企業におけるシステム運用では、常に安定したサービスをエンドユーザーに提供することが求められる。障害は避けられないが、障害が発生した際に、いかに早く問題を発見し迅速に対応するか、さらに未然に障害を予兆検知できるかが重要となる。システムの安定稼働を実現するうえで、システムの監視は有効な手段である。
なお、一口に監視と言ってもさまざまな形態があり、企業規模や業務内容によって監視のレベルや手法は異なる。ここでは監視を性能監視、メッセージ監視、障害監視の3つに大別し、それらの基本について解説する。
性能監視
性能監視ではシステム資源の利用状況を把握して、システムが最適に稼働していることを監視する。性能監視を定常的に実施することで、システム資源の利用状況の傾向を把握し、障害発生の異常事態を検知することが可能となる。監視の対象はサーバーからネットワークまで幅広く存在するが、IBM iのパフォーマンスのボトルネックとなりえるプロセッサ、メモリ、ディスクはとくに注意すべきである。
システムの良好なパフォーマンスを実現するには、この3つの資源のバランスが重要で、いずれもある一定の限界を超えるとパフォーマンスが急激に悪化する。システムがこのような状態に陥っていないかを監視するのが、IBM i における性能監視の第一歩と言える。
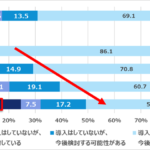
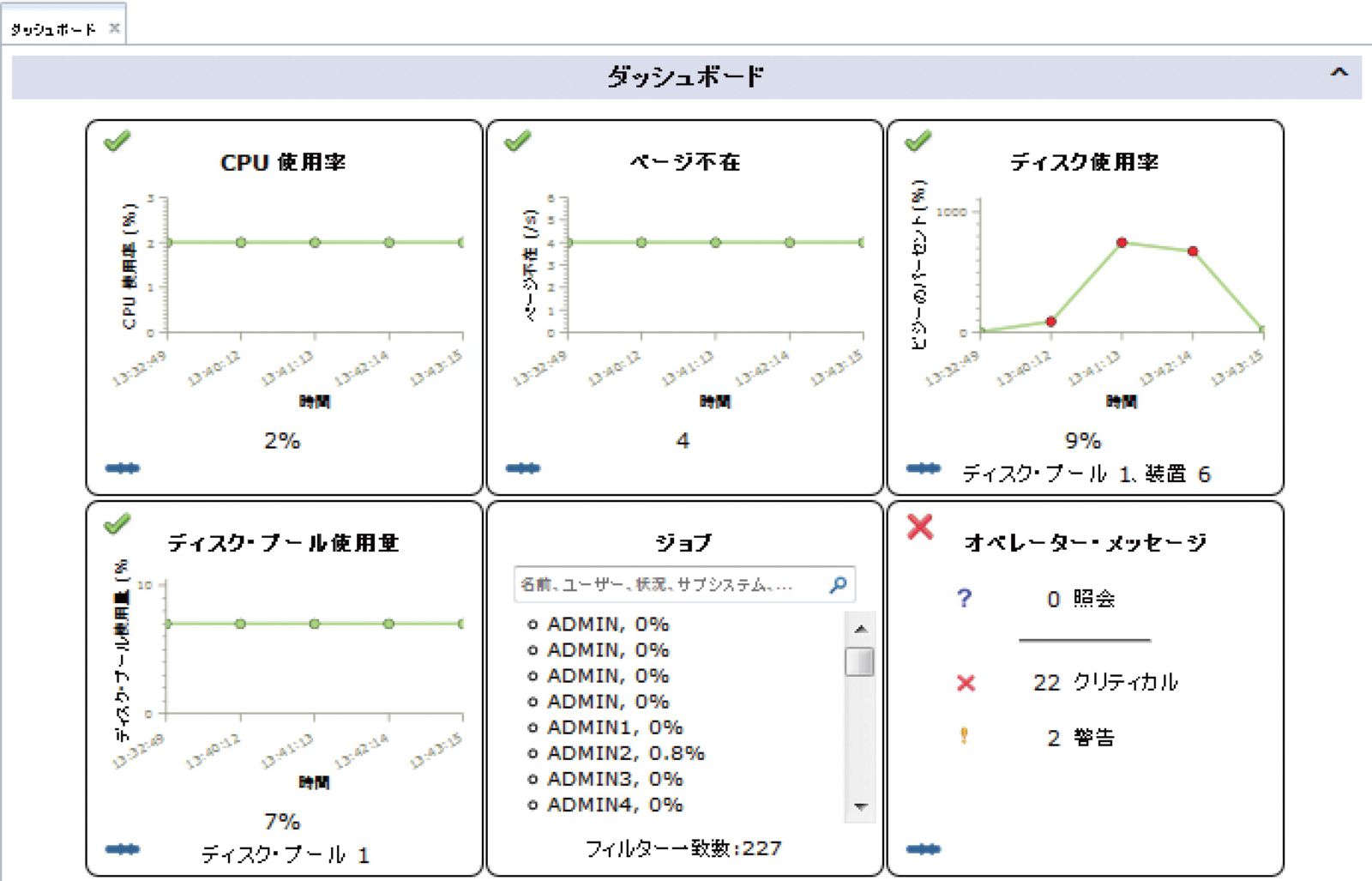
監視方法はさまざまだが、簡単な例としては前項で紹介した「IBM Navigator for i」のダッシュボードがある。
ダッシュボードでは、リソース状況がリアルタイムにグラフ表示され、状況を一目で確認できる。さらに、プロセッサであればCPU使用率というように、性能監視で監視すべき項目が事前定義されているので、IBM i初心者でも使いやすく、わかりやすい。ダッシュボードを起点として、各ウィンドウからドリルダウンして詳細情報を確認したり、関連の情報を参照できる。
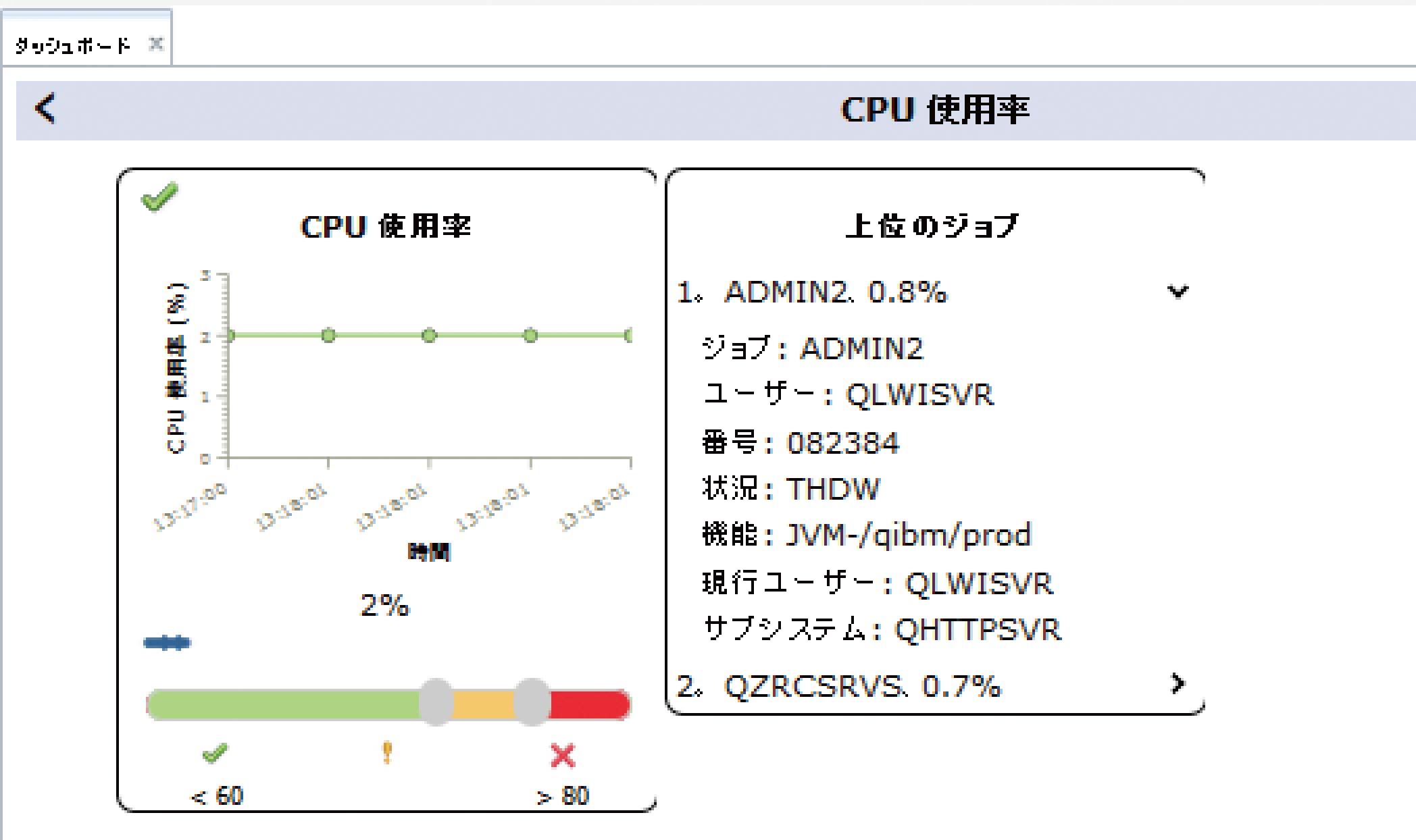
