画像認識にはさまざまな定義があるが、本稿では「画像処理の技術を用いて、画像を理解・認識すること」として説明する。 画像の理解・認識の例として、画像に人が写っていることを認識したり、顔のある場所を検出したり、写っている人の年齢・性別の推定を行う(図表1)。このような認識、検出、推定など画像認識の代表例に物体認識、物体検出、類似画像検索がある。

物体認識
物体認識では、与えられた画像中に写っているものが何であるかを認識・推定する。認識の粒度には、一般的なカテゴリ(人、犬、猫)での認識や、具体的な個体名や製品名での認識がある。前者を「一般物体認識」、後者を「特定物体認識」と呼ぶ。
物体検出
前述した物体認識の機能に加えて、物体が画像のどこに写っているかを見つける。
類似画像検索
ある画像を入力にして、大量にある画像から類似画像を探し出す。背景、構図、色、質感などさまざまな特徴を使って類似度をスコアリングし、似ている画像を探し出す。
3つの画像認識技術
画像認識技術の手法はルール、機械学習、深層学習の順で発展を遂げている。
ルールに準じた手法では、単純なルールに基づいて画像を認識するので、対象となる画像の見た目が変化するケースには対応しきれない。機械学習ではそれを補完する形で、対象の見た目が変化する場合でも、入力となるデータからトレーニングすることで学習モデルを作成し、そのモデルに従って画像を認識できる。ただし特徴量というデータを人が与えており、その特徴量の選択によって認識精度が大きく変化する。
これに対して深層学習では、トレーニングで特徴量を抽出でき、人間の認識力を上回る成果を上げている。
以下、それぞれの詳細を説明する。
ルール
ルールベースには複数の方法があるが、ここではテンプレート・マッチングを例に、どのように画像を認識しているかを説明する。
テンプレート・マッチングは、テンプレートと呼ばれる小さな一部の画像領域と同じパターンが、画像全体の中に存在するかを調べる方法である。同じパターンであるかを判断する方法はいろいろだが、最も簡単なのは領域間の対応する画素値(RGB値)の差の二乗和を取る方法である。この値が小さいほど、テンプレートと類似していることになる。
