Text=藤野 大地、板場 幹夫(日本アイ・ビー・エム システムズ・エンジニアリング)
インフラエンジニアの現状
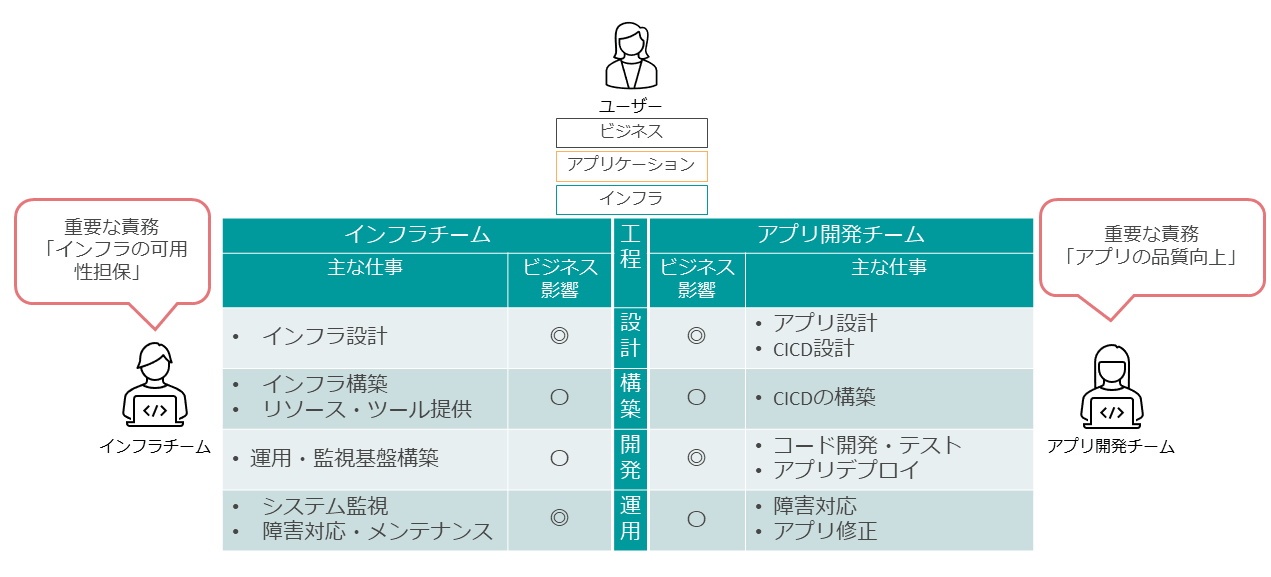
一般的なプロジェクトでは、インフラチームとアプリ開発チームは別々に分かれている。ユーザーのビジネス、ビジネスを実装するためのアプリケーションがあり、そのアプリケーションを運用するためのインフラがある。
インフラチームもアプリ開発チームも、それぞれのスコープに対して設計構築、開発、運用を進めていく。ユーザーのビジネスへの影響を軸にして、それぞれの役割と責務をどのように定義すべきであろうか。
インフラチームの重要な責務の1つとして、「インフラの可用性担保」を挙げられる。具体的には、システムの運用フェーズでシステム運用を監視し、利用状況を見ながらリソースを拡張したり、障害が発生した場合は迅速に復旧させるべく対応する。
一方、アプリ開発チームの重要な責務は、「アプリケーション品質の向上」である。開発フェーズでコードの開発・テスト・レビューを繰り返し、要件を満たしつつ、バグの少ないアプリケーションを開発する。
両方とも重要な責務であるが、ここではユーザーからの期待値という目線で考察してみよう。
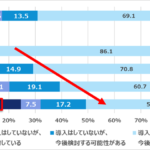
インフラというのは、すでにユーザーに導入されており、それを更改していくパターンが多い。更改前のインフラと比べて品質を維持しつつ、さらに効率化を進めることが期待値となる。効率化が成し遂げられると、リソースや担当要員を減らしてランニングコストを抑えようとする。
一方、アプリケーションへの期待値はというと、アプリケーションはインフラに比べると、ユーザーのビジネスの近くに位置しているため、ビジネス拡大に貢献することが期待される。この期待値は、アプリケーション開発への投資額につながる。
このような状況では、効率化を突き詰めることだけがインフランジニアの役割である限り、その存在感はこの先、希薄になっていくのではないかという懸念がつきまとう。
