Text=鮎川 徹志 日本アイ・ビー・エム システムズ・エンジニアリング
OpenShift基盤の監視方法
アプリケーションやサービスのスピーディな提供や改善によるビジネスの競争力強化や差別化が注目される中、モダナイゼーションやDXの推進手段として、クラウドネイティブ技術を有効活用するアプローチに期待が高まっている。
Cloud Native Computing Foundation (以下、CNCF)のクラウドネイティブの定義にも記載があるように(CNCF Cloud Native Definition v1.0 日本語版) 、コンテナ技術はクラウドネイティブを実現するアプローチの代表的な技術要素であり、コンテナ技術やオーケストレーションツールのKubernetesは、すでに多くの企業で導入されている。
また、コンテナ実行環境としてはマルチクラウド、ハイブリッドクラウド環境での利用が増加傾向にある。
「Red Hat OpenShift Container Platform 」(以下、OpenShift)は、現在多くのクラウドプロバイダーからマネージドのOpenShiftサービスとして提供されている。
たとえば、「Red Hat OpenShift on IBM Cloud」 (ROKS)、「Red Hat OpenShift Service on AWS」 (ROSA)、「Azure Red Hat OpenShift」 (ARO)、「Red Hat OpenShift Dedicated」などがある。
これらのマネージドサービスを利用すると、クラスターの管理自体をクラウドプロバイダー側に任せ、ユーザーはアプリケーションの開発に集中できるメリットがある。
