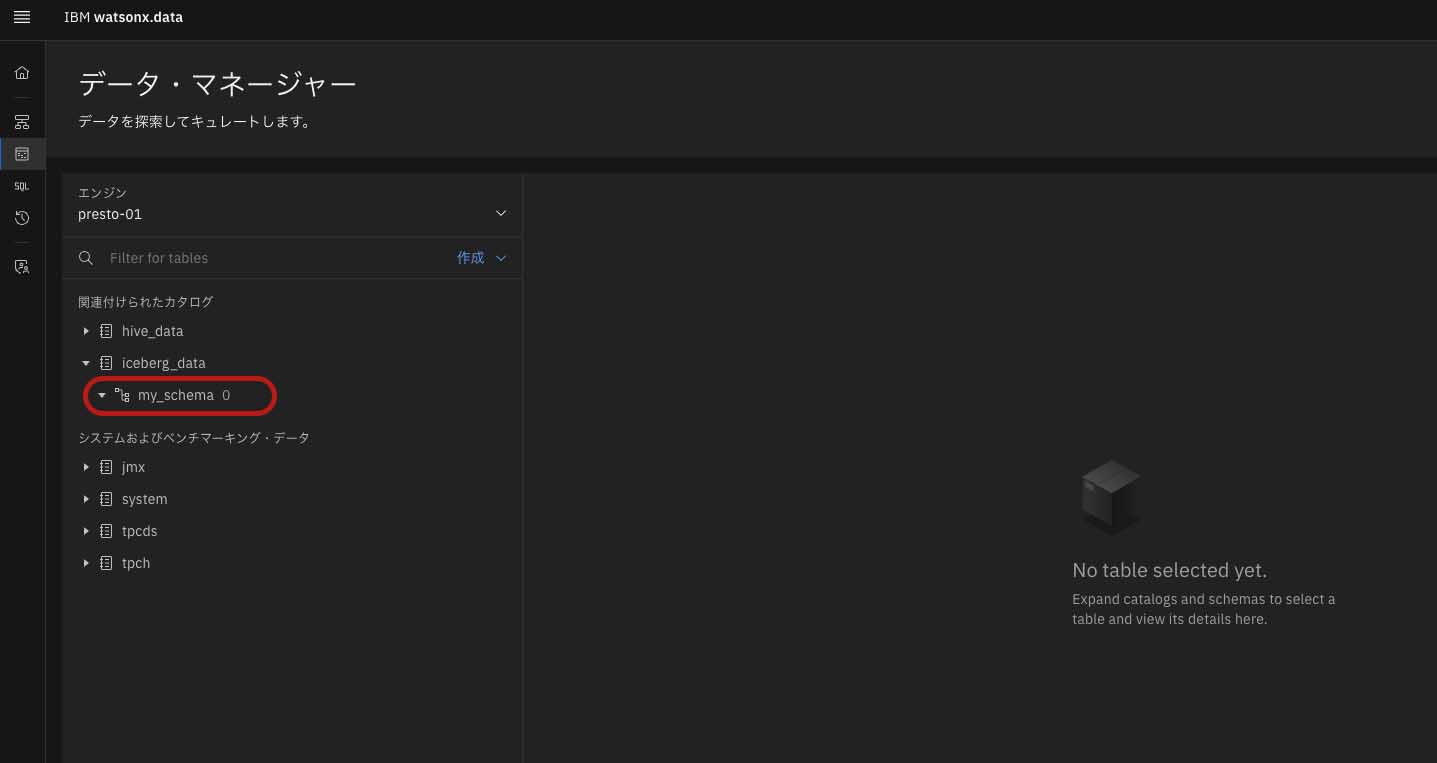
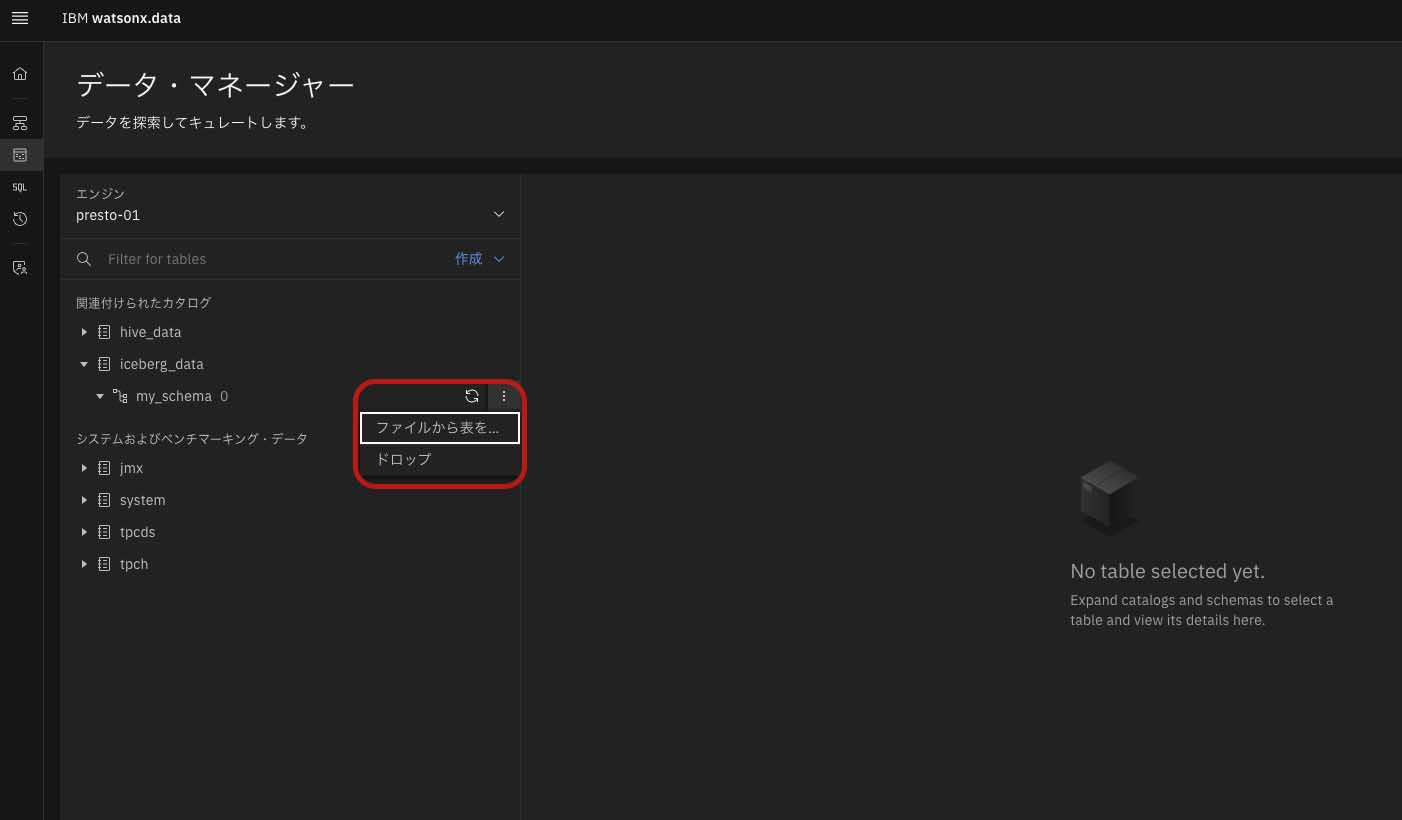
スキーマを作成した後、当該スキーマ配下にテーブルを作成する。今回はローカルファイルにあるデータを使用するため、作成したスキーマの右側にあるドットから「ファイルから表を作成」を選択する。