IBMとグラミー賞を主催する全米レコード芸術科学アカデミーは、アーティストに関する膨大な情報からインサイト(洞察)を抽出し魅力的なユーザー体験を提供するシステムをIBM Watsonを用いて共同開発した、と発表した。
4月3日午後5時(米国東部時間、日本時間4月4日午前7時)からの第64回グラミー賞授賞式の生放送で使われるほか、グラミー賞サイト(Grammy.com)のアーティストページでは3月18日から提供が始まっている。
今回開発した「GRAMMY Insights with IBM Watson」(以下、GRAMMY Insights)は、数千のデータソースから数百万件に及ぶ記事・情報を収集し、自然言語処理機能をもつIBM Watson Discoveryにより注目すべき洞察(インサイト)を抽出し、人間による評価を経て、アーティストらが登場するライブ映像にインサイトをリアルタイムで表示する、というもの。
「インテリジェントなワークフローであるGRAMMY Insightsは、世界中の音楽ファンに魅力的なユーザー体験を提供するだけでなく、AIがユーザーのコンテンツ体験と消費の方法をどのように変えるかを実証している」と、IBMはその意義をアピールしている。

そのGRAMMY Insightsについて、IBMが解説しているので紹介してみよう。
まず、開発のテーマは2つあり、1つは、ユーザーのエンゲージメントをより高めるためのデジタル体験の強化、もう1つは全米レコード芸術科学アカデミーのチームがより専門性を発揮できる機能の実装という。
IBMではそのための仕組みとして、下図を設計し開発した。ユーザーやアカデミー・チームがどこからでも利用でき柔軟にスケールできるようRed Hat OpenShiftベースで開発し、サーバーレス・コンピューティングを実現するためIBM Cloud Code Engineを採用した。
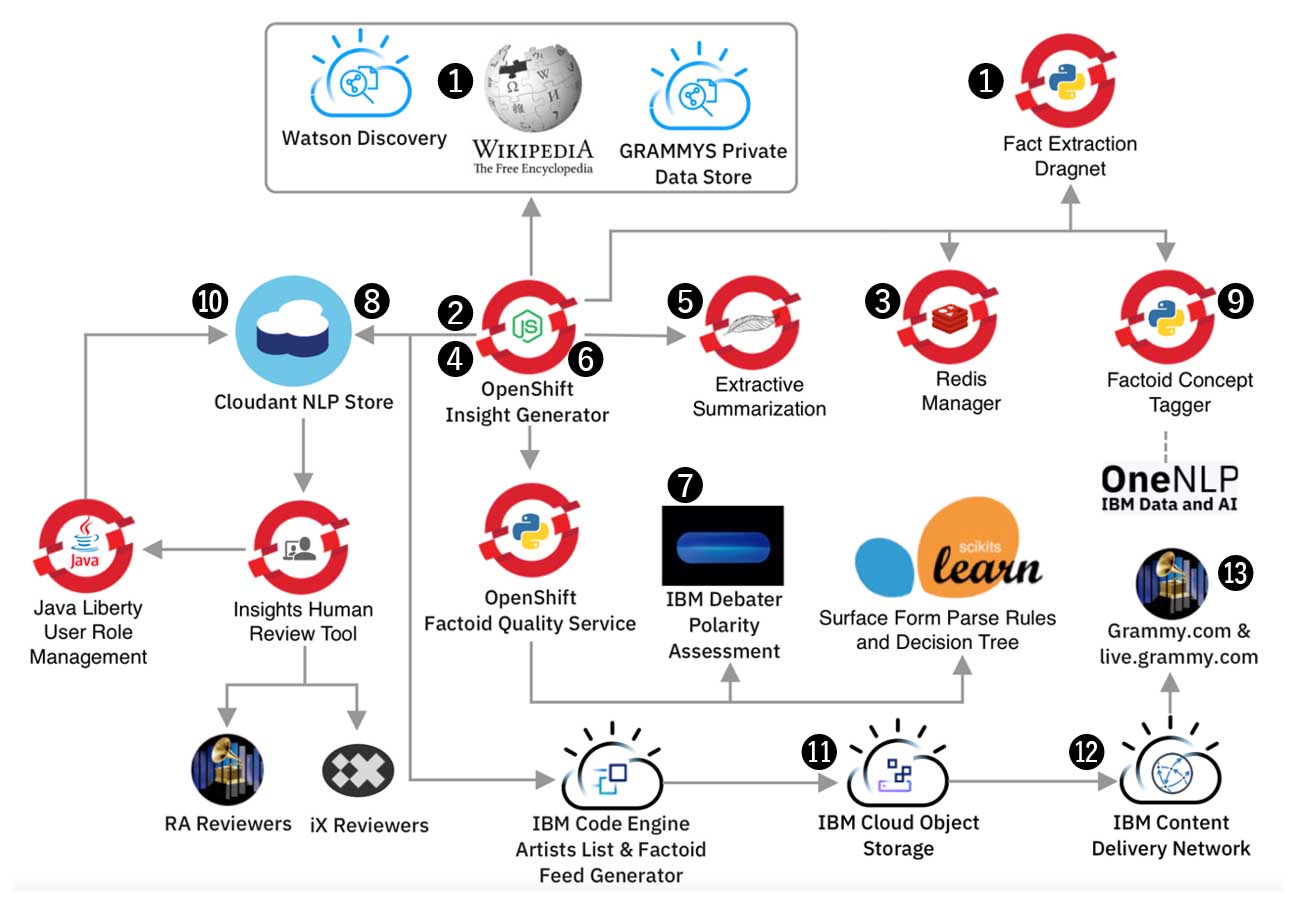
IBMによると、システムは「インサイトのキュレーション」と「ファクトの発見」の2つのフェーズに分けられる。その解説から技術的なポイントを箇条書きにしてみよう。
◎インサイトのキュレーション
❶ 10万以上のニュースサイトやWikipedia、Dragnet、GRAMMY.comの記事・コンテンツから情報を抽出し、コーパスを作成。
❷ すべてのメッセージとデータフローのブローカー機能として「Insight Generator」を設計。Node.jsベースで開発した。
❸ 永続化可能なインメモリデータベースRedisを、スケーラブルに状態を管理するための仕組みとして採用。アプリケーション全体で幅広く使用する。
・内部処理のほとんどは、RedisベースのキューマネージャBullで管理する。複数のアプリケーションにまたがる状態の永続性を維持するため。
❹ システムを起動すると、Insight GeneratorがIBM Cloud Code Engine上のアプリケーションに問い合わせ、4つの階層に整理されたアーティストの優先順位を示すリストを取得。
❺ 検索された記事は、Red Hat OpenShift上の「Extractive Summarization」(抽出型要約サービス)に送られ、IBM Watson Discovery(NLP機能)により最も特徴的なテキストが抽出される。
❻ この時点で、Insight Generatorにはすべての疑似事実(ファクトイド)や記事、抽出結果に関するメタデータが保存される。