一方で、セキュリティやパフォーマンスの観点からオンプレミス環境を継続する企業も多い。その場合でも、ビジネスニーズへの迅速な追従や機能追加など、サービスのアジリティを上げるために、オンプレミス環境にOpenShiftを導入し、アプリケーションをコンテナ化して使用するケースが増えている。
今回は、そのようなエンタープライズ企業によるオンプレミスのOpenShift基盤構築の事例から、OpenShiftが提供するロギングやモニタリングの機能を用いたOpenShift基盤の監視方法など、実際の案件で得られた知見や工夫の一例を紹介する。
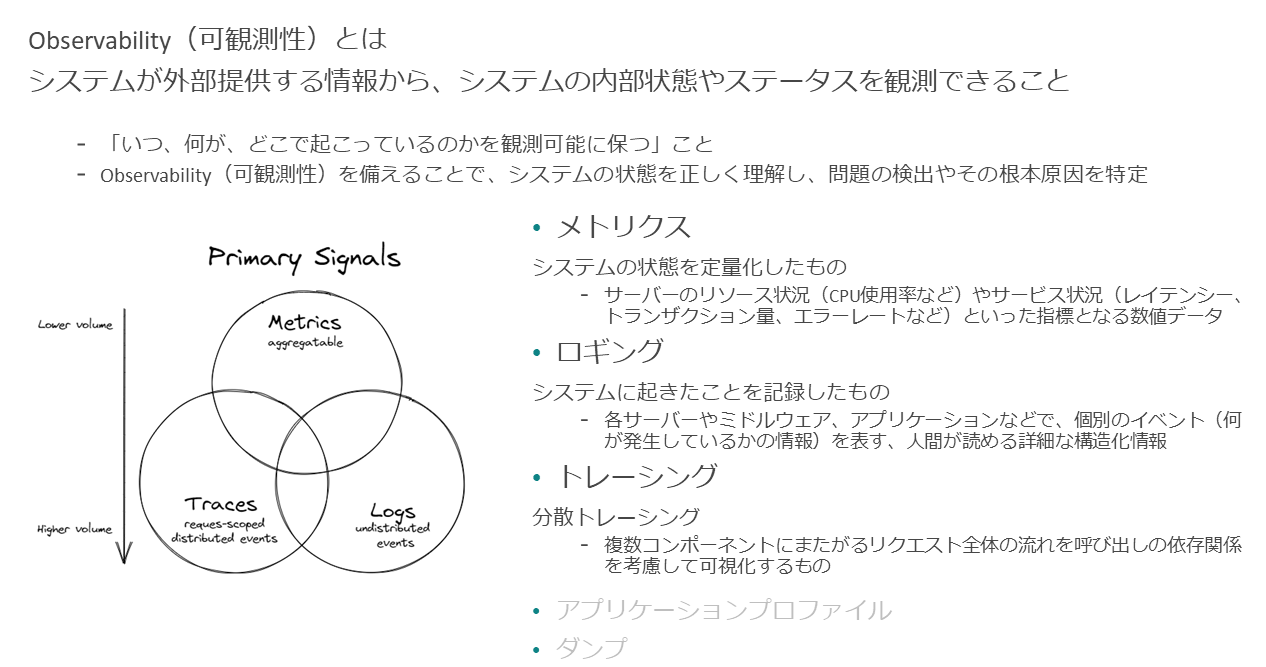
Observability-可観測性を高める重要なシグナル
メトリクスとロギング
Observabilityは、日本語では可観測性と言う。可観測性とは、「システムが外部提供するメトリクスやログといった情報から、システムの内部状態やステータスを観測できること」となる。言い換えると、「いつ、何が、どこで起こっているのかを観測可能に保つこと」である。
Observabilityを備える、または高めることで、システムの状態を正しく理解し、何か問題があったときに問題の検出や根本原因の特定などを迅速に行えるようになる。
Observabilityの定義、およびObservabilityを高めるための指針やシグナルは、CNCFが提供するホワイトペーパーに記載されている(Observability Whitepaper) 。