遷移先画面でファイルのアップロードが行えるため、アップロードしたいローカルファイルを選択して「次へ」を選択する(図表9)。
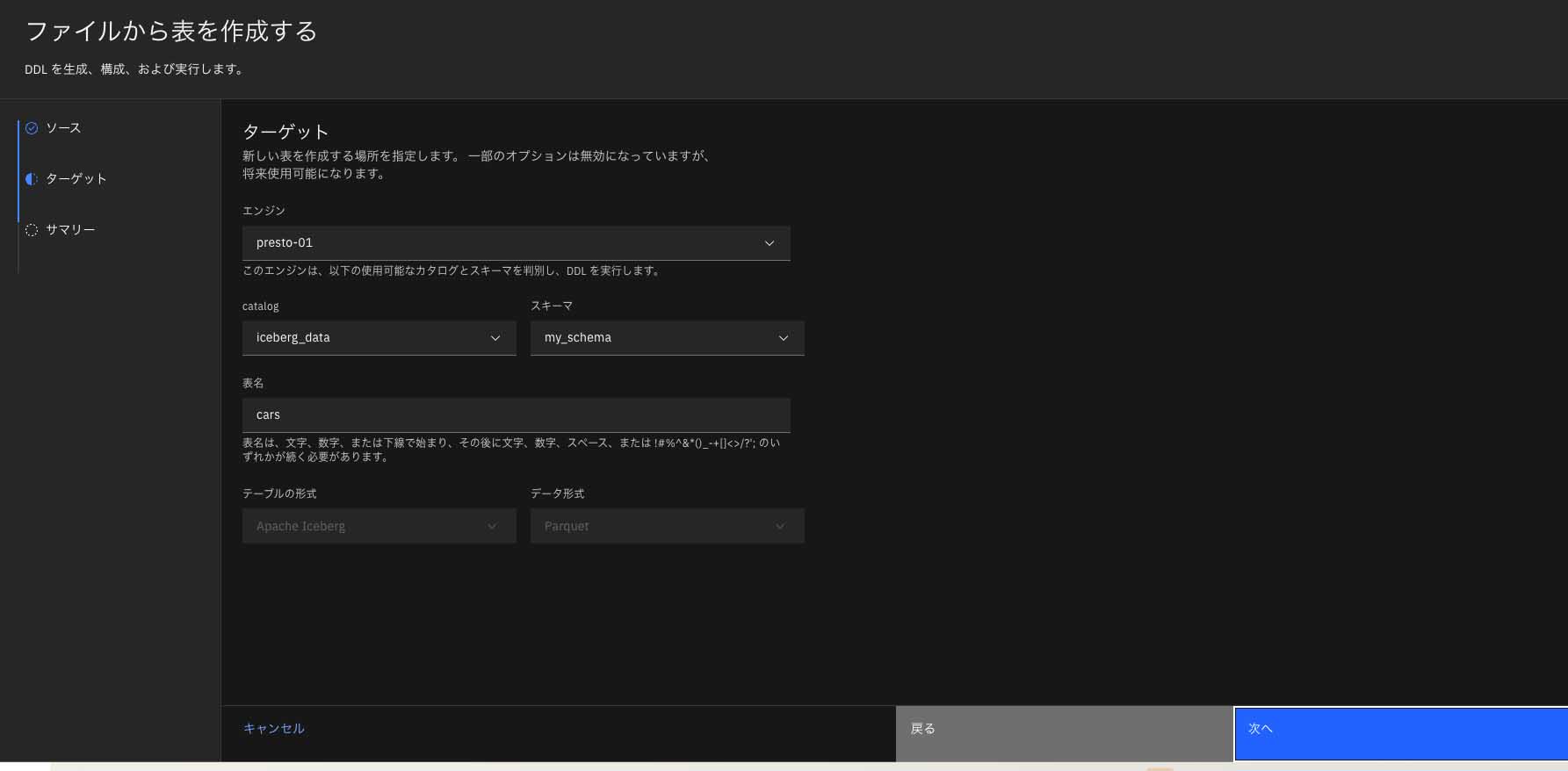
ここでは具体例としてオープンデータである「cars」の CSVファイルをローカルから読み込んでいる。遷移先の画面でテーブル名を入力し、「次へ」を押下する(図表10)。
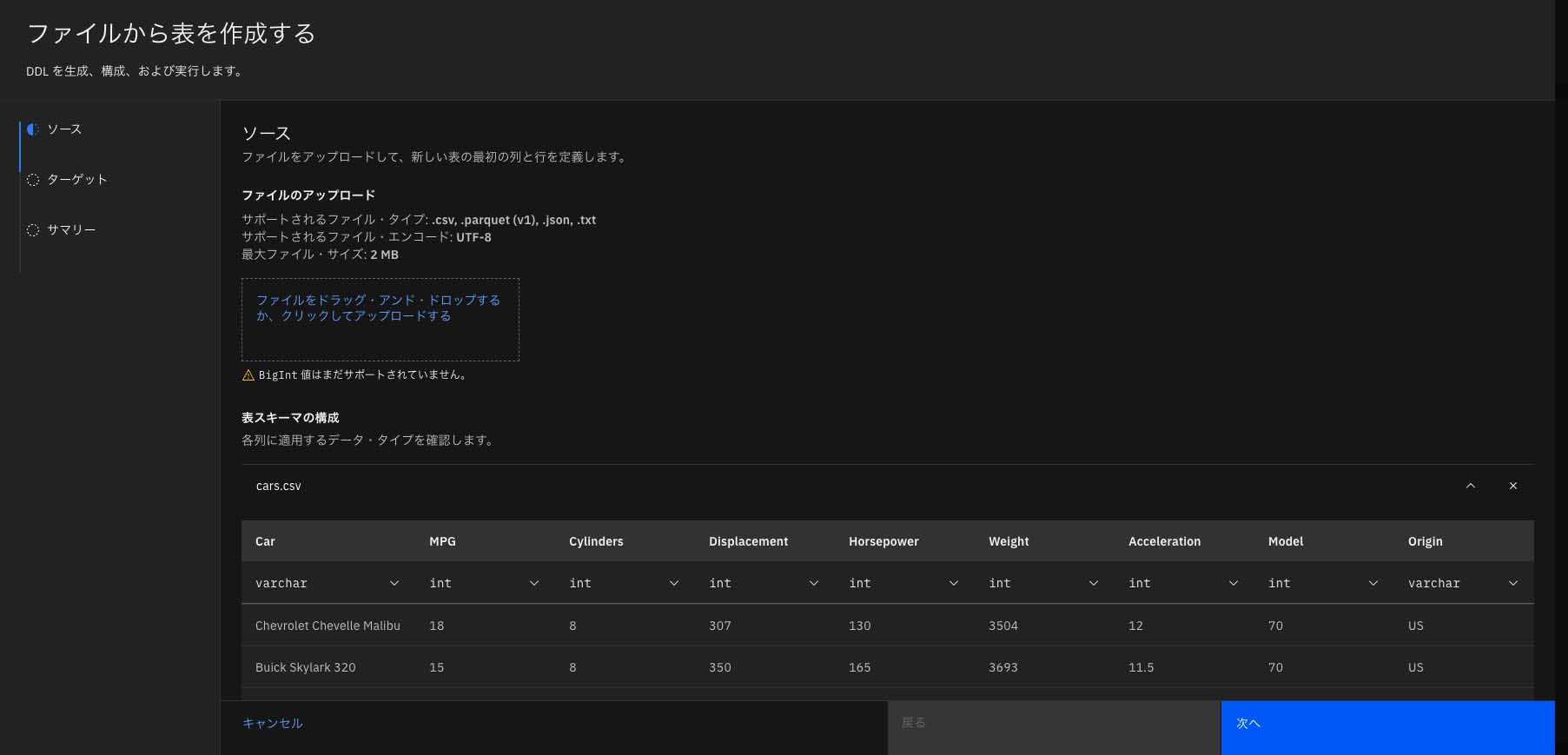