インフラエンジニアのやるべきこと
インフラエンジニアの役割を変革する、あるいは期待値を高めるような仕事とは何だろうか。
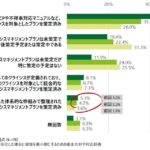
まずインフラチームの責務として、アプリケーション品質向上に向けた仕組みを新たに提供することが挙げられる。具体的な内容は後述するが、DevOpsライフサイクルの設計・構築をリードする役割を担い、DevOpsのための運用監視をインフラ側から主導していくことである。
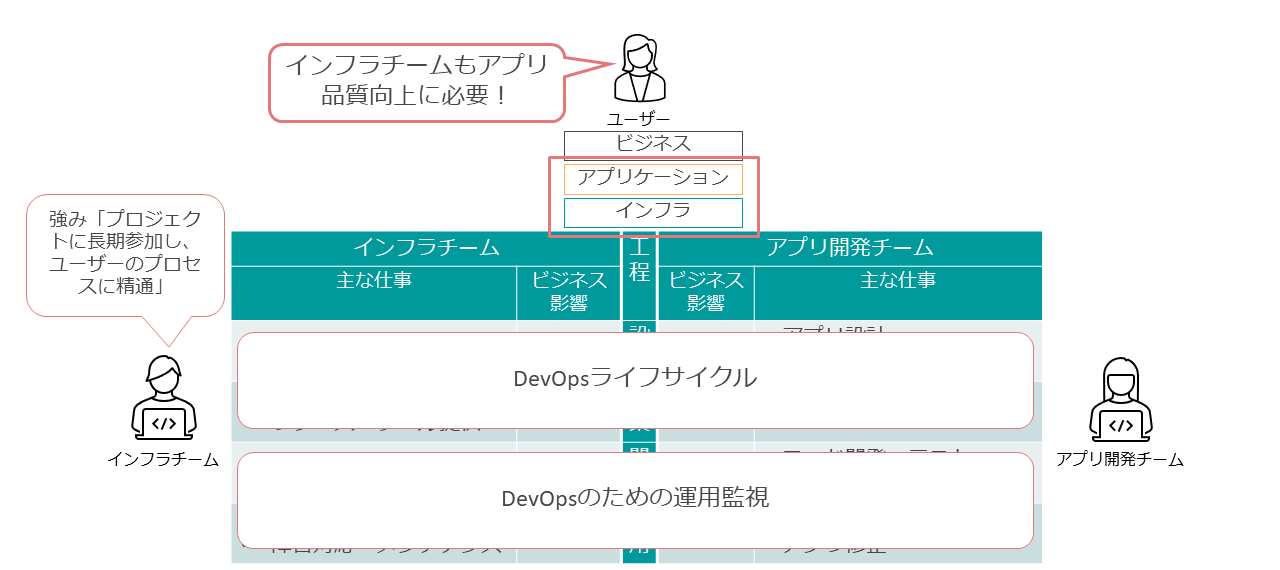
これはインフラチームだけに閉じた話ではなく、アプリケーション開発チームの担当者と協業しながら進める必要がある。
DevOpsライフサイクルでのインフラチームの強みは、アプリ開発チームに比較すると、長期にわたりプロジクトに参加するメンバーが多いこと、すなわちユーザー側のプロセスに精通した担当者が多く存在することである。
DevOpsライフサイクルとはプロセス改善であり、ユーザーのプロセスに精通していることがインフラチームの強みとなる。インフラチームがリードすることで、ユーザーの視点ではアプリケーションとインフラが一緒にビジネスを支えている形になる。これによって、ユーザーからのインフラチームに対する期待値を高めていけるのではないだろうか。
DevOpsライフサイクルの概要
図表3は、IBMが定義しているDevOpsサイクルの概要である。
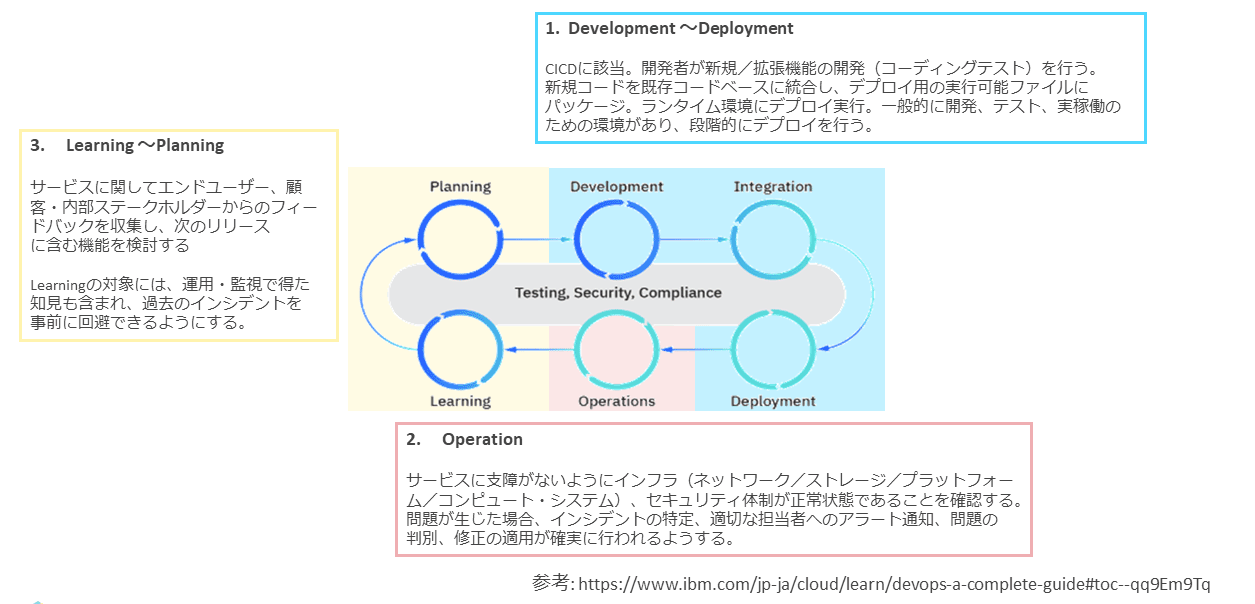
DevOpsライフサイクルを一言で言うと、高品質なアプリケーションを迅速に提供するための反復型の開発ワークフローである。
6つのフェーズから形成され、これを回転する形で進めることをDevOpsライフサイクルという。
「デベロプメント(Development)」「インテグレーション(Integration)」「デプロイメント(Deployment)」の3つのフェーズでは、アプリケーション開発チームがCI/CD手法を用いる場合が多い。具体的には、アプリケーションのコードはGitHubなどのリポジトリで管理され、リポジトリでコードに変更が発生すると、自動でコードをビルドしてアプリケーションをデプロイする。