その中でも重要なシグナルとして、メトリクス、ロギング、トレーシングといったものがある。そのほかにもいくつかシグナルがあるが、目的はいずれもユーザーシステムの可観測性を高めることである。目的を達成できるなら、必ずしもすべてのシグナルを実装する必要はない。本稿では主にメトリクス、ロギングに絞って解説する。
OpenShiftに搭載された
Observabilityを高める機能
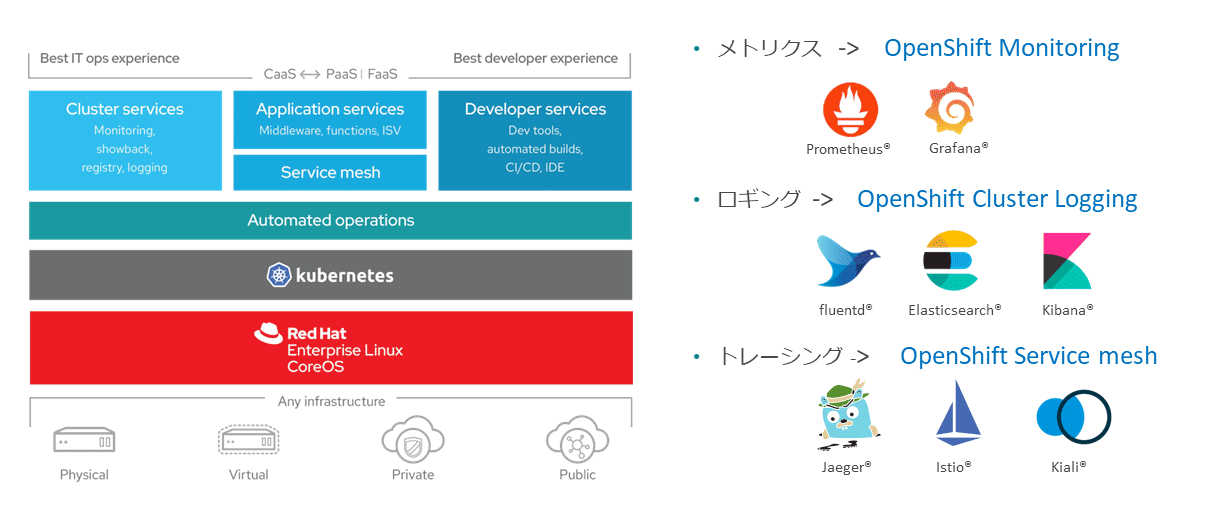
OpenShiftでは、Observabilityを高める機能が標準搭載されている。
たとえばメトリクスであれば、OpenShift Monitoring Operatorを利用し、Prometheusによりメトリクスを収集し、Grafanaにより可視化できる(OpenShift4.11ではGrafanaは廃止され、OpenShiftコンソールに統合されたUIからメトリクスを可視化できる)。
またロギングでは、OpenShift Cluster Logging Operatorを利用し、fluentdによりログを収集し、Elasticsearchで保管し、Kibanaにより可視化できる。
このようにOpenShiftではメトリクス、ロギングなどのそれぞれのシグナルごとに、CNCFでホストされている代表的なオープンソースがそのままOpenShiftの中に取り込まれており、サポート付きで利用できる。
これらのクラウドネイティブな監視のスタックを使って、OpenShiftのObservabilityを高められる。
エンタープライズ企業の監視運用
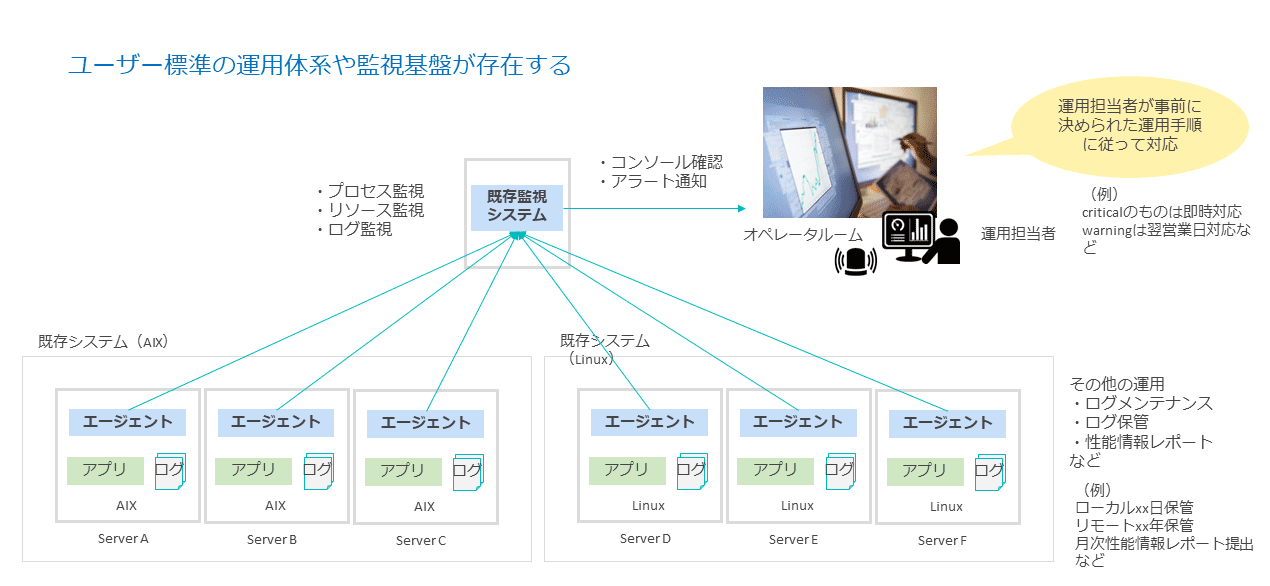
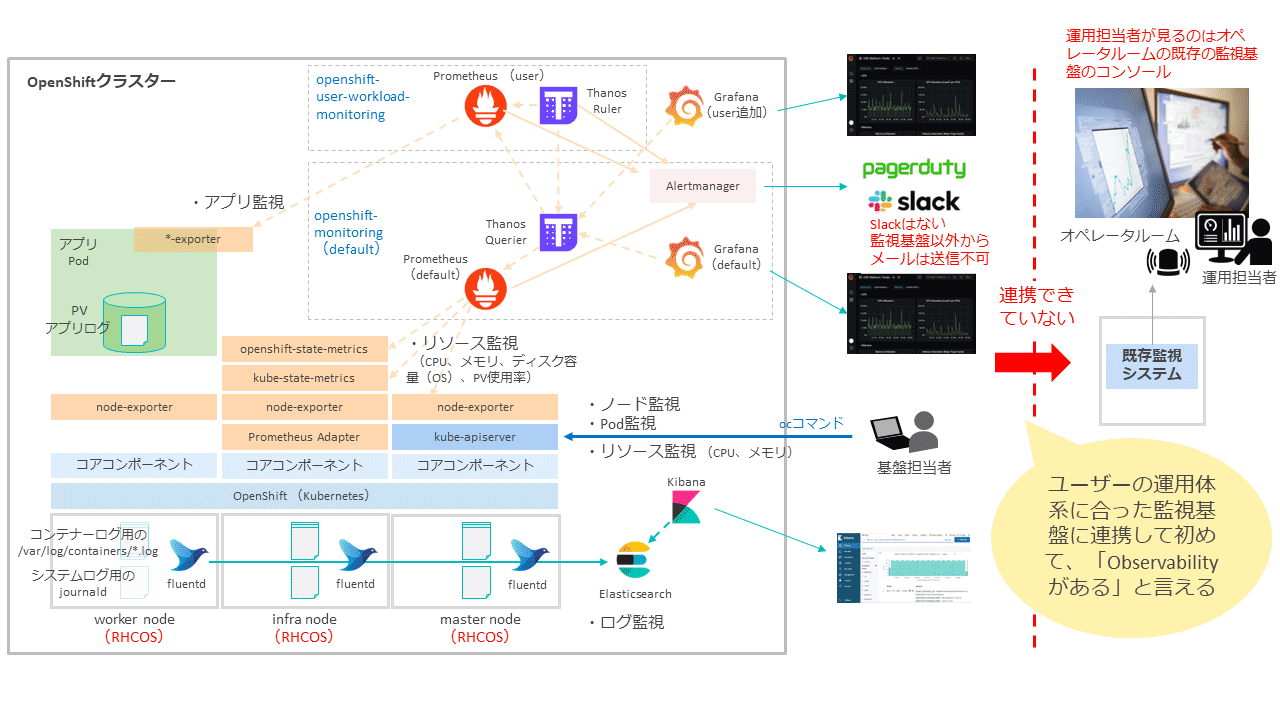