すると、次画面で表名やテーブル形式、DDLプレビューといったテーブルに関するサマリが表示されるため、確認して問題がなければ「作成」ボタンを押下する(図表11)。
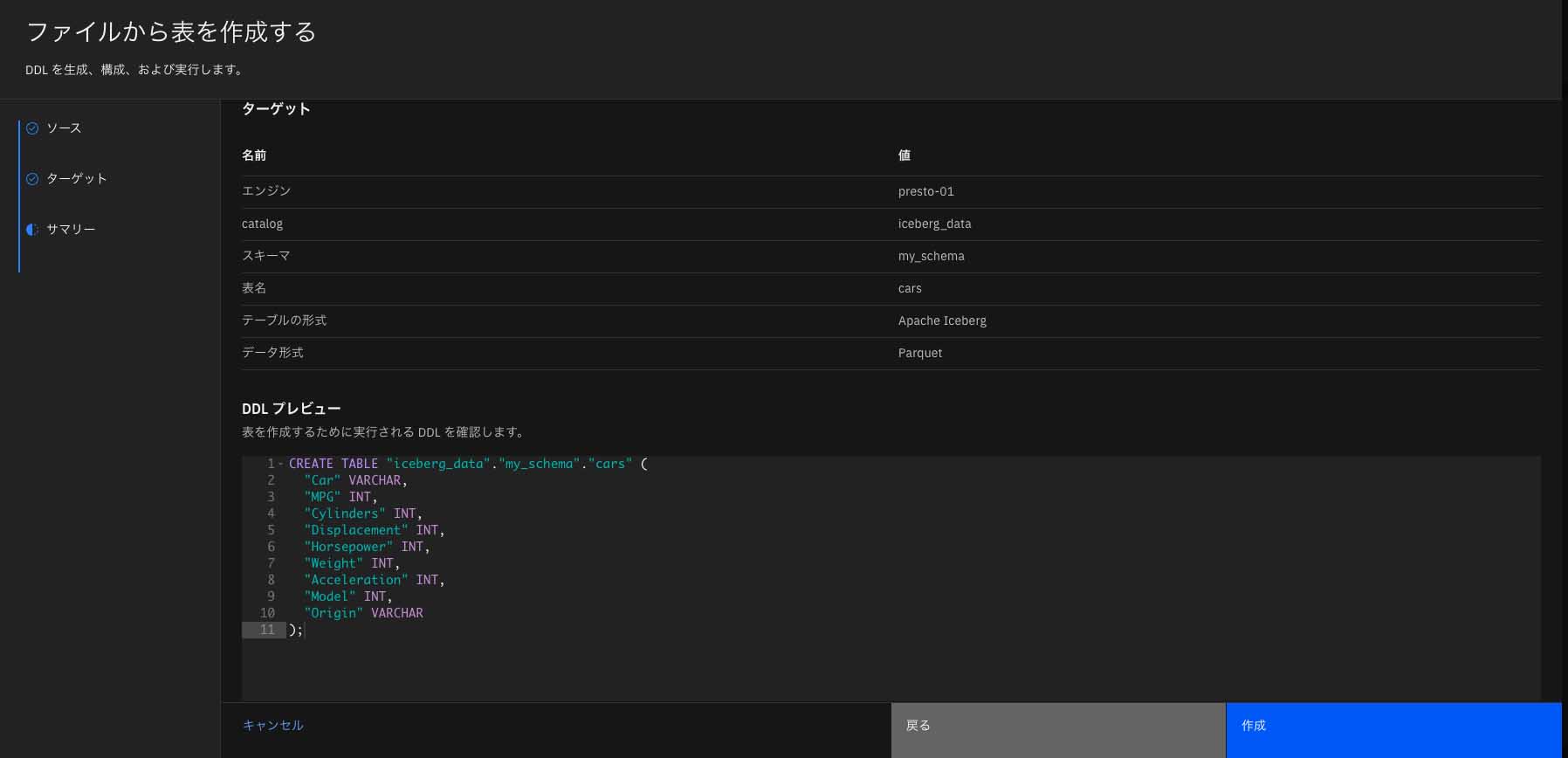
最後に、データ・マネージャー画面に戻るため、そこでテーブルが作成されたかどうかチェックを行う(図表12)。
③クエリの実行