次の「オペレーション(Operation)」は、デプロイしたアプリケーションの運用保守監視である。ここではインフラエンジニアが主役となり、アプリケーションが安定的に稼働するよう、インフラが正常状態であることを保証する。
万一障害が起きた場合は、適切な担当者へアラートを通知し、問題判別と修正が確実に行われるようにする。
次は、「ラーニング(Learning)」と「プランニング(Planning)」である。アプリケーションに関してエンドユーザー、ユーザー、内部ステークホルダーからのフィードバックを収集して、次のリリースに向けた機能を検討する。
「ラーニング」の中には、運用監視の結果も含まれている。発生した過去のインシデントを学習して、次のリリースでは事前に回避する役割をインフラエンジニアが担う。
以下に、実装例を踏まえて説明しよう。
DevOpsライフサイクルの実装例
DevOpsライフサイクルを身近なツールを用いて実装検証した環境に、ステークホルダーを仮定した例を紹介する(図表4)。
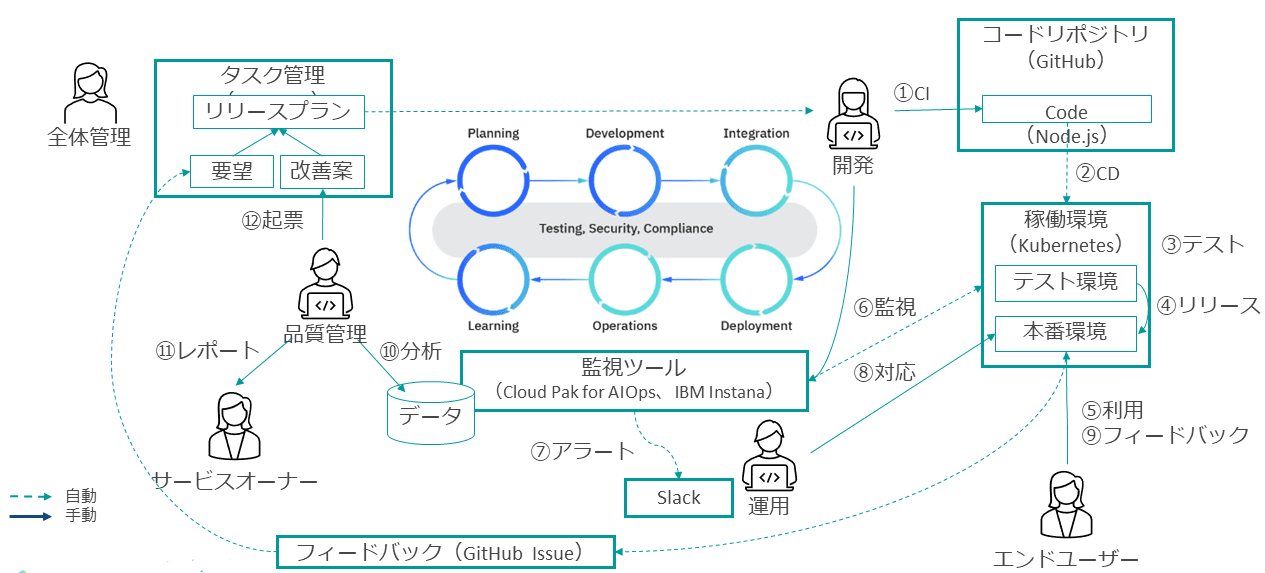
最初は「デベロップメント」と「インテグレーション」で、開発者が自身のPCでコーディングする。その後、コードをGitHubにコミットし、それをトリガーに「デプロイメント」が行われる。
テスト環境にアプリケーションがデプロイされると、本番環境のデプロイに備えて一通りのテストが実施される。
テストを通過したら、エンドユーザーが利用できる本番環境にリリースする。 ここまでが、「デベロップメント」から「インテグレーション」「デプロイメント」までの流れとなる。
次に「オペレーション」では、ツールにより監視し、障害が発生するとアラートを通知する。この事例では、Slackに自動通知するようにしている。通知を受けた運用担当者が修正/復旧作業を行う。