ルールを使った方法は、検出したい対象の見た目が照明の変化、角度、対象の変形などによって変わらない場合に有効である。 逆に検出したい対象の見た目が変化する場合には、単純なルールによるマッチングは向かない。たとえば人の検出では服装、体格、姿勢などによって見た目が異なり、単純なルールではマッチングできない。そこで使用されるのが特徴量である。
特徴量によるマッチングは、画素値(RGB値)をマッチングに使うのではなく、その物体を最もよく表現するポイントを数値化し、それを使ってマッチングする。たとえば輪郭を特徴として使えば、照明の変化や色の変化による影響を受けづらくなる。
機械学習
ルールベースを補完する機械学習を利用することで、見た目が変化する場合への対応を強化できる。機械学習はデータの集合から、そのデータの法則性を学習する技術である。データから学習するため、ルールベースでは予測できなかった法則を使ってマッチングを評価できる。
機械学習には、2つのステップがある(図表2)。ステップ1では、データの集合から学習し、学習モデルを作成する。ステップ2では学習モデルを使って、データを分類する。ここで使用するデータが、特徴量である。
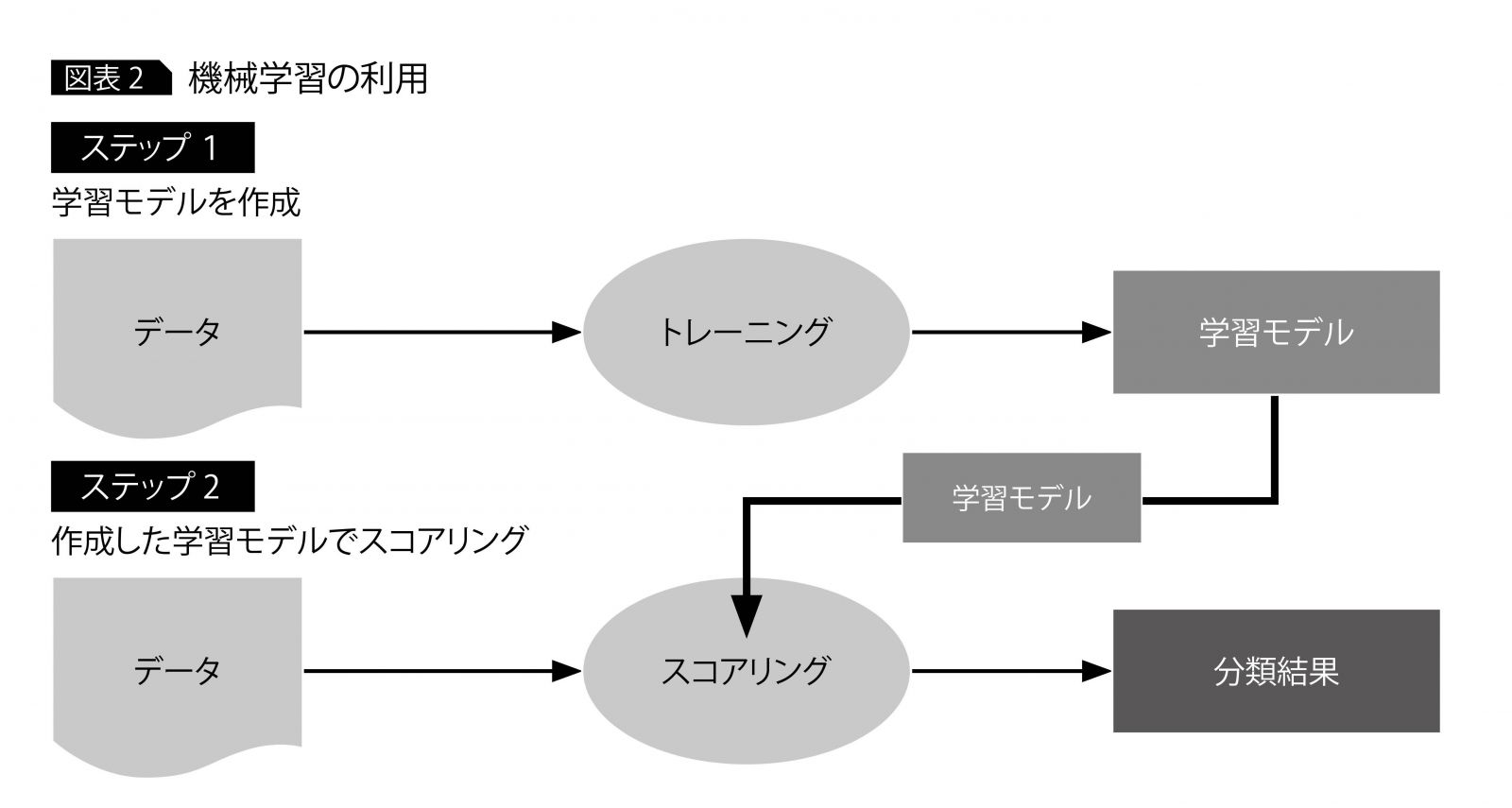
特徴量は、データの特徴に合ったものを人が選択する必要がある。特徴量の選択によって、認識精度は大きく変化する。適切な特徴量を見つけるには、データの特徴を理解し、試行錯誤やある程度の経験が必要となる。
深層学習
深層学習は機械学習手法の1つであり、学習モデルを作成し、これを使用してスコアリングするという手順は変わらない。機械学習と深層学習の違いは、学習モデルを作成するステップで特徴量を設定する必要のない点である。
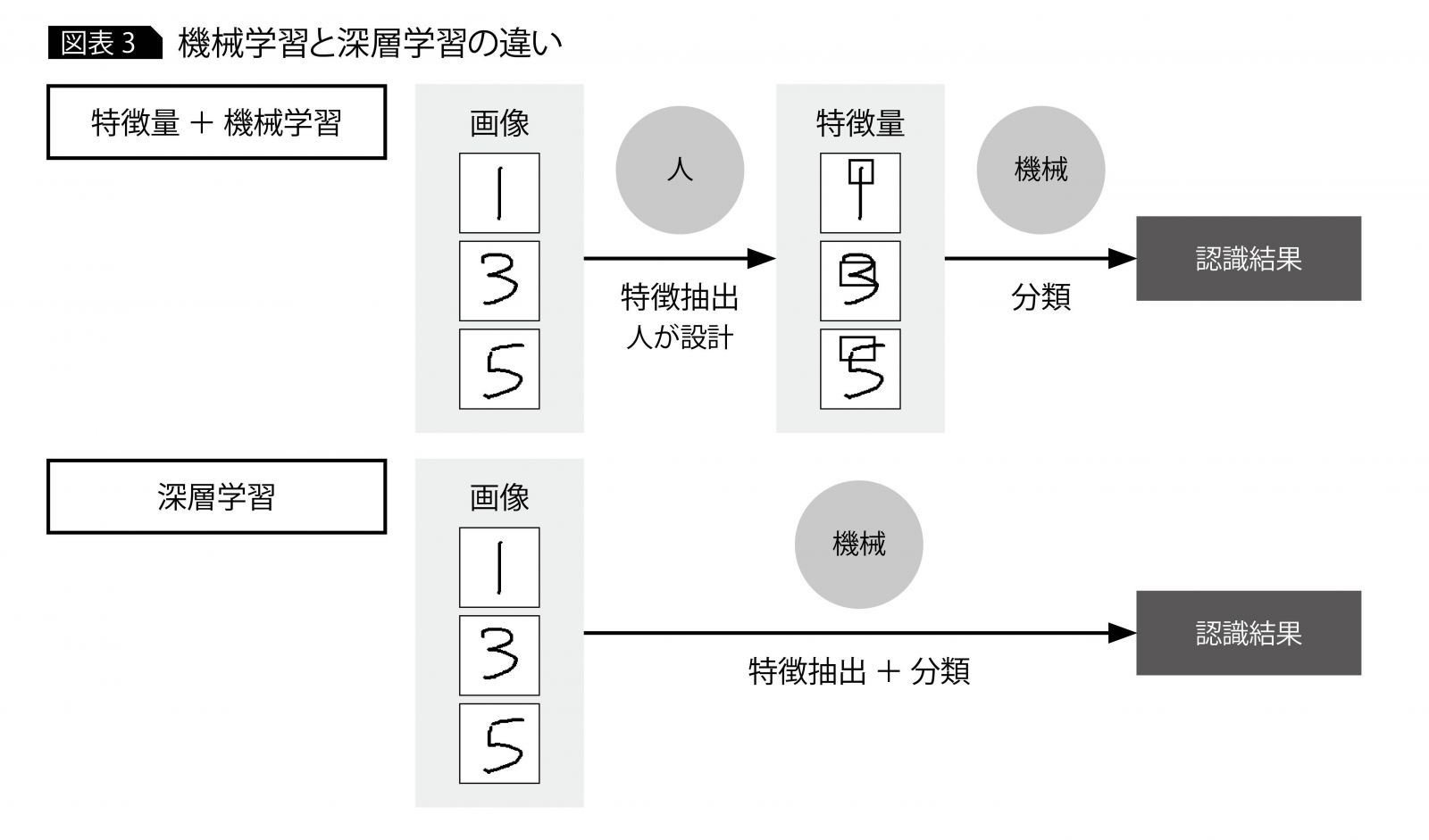