最後に、先ほど作成したテーブルデータへのクエリを行ってみる。
まずデータ・マネージャー画面からクエリワークスペースへ移動する(図表13)。
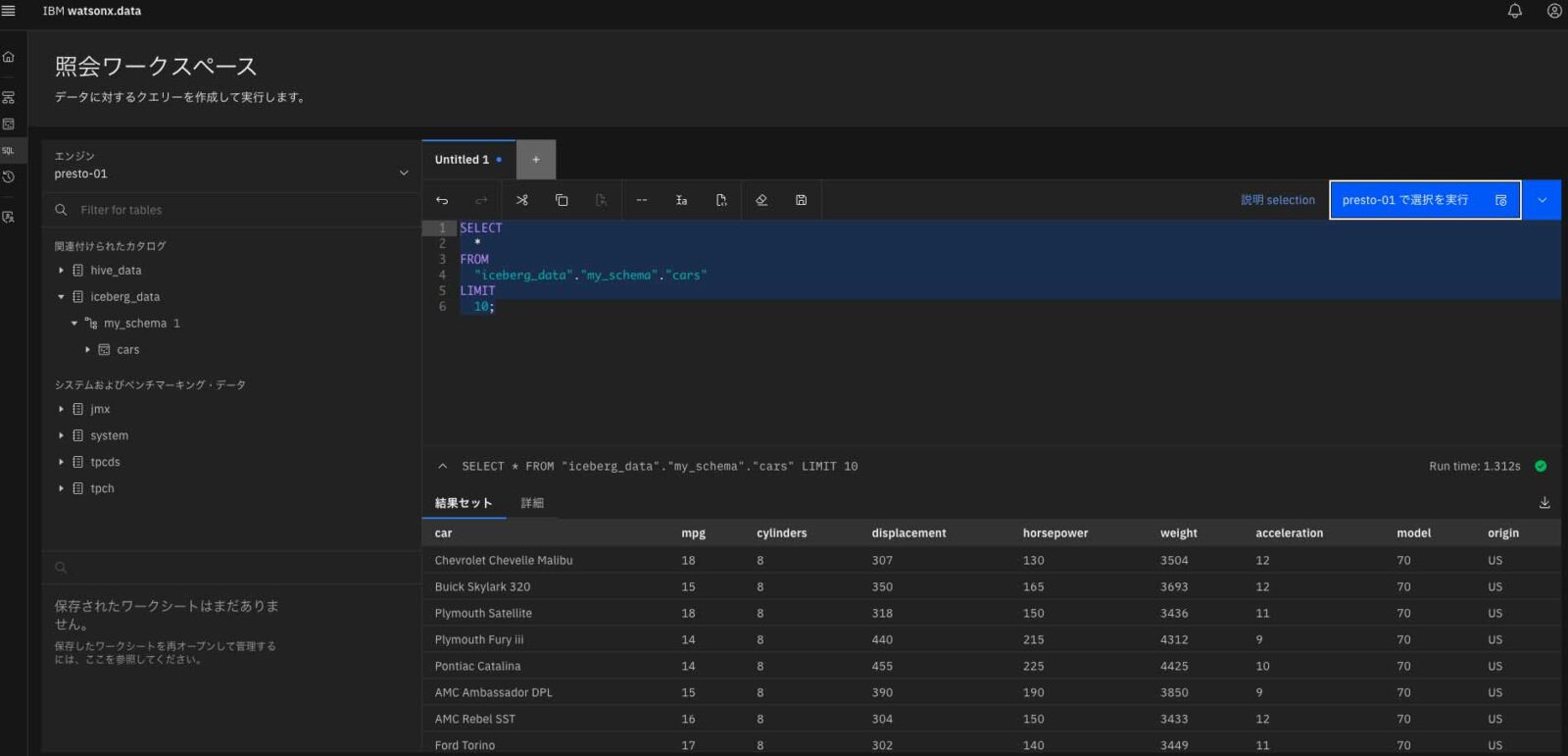
クエリワークスペースで、実際に以下のSQLを打ってみた結果を表示する。SQLは以下。
SELECT
*
FROM
”iceberg_data”.”my_schema”.”cars”
LIMIT
10;
図表14の通り、SQLクエリを通じて結果が返却されることがわかり、データがwatsonx.data上で扱えるようになった。
*
以上が、watsonx.dataのお手軽ハンズオンを通じた紹介である。まだまだここでは触れられない機能やTips、今後リリース予定の新機能など、こちらの記事をエントリーポイントとして深淵を覗いていただければ幸甚である。

*本記事は筆者個人の見解であり、IBMおよびキンドリルジャパン、キンドリルジャパン ・テクノロジーサービスの立場、戦略、意見を代表するものではありません。
当サイトでは、TEC-Jメンバーによる技術解説・コラムなどを掲載しています。
TEC-J技術記事:https://www.imagazine.co.jp/tec-j/
![]()
[i Magazine・IS magazine]