一方、エンタープライズ企業では、ユーザー標準の運用体系およびモニタリングやロギングの監視基盤がある。
従来の監視の場合は、監視対象のサーバーに既存監視システムのエージェントを静的に導入し、プロセスやシステムリソース、ログを監視する。
データセンターのオペレータルームで運用担当者が既存監視システムのコンソールを確認、もしくは通知されたメールを見てアラートを確認し、重大(Critical)なアラートがあった場合は即時対応として一次情報を取得する。警告(Warning)であれば、翌営業日に対応するといったように、運用担当者が事前に決められた運用手順に従って対応する。
前述したようにOpenShiftには標準搭載されたモニタリング、ロギングの機能がある。ただし、それを利用するだけでは、ユーザーにとって必ずしもObservabilityが十分高い状態とは言えない場合がある。
ユーザー標準の既存運用体系や監視基盤がある場合には、OpenShiftのモニタリング、ロギングで監視した情報を、ユーザーの運用体系に合った監視基盤に連携して初めて、「ユーザーにとってObservabilityが高い状態」と言える。
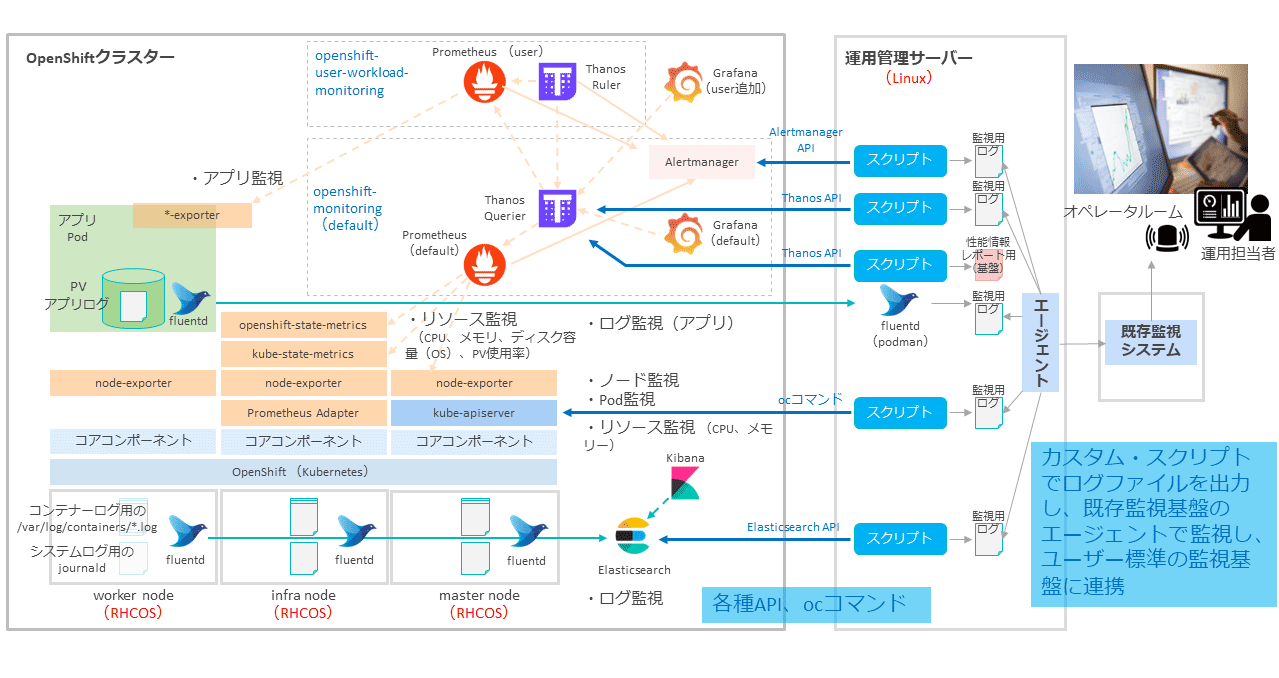
このギャップを埋める方法の一例として、運用管理用のLinuxサーバーを用意し、この運用管理サーバー上でocコマンドやOpenShiftの各種コンポーネントのAPIを経由してメトリクスやログ情報を取得し、監視用ログファイルを出力するカスタムスクリプトを作成する方法がある。
カスタムスクリプトが出力する監視用ログファイルを、既存監視基盤のエージェントで監視することで、ユーザー標準の監視基盤に連携できる。