図表3に、機械学習と深層学習の違いを示す。特徴量と機械学習を使った方法では、人がまず特徴量を設定し、特徴抽出を実行し、機械学習のアルゴリズムで分類していた。これに対して深層学習では、人による特徴量を設定する必要がない。人が正解ラベルを付けたデータを与えれば、あとは機械が特徴を抽出し、それをもとに分類する。深層学習を使うと、試行錯誤が必要な特徴量を設計することなく、高精度の画像認識を実現できる。
深層学習の実装方法
ここからは、最近とくに注目を集める深層学習に焦点を当てて実装技術を見ていこう。深層学習の実装には、大きくAPIとフレームワークの2種類がある。
APIではWebのインターフェースを介して画像を送り、事前にトレーニングされたモデルを利用してクラウド上でスコアリングし、結果を受け取る。スマートデバイスなどに搭載されるカメラとネットワーク環境さえあれば手軽に利用できる。
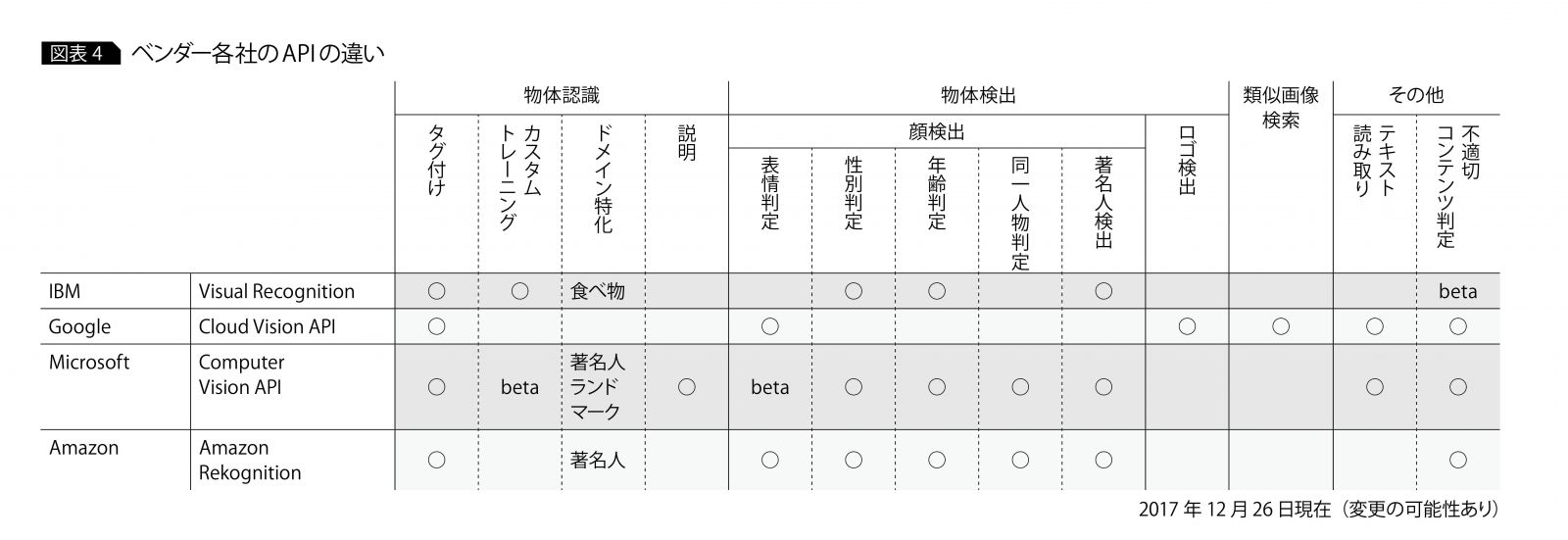
現在、画像認識系のAPIを提供するベンダーにはIBMやMicrosoft、Google、Amazonなどがある。図表4に、ベンダー各社のAPIの違いを示す。なかには独自にトレーニング(カスタムトレーニング)できるAPIも登場している。
これに対してフレームワークとは、枠組み(フレームワーク)に沿ってトレーニングやスコアリングをしやすくするライブラリである。代表的なフレームワークにはTensorFlowやCaffe、Chainerなどがある。
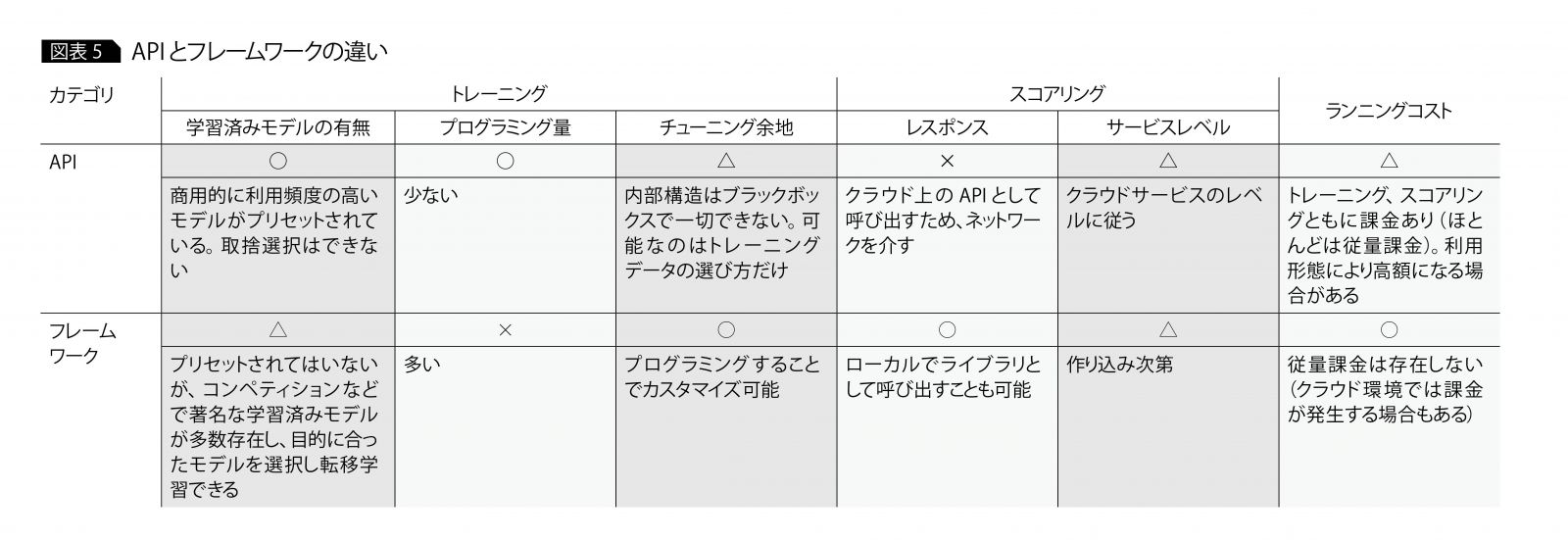
フレームワークでは、ネットワークの組み方などトレーニング方法を変更できる。また分類する場所がクラウドに限定されないなど自由度が高い半面、プログラミング量が多くなる。図表5に、APIとフレームワークの違いを示す。これらの制約や違いを理解したうえで、画像活用の要件に合った技術を選択する必要がある。
Visual Recognitionに挑戦