次に、「ラーニング」「プランニング」のフェーズになる。ここでは利用者からのフィードバックが重要となるので、なるべく多くのフードバックを得るべく、Webアプリケーションの中に追加のページを開発して、利用者がフィードバックをつけられるようにする。
実際にユーザーが5段階評価とコメントを記載するページを作成し、コメントを保存するとGitHub Issueにレビュー結果が登録されるようにした。GitHub IssueをRedmine に連携し、自動的に評価を収集していく形にしている。
この収集結果を評価するのが、「ラーニング」のフェーズとなる。さらに品質管理では、品質を担保する役割を担うインフラエンジニアは、監視ツールでインフラとアプリケーションの監視結果をKPIデータとして収集・分析して報告する。
必要に応じて、次のリリースに含まれるべき改善案をRedmineにチケットとして起票する。次のリリースプランには、全体管理を担うメンバーがリードして、具体的にどのようなリリースを実行するかを計画していく。
この計画は、アプリケーション開発チームと運用を担うインフラエンジニアのチームが共同で検討していく。これをサイクル化して回していくことが、DevOpsライフサイクルとなる。
DevOpsのために必要な運用とは
では次に、DevOpsに求められる運用について技術的な側面から考察する。
DevOpsでは、今まで慣れ親しんでいた運用管理とは異なる運用が必要となる。 変化が求められる主な要因について、以下の3つ挙げていきたい。
1つ目は複雑さに起因する。近年、KubernetesやOpenShift環境で採用が進んでいるマイクロサービスというアプリケーションの実装形態が拡大している。アプリケーションを構成する要素が多数の物理資源に分散して構成されるので、そのアプリケーショ資源の使用状況が、動的に変動する可能性がある。そのため、不具合が発生した時の発生箇所を特定することが困難になっている。