このようにして、ユーザーの既存運用体系をそのまま使用してOpenShift基盤のObservabilityを高められる。
以下に、OpenShift基盤の監視項目と監視方法の概要について記載する。
モニタリング―監視項目と監視方法
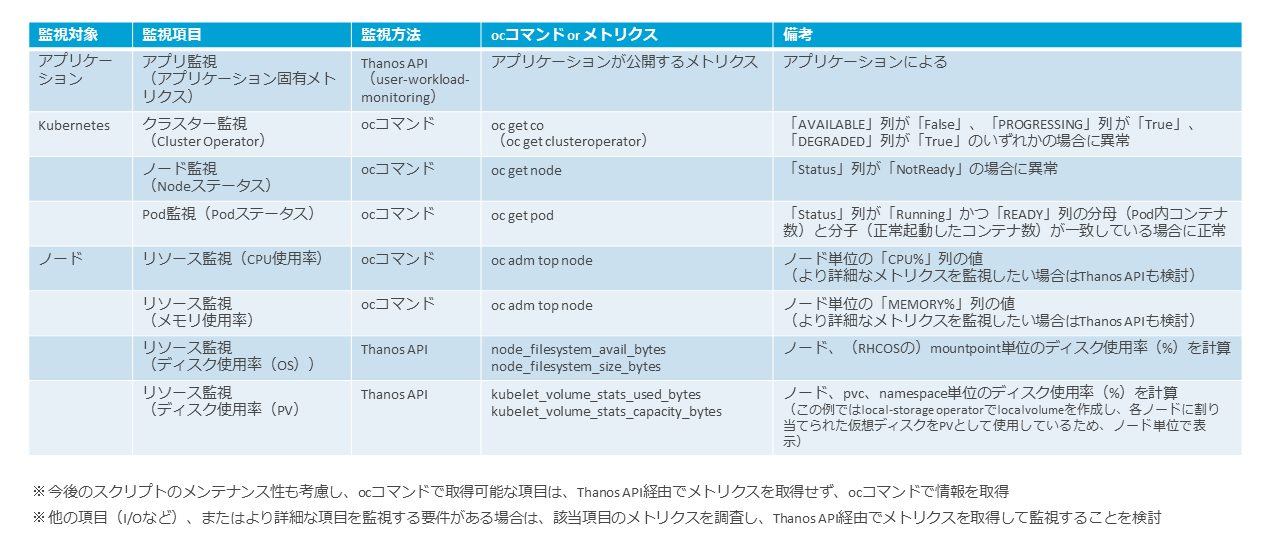
監視対象は大きく分けてアプリケーション監視、Kubernetes監視、ノード監視の3つのレイヤーに分けて検討する。
アプリケーションレイヤーでは、アプリケーションが公開する固有のメトリクスがある場合はそれを監視する。
Kubernetesレイヤーでは、クラスターの状態の監視としてCluster OperatorやNodeステータスを監視する。また、Podの状態も監視する。ディスク使用率(PV)もこのレイヤーで監視する。
ノードレイヤーでは、ノードのCPU使用率、メモリ使用率、ディスク使用率(OS)などのリソース使用状況を監視する。
これらの情報を取得して、監視用のログファイルを作成するカスタムスクリプトを作成する。スクリプトの作成方針は、今後のメンテナンス性も考慮して検討する。
たとえば、以下のように方針を検討する。
・ocコマンドで取得可能な項目は、ocコマンドで情報を取得する
・ocコマンドで取得できない項目は、Thanos API経由でメトリクスを取得する
・その他のより詳細な情報を監視する要件がある場合は、該当項目のメトリクスを調査し、Thanos API経由でメトリクスを取得する
図表6は、モニタリングの監視項目である。