以下に、Watson のAPIである「Visual Recognition」を利用して、APIの活用方法を解説しよう。Visual Recognitionのトレーニング機能は、ビジネスで利用される任意の画像を対象に、それに特化したスコアリングを提供する。深層学習を利用しており、前述のとおり特徴量を明示的に教える必要はなく、シンプルに利用できる。
利用手順は、以下のようになる。
①利用者は分類したい画像群を一まとめに し、ラベルとともに提供する。
②Visual Recognitionは受け取った画像群 から特徴を抽出し、学習モデルを作成する。
③利用者は分類したい画像を学習モデルに 対して提供する。
④Visual Recognitionは受け取った画像 をスコアリングし、分類結果であるラベル を返却する。
デモサイトを利用して一連の流れを体験し、Visual Recognitionの理解を深めよう。「IBM, Watson Developer Cloud, Visual Recognition.」(https://visual-recognition-demo.mybluemix.net/)にアクセスすると、画面に「Try」と「Train」というタブが表示される。「Try」は一般物体認識のうちプリセットされた分類器、たとえば動物や人、食べ物、植物などを試せる。今回扱うのは「Train」で、一般物体認識のうち独自のトレーニングを体験できる。
①画像群をまとめてクラスを登録
「Train」サイトでは多彩なユースケースを用意しているが、一例として「Insurance Claims」をクリックしてみよう。これは保険業界のユースケースであり、事故車両の画像から事故を分類する。分類には学習モデルを利用する。この学習モデルをVisual RecognitionではClassifier(分類器)と呼ぶ。そして、分類結果である「飛び石」や「パンク」「巻き込み」「いたずら」のようなラベルをClass(クラス)と呼ぶ。