2つ目は速度に関する理由である。DevOps環境ではCI/CD開発手法とツールが用いられ、アプリケーションの変更を次々とリリースできる。あるリリースで、パフォーマンスの悪化などアプリケーションの動作状態がよくない場合、不具合がどこに起因しているのかを早急に判断しないとDevOpsの開発の進行を阻害する要因となる。アプリケーションの健全な動作について、何をもって健全であるかを定義し、それに照らして動作状態を迅速かつ的確に評価する必要がある。
3つ目はコミュニケーションの問題である。インフラに詳しくないアプリケーション開発者と、アプリケーションの内部処理を把握していないインフラエンジニアがDevOpsでは相互に連携し、障害を特定して問題解決を図る必要がある。その際に、どのようにコミュニケーションを取ればよいのかという課題がある。
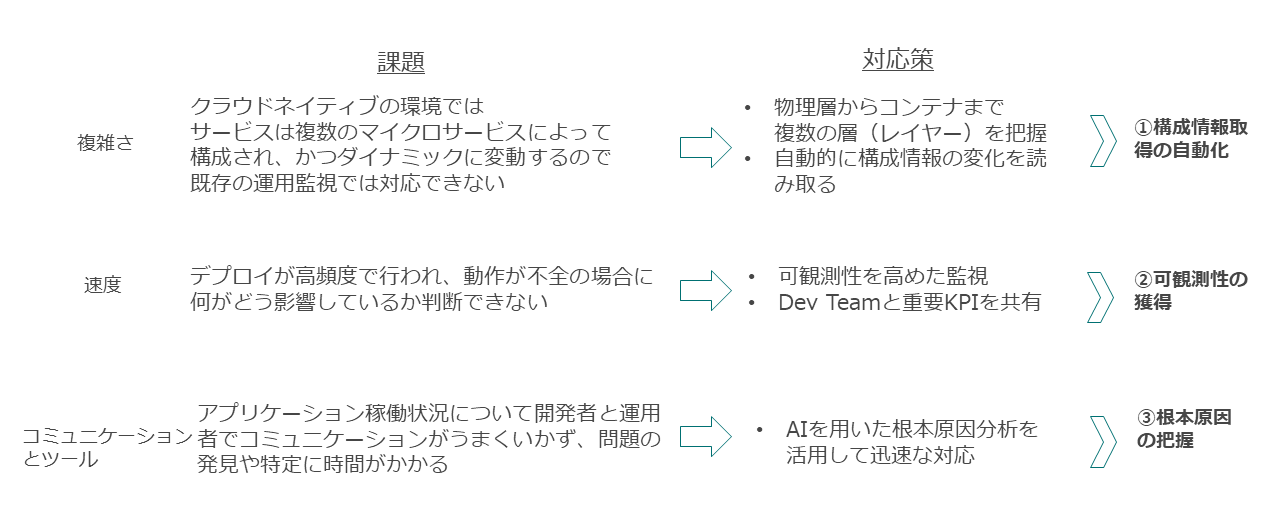
1つ目の複雑さ、つまり構成情報の取得に向けた対策についてであるが、アプリケーションがどのように構成されているかについて情報を収集する点は従来と変わりない。ただし対象が動的に変化するため、手作業だと間に合わなくなる。そのため変動時、あるいは定期的に自動収集して、わかりやすく提示するツールが必要となる。
2つ目の速度、つまり健全性の確認という点についてであるが、アプリケーションが稼働したときのインフラ状況を、可能な限り観測していく必要がある。何について、どのように観測するのか、いかに効率よく観測するのかが重要になる。これは「可観測性の獲得」と定義して、後述する。
3つ目のコミュニケーションについてだが、アプリケーションかインフラスか、どちらに問題があるのか把握できないときに、さまざまな情報を統合しながら分析してある程度、根本原因を絞れるような仕組みを使うことが鍵となる。この仕組みをアプリケーション開発者とインフラエンジニアが共有して共通の理解を高めることで、問題の特定を早められる。
構成情報取得の自動化
アプリケーションは、さまざまなレイヤー(領域)を跨いで構成されている。従来の監視だと、レイヤーごとに専用の体制/チームを組んで監視していくのが定番であったが、アプリケーションが稼働する構成が動的に変化する場合、領域ごとに構成情報を作成しても、すぐに実態と合わなくなる。