まず、ocコマンドで取得した情報から既存の監視エージェントで監視可能な形式のログファイルを作成するイメージは、図表7のようになる(青字の点線の部分にある情報を取得/整形し、監視用のログファイルを作成)。

次に、Thanos API経由でメトリクスを取得して監視する場合の流れは、図表8のようになる。
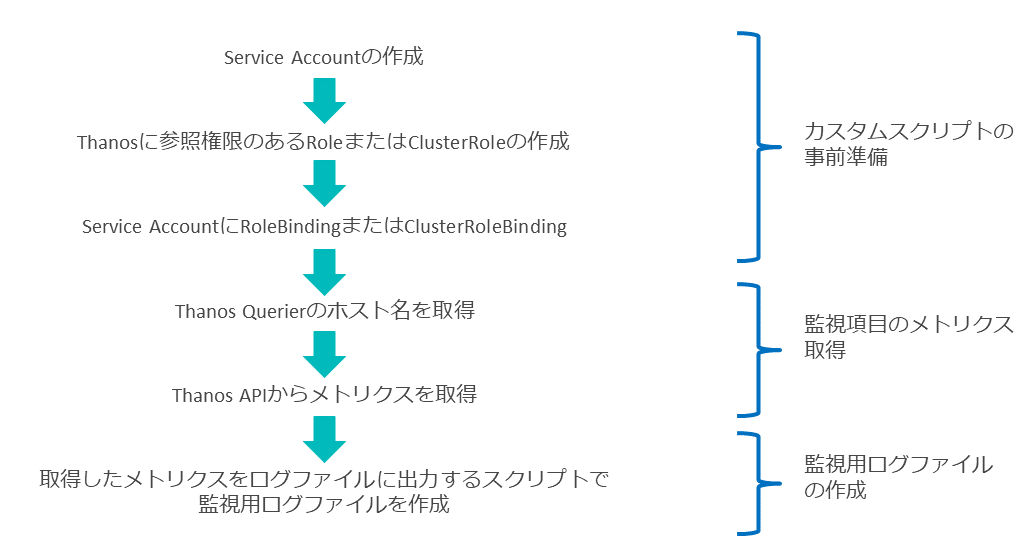
カスタムスクリプトでは、ある閾値を超えたものをSeverityがWarningやCriticalでログとして出力させる。
また、1回閾値を超えるだけではアラートを発行せずに、直近5回中3回、閾値を超えたらCritical/Warningのログを出力する、などの詳細な監視要件がある場合は、スクリプト側で対応するか、既存監視システム側の設定で対応するかなどの実装方法も検討する。
これらの作成したカスタムスクリプトを、cronまたはジョブスケジューラなどで定期的(1分間隔など)に実行させ、監視用のログファイルを作成する。
そして、アプリケーション固有のメトリクスを監視する場合は、ユーザー定義ワークロード・モニタリングを有効化して、アプリケーションが公開するメトリクスを監視できる( OpenShift 4.11 / モニタリング / 5. ユーザー定義プロジェクトのモニタリングの有効化)。
ユーザー定義ワークロード・モニタリングを有効化すると、 作成されたユーザーワークロード用のPrometheusのインスタンスで、アプリケーション固有のメトリクスを取得できる。これらのメトリクスは、デフォルトのクラスターモニタリングのThanos API経由で取得できる。
ここまで準備すると、アプリケーション固有のメトリクス情報も図表8と同じ流れで取得して、監視用ログファイルを作成できる。