通常はこのクラスごとに、利用者は画像群を一まとめにしてトレーニングさせる必要があるが、このデモサイトではあらかじめクラスごとに一まとめにされた画像を用意しており、複数選択すればよい(図表6)。

なおUndamaged Vehiclesというラベルは、事故のない車両を表し、画像認識では不正解な画像群として扱う。これにより、画像認識の精度を向上させられる。選択し終わったら、「Train Your Classifier」をクリックする。
②画像群から特徴を抽出
「Train Your Classifier」をクリックすると、選択された画像群とラベルがAPIを介してクラウドへ送信され、Visual Recognitionがトレーニングを開始する。3〜4分ほど経過すると、学習モデルが作成される。
③学習モデルに対して画像を提供
利用者はテストするために、分類したい画像を提供する。「Use a system test image」をクリックすると、事前に用意された画像を提供できる。
④画像をスコアリングしてスコアを返却
画像がAPIを介してクラウドに渡り、Visual Recognitionがスコアリングし、結果のクラスと確信度であるスコアを返却する。この例ではパンク画像を提供したが、正しくパンクと分類され、0.85というまずまずの確信度が得られた。
今回は保険業界のユースケースを利用したが、独自に用意した画像でもトレーニングやスコアリングを試せる。試したい画像があれば、分類器選択時に「Use Your Own」を選択すればよい。
利用時のポイント
シンプルな画像認識の例を紹介したが、利用に際して工夫すべき点がいくつかある。
バリエーションのある画像群を用意
各クラスで最小50枚程度からトレーニングを始められるが、似たような画像ばかりを集めると、それに特化して学習してしまう(過学習という)。似た画像は分類できるが、少しでも異なる画像になると分類不能になる。
過去の実証実験では、対象物に対して背景の割合が大きい複数枚の画像をトレーニングした結果、対象物ではなく背景を学習してしまう例が見られた。背景が変わると、対象物として認識できなくなるわけだ。
