今回はSQLについて話していきます。
SETLL READE CHAINといったDBアクセスに慣れ親しんでいるRPGプログラマーにとっては、なかなかとっつきにくいイメージがあるのがSQLではないでしょうか。一方、オープン系の世界ではその真逆で、SQLが標準です。私は個人的にはRPGでもSQLを使用することをお勧めします。IBM iでは組み込みSQLを使って、RPGプログラム内でSQLを使用することが可能です。
お勧めの理由として、次の4つが挙げられます。
1.抽出条件により使用するLF(論理ファイル)を意識しなくてよい
一般的な抽出処理では、抽出条件の項目によって使用するLFを使い分けますが、その結果、条件によるLFの選択処理が発生し、プログラムが複雑になってしまいます。
SQLではWhere文を動的に記述することで、「Db2オプティマイザー」なるものが、抽出条件によって最適なLF(インデックス)を選択してくれます。
*最適なインデックスがない場合は一時インデックスを作成しますので、索引アドバイザーを利用して必要なインデックスを作成することが処理速度の向上には不可欠です。索引アドバイザーについては別の機会でお話したいと思います。
2.処理に付随するマスタからの情報を一度の処理で取得できる
たとえば、売上データを読んで、商品コードから商品マスタを読み、商品名を取得する処理では、売上ファイルをREAD(READE)し、売上ファイルの商品コードをKeyにして商品マスタをCHAINするのが、通常のRPGでの処理です。一方、SQLでは商品マスタをJOINすることでSQLの結果データに商品マスタの情報がセットされるので、プログラムがシンプルになります。
3.抽出処理の精度が上がる
複雑な抽出処理では、Key指定で抽出できる処理に限界があります。メインとなるkeyで抽出を行い、そのほかの抽出においては項目の比較により読み飛ばしを実施する必要があります。
ロジックが入ることで、バグの元となります。SLQではWhere文のところをしっかり確認すれば、上記に比べてバグの発生率は低くなります。
4.DBのアクセス処理が速い?
昔何かの記事でREAD、CHAINよりも処理が速いと見た記憶があります。実際に計測したことはありませんが、これが事実であれば、よいに越したことはありません。
しかし、とは言ってもSQLを覚えるのは難しそうだ、と思われるかもしれません。
実はSQLは、IBM iプログラムにとっては非常に馴染みが深いのです。
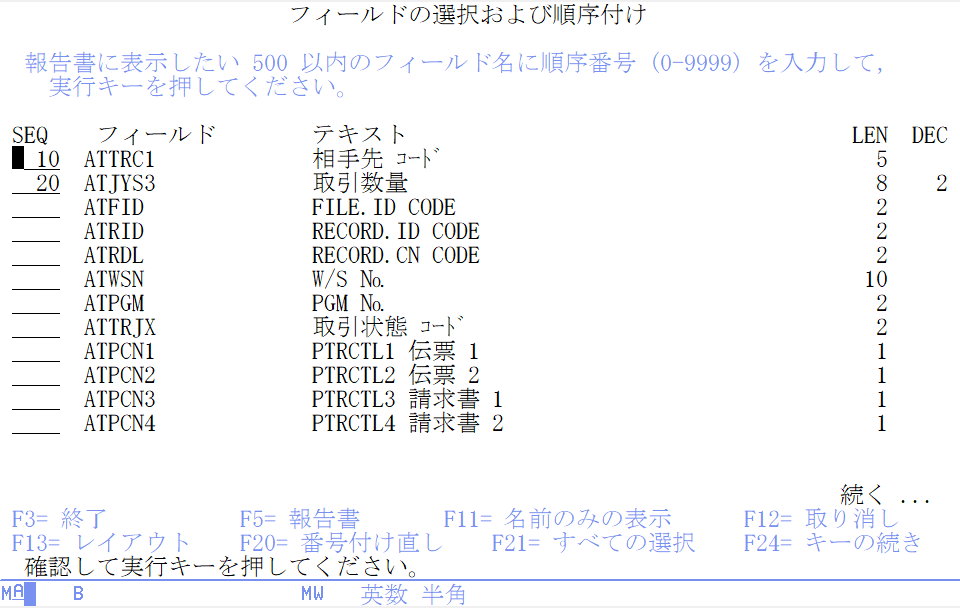
Query(WRKQRY STRSQL)をよく使う方なら、基本的なSQLを習得することは簡単です。SQLは、簡単に言えば以下のような書き方です。
① SELECT ATTRC1,SUM(ATJYS3)
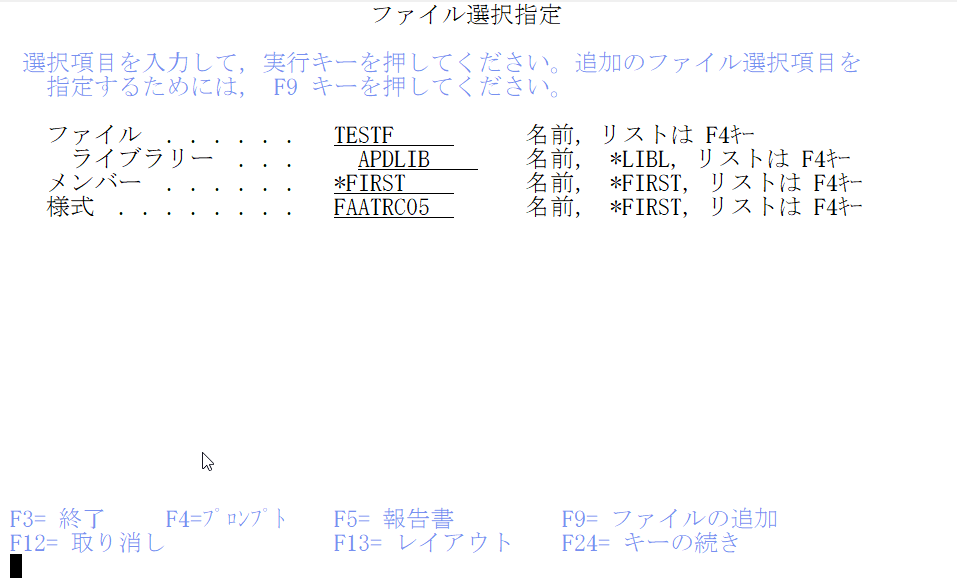
② FROM APDLIB/TESTF
③ WHERE ATTKB1 = ‘3’
④ GROUP BY ATTRC1
⑤ ORDER BY ATTRC1
各処理をQueryに置き換えると
① フィールドの選択および順序付け