補足として付け加えるなら、OpenShiftのクラスターモニタリングの機能では、Alertmanagerでアラート監視することもできる。事前定義されたアラートルールに従って発行されたアラートは、AlertmanagerのAPIを利用して取得することもできる。こちらも必要に応じて利用を検討する。
ロギング―監視項目と監視方法
図表9は、監視対象となるログである。
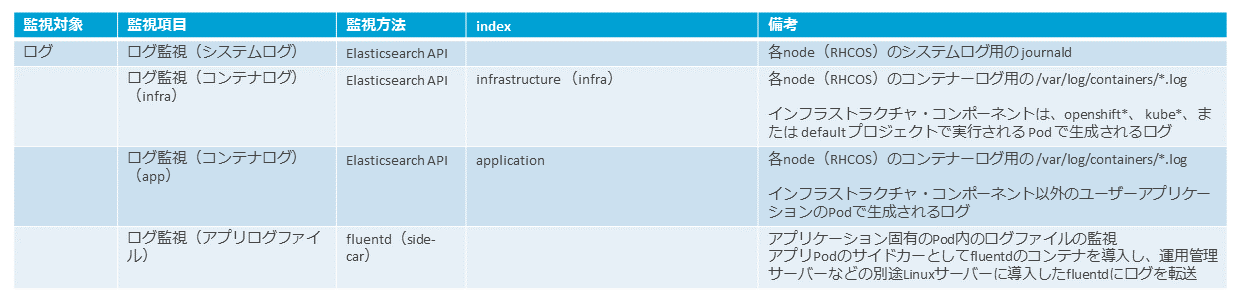
OpenShiftのロギングとしてEFKスタック(Elasticsearch、Fluentd、Kibana)を使用する場合は、各ノードにdaemonsetとして導入されるfluentdが、各ノード(RHCOS)のシステムログ(journald)とコンテナログ(/var/log/containers/*.log)を監視し、Elasticsearchで保管し、Kibanaで可視化できる。
OpenShiftのロギングで提供されるElasticsearchには、自分自身でアラートを通知する機能はないため、OpenShiftのログを監視する場合は、何らかの方法でユーザーの監視基盤に連携する必要がある。
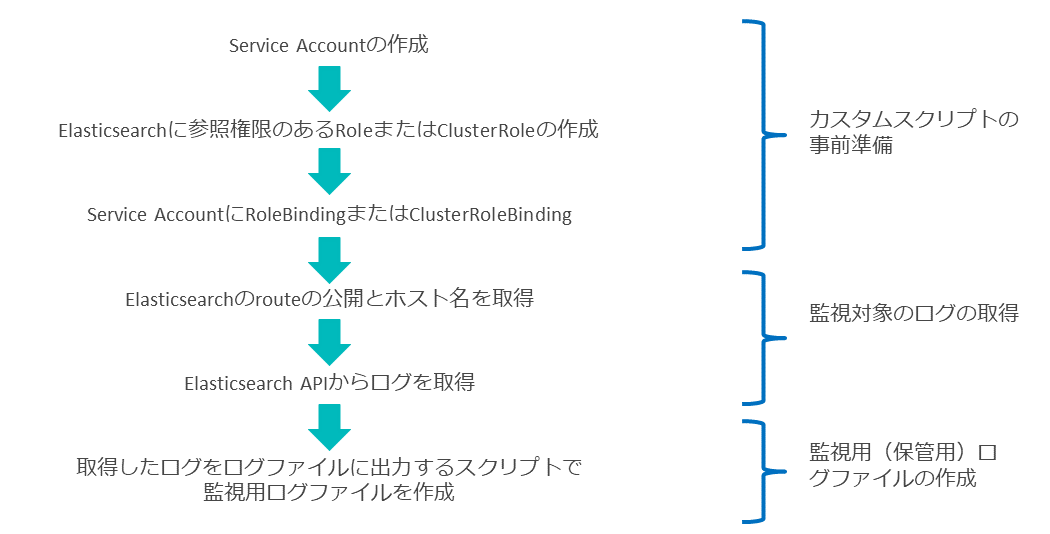
実装方法の一例としては、モニタリングの場合と同様に、運用管理サーバー上のカスタムスクリプトから、Elasticsearch API経由でログを取得して監視用のログファイルを作成し、これを既存監視エージェントで監視する方法などが考えられる。