過学習を避けるには、照明や角度、形状、背景などの変化に富んだ画像群を用意することが重要である。
正解した割合を評価基準に
従来システムの評価では、さまざまなテストケースを用意して100%達成することが望まれた。ルールベースであれば100%達成も可能だろう。しかし機械学習や深層学習では、これまでと同じ考え方をしていてはテスト達成基準に到達できない。
評価基準を成功・失敗の2値で扱うのではなく、正解した割合を見ることが重要である。そして正解の割合を要求レベルまで向上させるため、トレーニング画像を変更・修正しながら、何度も繰り返し機械学習させていく。
以上本稿では画像認識に着目し、その位置付け、歴史的背景、執筆時点での技術を整理した。また深層学習を利用した技術のなかでVisual Recognitionに焦点を当て、利用方法を紹介した。Visual Recognitionでは画像認識をシンプルに始められる半面、実際の利用に際しては工夫の余地もある。たとえば画像認識精度の問題、精度向上に向けた分類器の設計、そのための画像や学習モデルのバージョン管理などだ。
いくつかのポイントを解説したが、ほかにも公式ドキュメントである「IBM. Guidelines for training classifiers」(http://bit.ly/2Bii5nG)や「IBM Bluemix Blog」(https://ibm.co/2yloQQe)などで詳しく紹介されている。
今回紹介した画像認識が、ビジネス課題を解決する選択肢になれば幸いである。
・・・・・・・・
著者|曽田 俊明 氏
日本アイ・ビー・エム システムズ・エンジニアリング株式会社
コグニティブ・ソリューション
IoTソリューション
シニアITスペシャリスト

2002年に日本IBM入社。Db2、Replication、Federationなどデータベース関連の製品を専門とし、プロジェクトの技術支援に従事。2015年後半からIoT、Watson関連のプロジェクトに参画している。