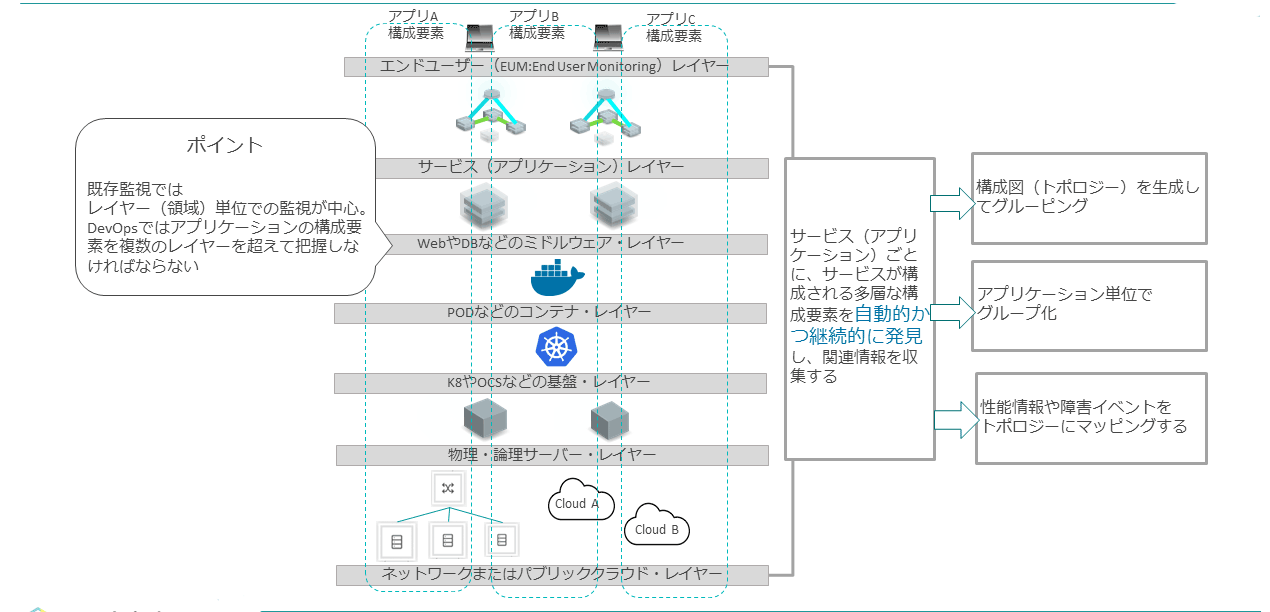
また変化した情報を連携し合うために必要なプロセスも、オーバーヘッドとなる。そこで、アプリケーションごとに各レイヤーを横断する形で、 構成要素を把握する必要がある。アプリケーションごとに、どんな資源をどう使っているのかを自動的に収集するのが重要なポイントとなる。
実装例として、IBM Instana(以下、Instana)という製品を取り上げる。
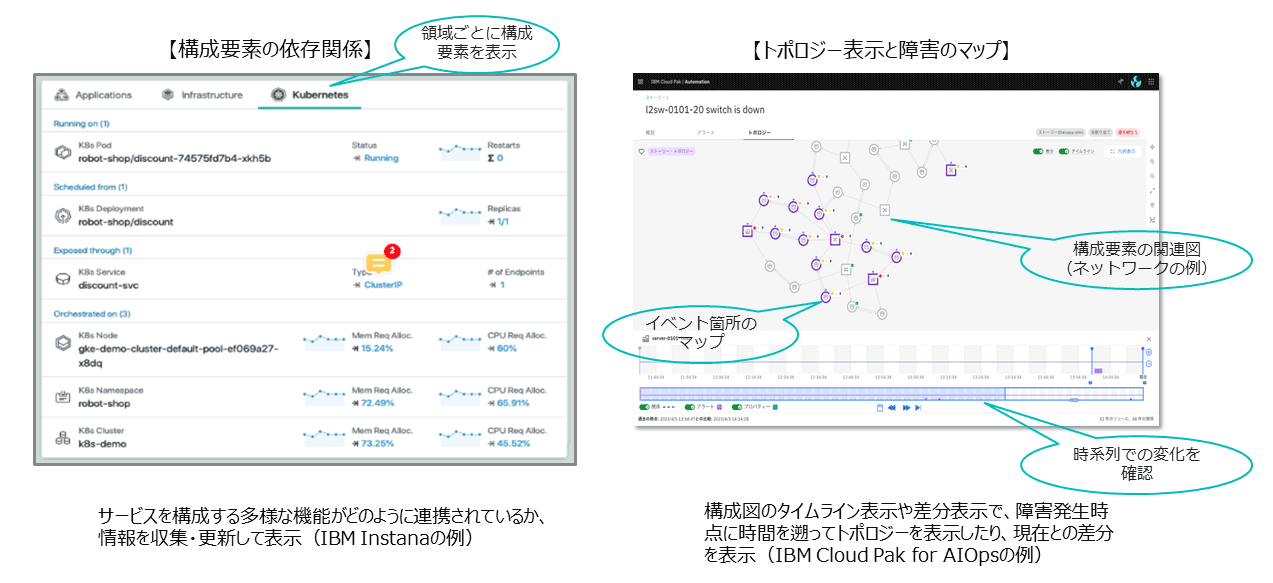
図表7の左側にあるように、Instanaではアプリケーション、インフラ、Kubernetesと画面のタブが分かれており、アプリケーションごとにレイヤーを整理していくこ とで、何がどう関連しているのかをわかりやすく確認できる。
もう1つの例は図表7の右側にあるように、IBM Cloud Pak for AIOpsという製品である。個々の構成の依存関係などを解析して、構成図として描画する。その構成図を地図のように用いて、障害が発生した箇所をマーキングできる。アプリケーション障害に関して、どのような構成要素が影響しているかを即時に情報提示できる。
可観測性の獲得
可観測性はObservabilityの日本語訳で、システムの状況を数値化したり、数値を分析することでシステムの状況を客観的に把握することを意味している。
可観測性のポイントは3つある。分散トレース、メトリック、ログである。
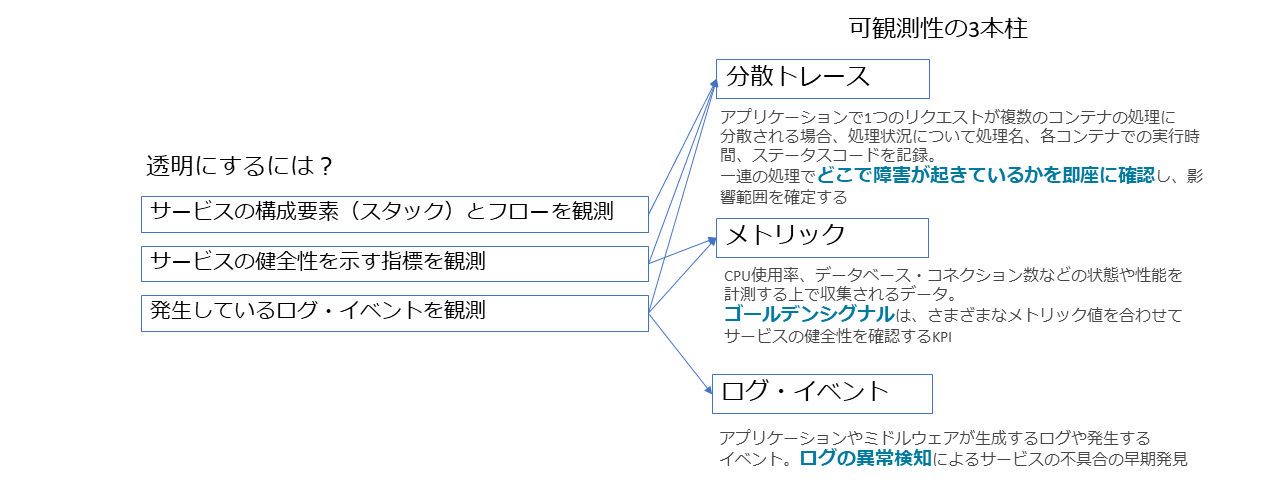
アプリケーションは一般的に複数のプロセスやプロセスのグループなどから構成されているが、分散トレースはそれぞれが何からどのように呼び出され、処理にどのぐらいの時間を要しているか、といった状況を時系列に表示する機能のことである。この数値を解析することで、たとえばある機能が他の機能を呼び出す際に通常より極端にレスポンスが劣化しているなどの現象を発見できる。