またElasticsearchはログの長期保管には適さないため、ユーザー要件でログを長期保管するような要件がある場合は、カスタムスクリプトで作成したログファイルを別の場所に保管することなどを検討する。
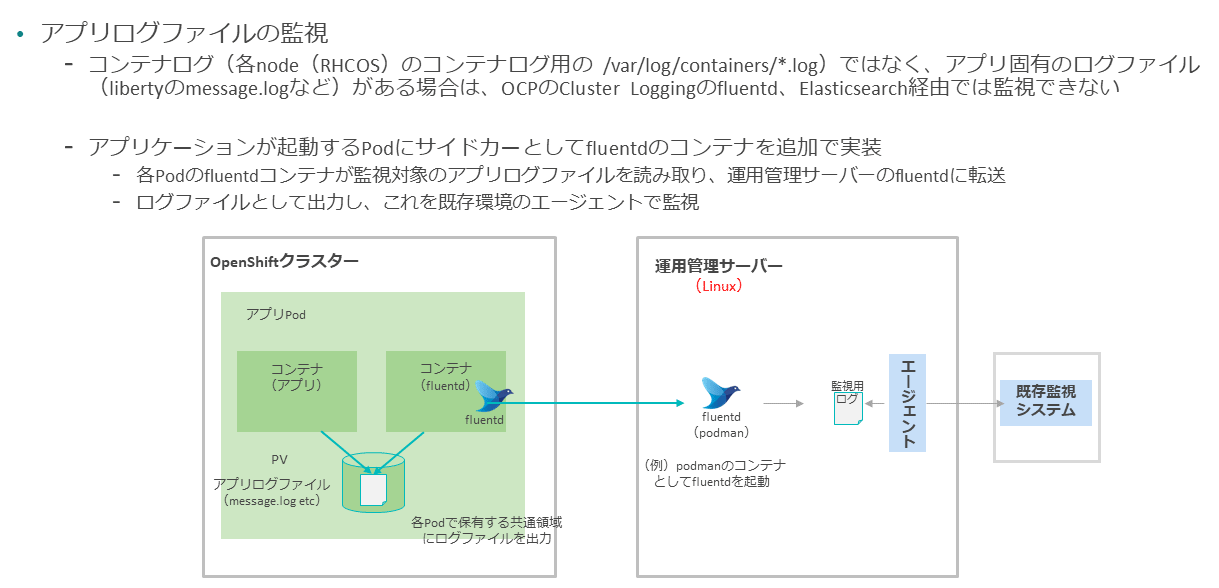
アプリケーションコンテナのログとは別に、Pod内にアプリケーション固有のログファイルが存在し、これも監視する必要がある場合は、OpenShiftのロギングの機能では対応できない。
この場合は、たとえばアプリケーションPodのサイドカーとしてfluentdコンテナを導入し、別途運用管理サーバーなどに導入したfluentdにログを転送することで、ユーザーの監視エージェントで監視できる。
Observabilityを高めるために、OpenShiftが提供するモニタリングやロギングの機能を活用できるが、エンタープライズ企業では既存の運用体系や監視基盤があるため、OpenShiftで監視した情報をこれらの既存運用に連携する考慮が必要となる。
本稿ではこれらを実現する工夫についての一例を紹介した。こうすることで、ユーザーは安心してOpenShift基盤を活用できる。
一方で、将来的には既存の監視運用体系自体を、運用体制やプロセスも含めてクラウドネイティブな監視運用体系へシフトすることを検討する場合は、継続運用する中で、OpenShiftのモニタリング、ロギングの機能をより積極的に活用することを検討する。あるいはクラウドネイティブな環境に特化したObservabilityを高めるソリューション(「IBM Cloud Pak for Watson AIOps」や「IBM Instana Observability」など)を採用することも1つの選択肢となる。