◎ファクトの発見(インサイトの極性の測定)
❼ 抽出されたテキストがアーティストをどの程度サポートしているかを見つけるために、40万8000以上のIBM Project DebaterおよびLexisNexisののサンプルをBERTモデル(自然言語処理モデル)を使って学習させた。
❽ その結果得られたデータ(極性)は、IBM Cloudant NLP Storeに保存され、Redisで更新される仕組みとした。
➒ 高品質な疑似事実(ファクトイド)は、カテゴリごとにコンセプトタグが付けられる。
➓ IBM Natural Language Processingのカスタム・エンティティ検出システムであるStatistical Information and Relation Extraction (SIRE)がエンティティを生成。このエンティティは、余計なカテゴリをもつファクトをさらにフィルタリングするために使用し、残されたファクトは、対応するエンティティとともにIBM Cloudant NLP Store上で保持される。
⓫ ファクトが承認されると、生成されたJSONはIBM Cloud Object Storageにアップロードされ、⓬のIBM Content Delivery Network(CDN)でGrammy.com(⓭) へデータを送るための前処理がなされる。
上記のAIパイプラインは、6つのDockerイメージと54のポッドをもつ7つのアプリケーションで構成されている。これにより、1000人のグラミー賞ノミネート者全員に関するデータ抽出~インサイト発見を1時間以内に処理できたという。
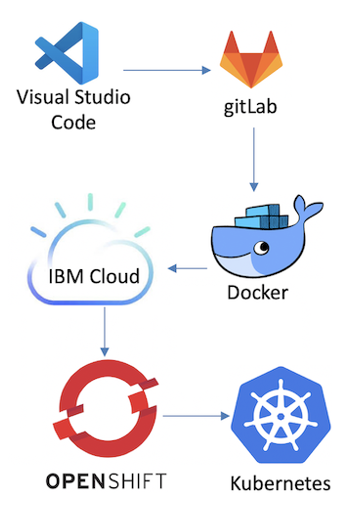
パイプラインはVisual Studio Codeで開発。コードの準備ができると、変更をコミットしてGitLabにプッシュ。デプロイメントランナーを実行して、GitLabマシン上でDockerイメージを構築し、Red Hat OpenShiftイメージリポジトリにプッシュ。そしてアプリケーションがイメージの変更を検出すると、新しいイメージはすべてのアプリケーション固有のポッドにロールアウトされ、RESTサービスとして利用できるようにルートで公開。変更のためのロールアウトは、現在のワークロードが中断されないように、カナリア方式でリリースされる仕組みという。
4月3日(日本時間4月4日朝7時~)にGrammy.comで生中継される第64回グラミー賞の授賞式は、世界の数千万人の音楽ファンが視聴すると見込まれている。IBMとアカデミーのチームは、レッドカーペットに登場するセレブやノミネート者にどのようなインサイトをフィードするか、万全の準備で待ち構えているという。
・ニュースリリース「IBMと全米レコード芸術科学アカデミーが第64回グラミー賞授賞式とアーティストページでWatsonを活用したファン体験を提供」(英語)
・技術者ブログ「Transforming data into insight at the GRAMMY Awards(グラミー賞におけるデータのインサイトへの変換)」(英語)
https://developer.ibm.com/articles/transforming-data-into-insight-at-the-grammy-awards/
[i Magazine・IS magazine]