次にメトリックは、CPU使用率など従来からよく使用されているモニタリングの値を意味する。これに加えて、アプリケーション固有のメトリックもある。何らかの値、たとえばエラー率などをアプリケーション内で計算し、値が閾値以下の場合、アプリケーションは健全に動作していると判断する。これは、「ゴールデンシグナル」とも言われる。これらをモニターしていくことで、アプリケーションの健全性の監視精度を高められるようになる。
最後のログは従来どおりの情報だが、生成したログを保存するだけでなく、発生頻度やログの内容を分析することで、通常と異なる状況、つまり異常な状況かどうかを推察できる。
これらの3つの要素を収集し、リアルタイムに分析可能な状況にあるかが重要になる。
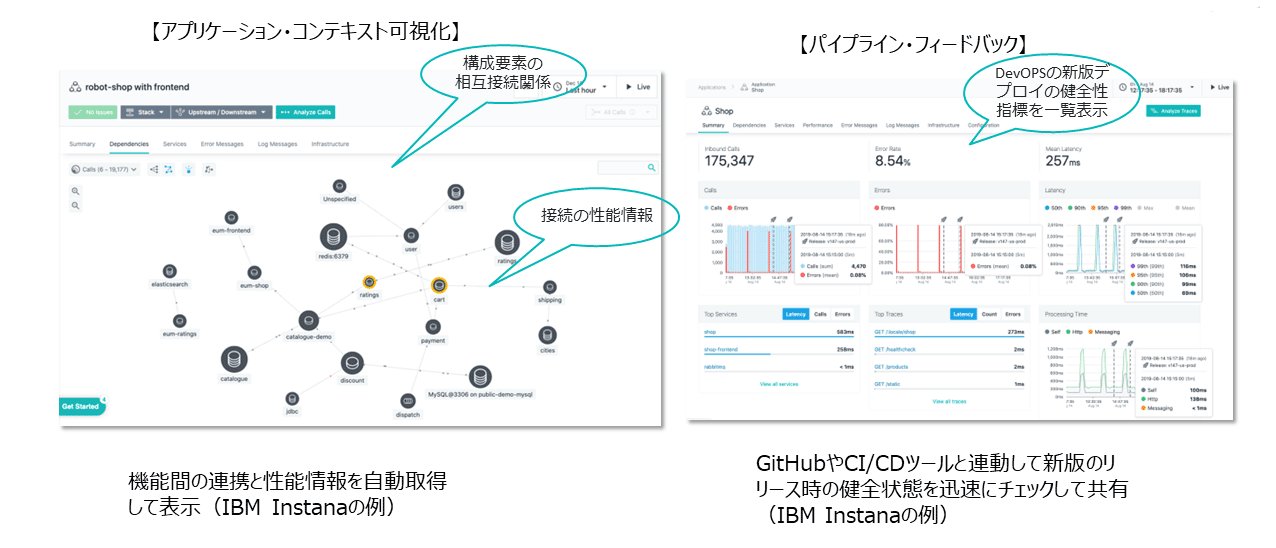
可観測性を実現する実装例として、Instanaを取り上げる。図表9の左側の画面ではプロセスを円で表現している。プロセスとは、たとえば受注や在庫引当などを意味する。それらがどんな関係性をもって繋がっているかを表現している。
繋がりを示すだけではなく、性能、つまりどのぐらいのスループットで動いているか、呼び出しからどのぐらいの時間が経過しているかなども見ていく。これらをダイナミックに情報収集し、一覧できる機能を提供している。
また、たとえばCI/CDの場合、日に何回もデプロイすることがあり、その際にさまざまなメトリックに関して、どの時点の値が、どのデプロイメントに紐づくのかを判別するのに手間がかかる。
Instanaのパイプラインフィードバック機能を使用すると、デプロイメントと紐づけて特定の監視用マーカーを挿入できる。このマーカーにより、デプロイメントに関する性能指標を容易に整理できる。
根本原因分析(Root Cause Analysis)
最後に、根本原因分析を取り上げる。従来までは、優秀なインフラエンジニアが障害時に発生したイベントを分析し、それらに関連する情報を収をし、疑義箇所を絞り込んで、問題解決に至る流れになる。
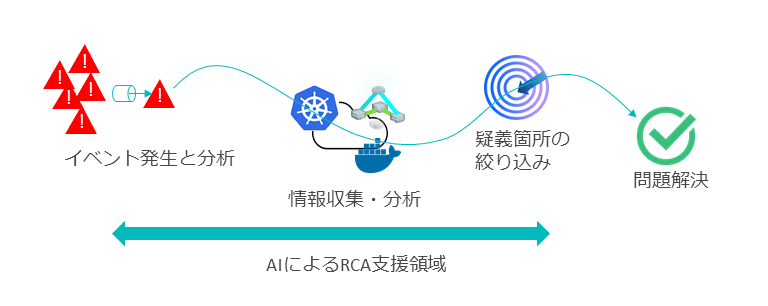
しかしDevOpsを実行している場合、時間をかけられないケース、あるいは時間的に非常に難しいケースに遭遇する。こうした課題へ対応する手段として、AIを使った根本原因分析が挙げられる。
根本原因分析(Root Cause Analysis:RCA)と呼ばれる機能を利用することで、熟練したインフラエンジニアの仕事を肩代わりできる。この機能を使えば、大量のイベントに関して、発生した箇所のイベントの共通項目や発生の時系列を整理してグループ化し、それらの構成の依存関係を調べることで、障害発生の起点を推察したり、絞り込んだりできる。
まず、Instanaによる実装例を挙げる。Instanaはアプリケーションごとに、動的にいろいろな構成要素を抽出し、整理する機能を搭載している。その情報を用いて障害が発生した場合に、どのあたりに問題があるかを分析する機能も併せ持つ。図表11の左側に、代表的な画面を掲載している。
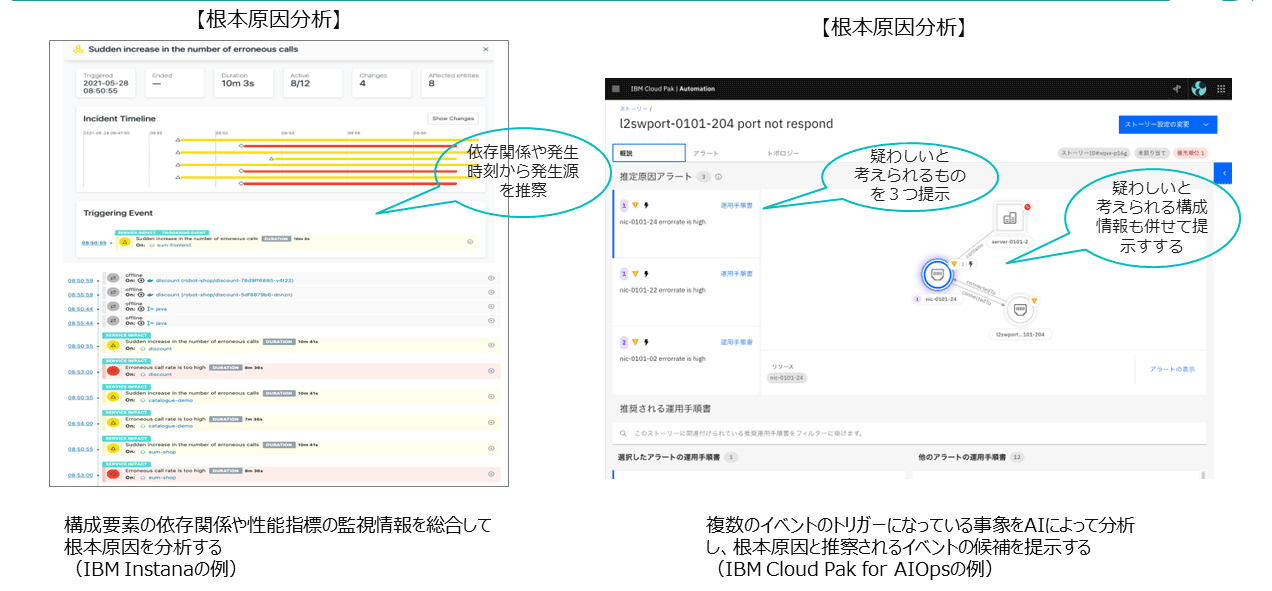
もう1つの実装例はIBM Cloud Pak for AIOpsである。図表11の右側画面の右部分で、障害イベントを収集し、分析し、障害原因として疑わしいと考えられる3点を提示している。このようなツールを活用して、根本原因分析の迅速化を進められる。
このように、インフラエンジニアがDevOpsで取り組むべきは、まずは確固とした監視基盤を作ることと。 そして監視基盤を作る際には、先ほど挙げた3つのポイント、すなわち「構成要素の自動取得」「可観測性の獲得」「障害時の根本原因の分析」という機能に対応させることが重要である。
最近では可能な限り、AIを取り込むことが成功の鍵となる。AIは、その環境で使用されるごとに賢くなる特性があるので、積極的に採用し、活用していくことが重要である。
DevOpsで必要とされる運用監視基盤はこの先、クラウドネイティブと呼ばれるような、次世代のモダナイズされたアプリケーション環境の運用監視基盤につながっていくことは間違いない。