たとえばダッシュボードから「CPU使用率」のウィンドウをクリックすると、図表1のように、「CPU使用率」ウィンドウと「上位のジョブ」ウィンドウが表示される。
「上位のジョブ」には、CPUを使用している上位のジョブがリスト形式で表示され、各ジョブ名の横に表示されている矢印を選択し展開することで、ジョブの実行ユーザーやジョブ番号といった詳細情報を確認できる。
さらに、グラフの下に表示されている青いアイコンをクリックすれば、グラフ表示のために事前定義されている閾値をグラフィカルに確認できる。図表1は初期設定のままであるが、「CPU使用率」ではCPU使用率80%以上は赤色、60〜80%は黄色、60%以下は緑色でグラフ表示されるように定義されている。閾値はバーを移動させることで、自由に設定変更が可能である。
【図表1 画像をクリックすると拡大します】
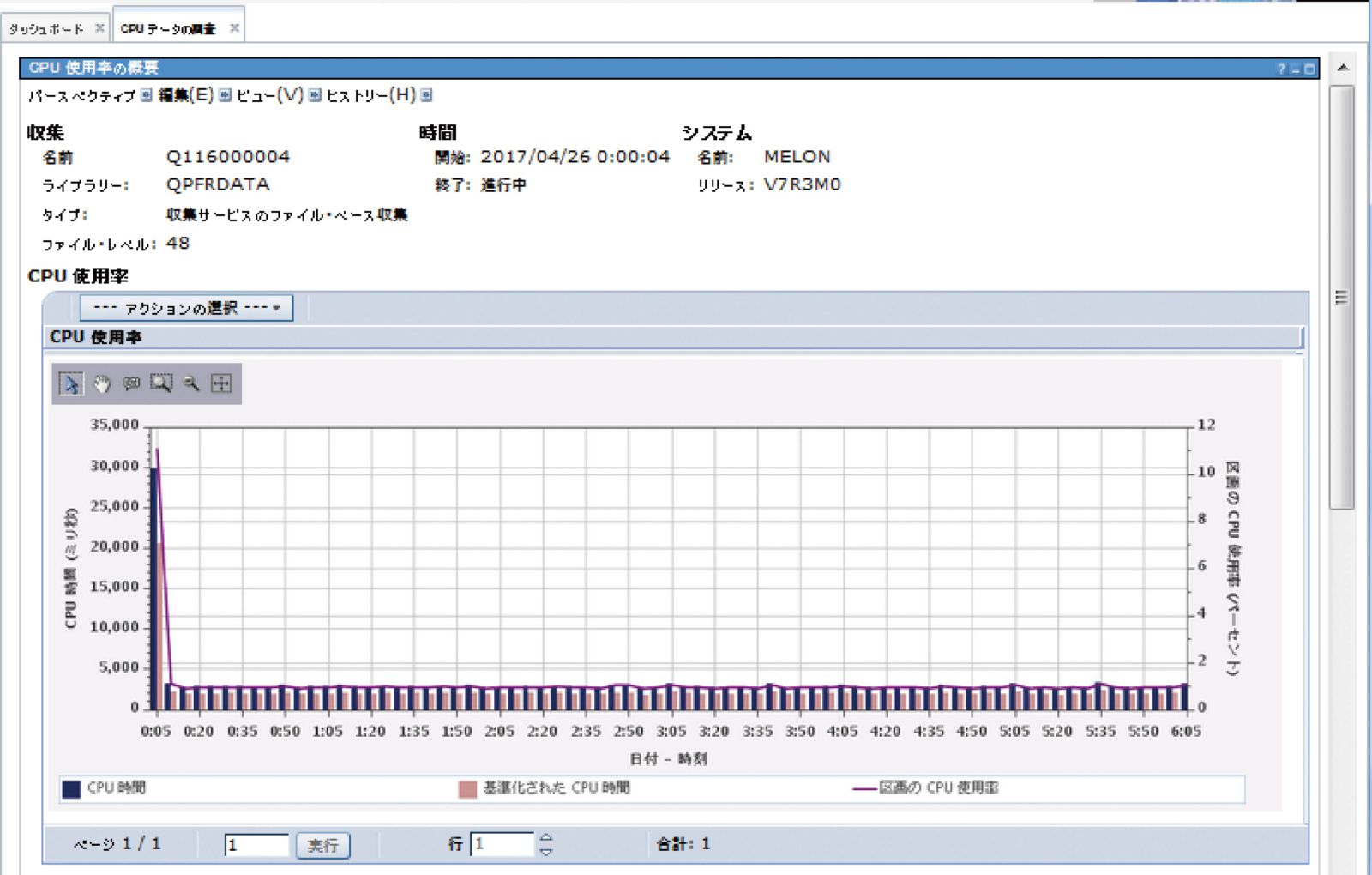
また図表2のように、「CPU使用率」ウィンドウを右クリックして表示されるメニューから「CPUデータの調査」を選択することで、新しく追加された「CPUデータの調査」から時系列でCPU使用率やCPU時間を表示した詳細画面を確認できる。
【図表2 画像をクリックすると拡大します】

外部システムとして監視サーバーを保有し、他システムと同様にIBM iの性能監視をその対象に含めたい場合もあるだろう。その場合はIBM i のOS機能として同梱されているSNMPエージェントの機能を使用することで、システム資源情報をSNMPマネージャーに連携させられる。
メッセージ監視
IBM iのメッセージとはログを意味しており、通常、メッセージ待ち行列(*MSGQ)と呼ばれるオブジェクトに格納される。IBM iではシステムの内部が構造化されているが、メッセージもOS、ジョブといったレベルに分けて出力され、見やすくわかりやすいメッセージにより問題が早期解決できるように工夫されている。
OSレベルで出力されるメッセージとしては、図表3に示すシステム操作員メッセージ待ち行列(QSYSOPR)がある。QSYSOPRのMSGQには、システムで主要なイベントが発生した場合や、障害が発生した場合などにメッセージが出力される。
【図表3 画像をクリックすると拡大します】
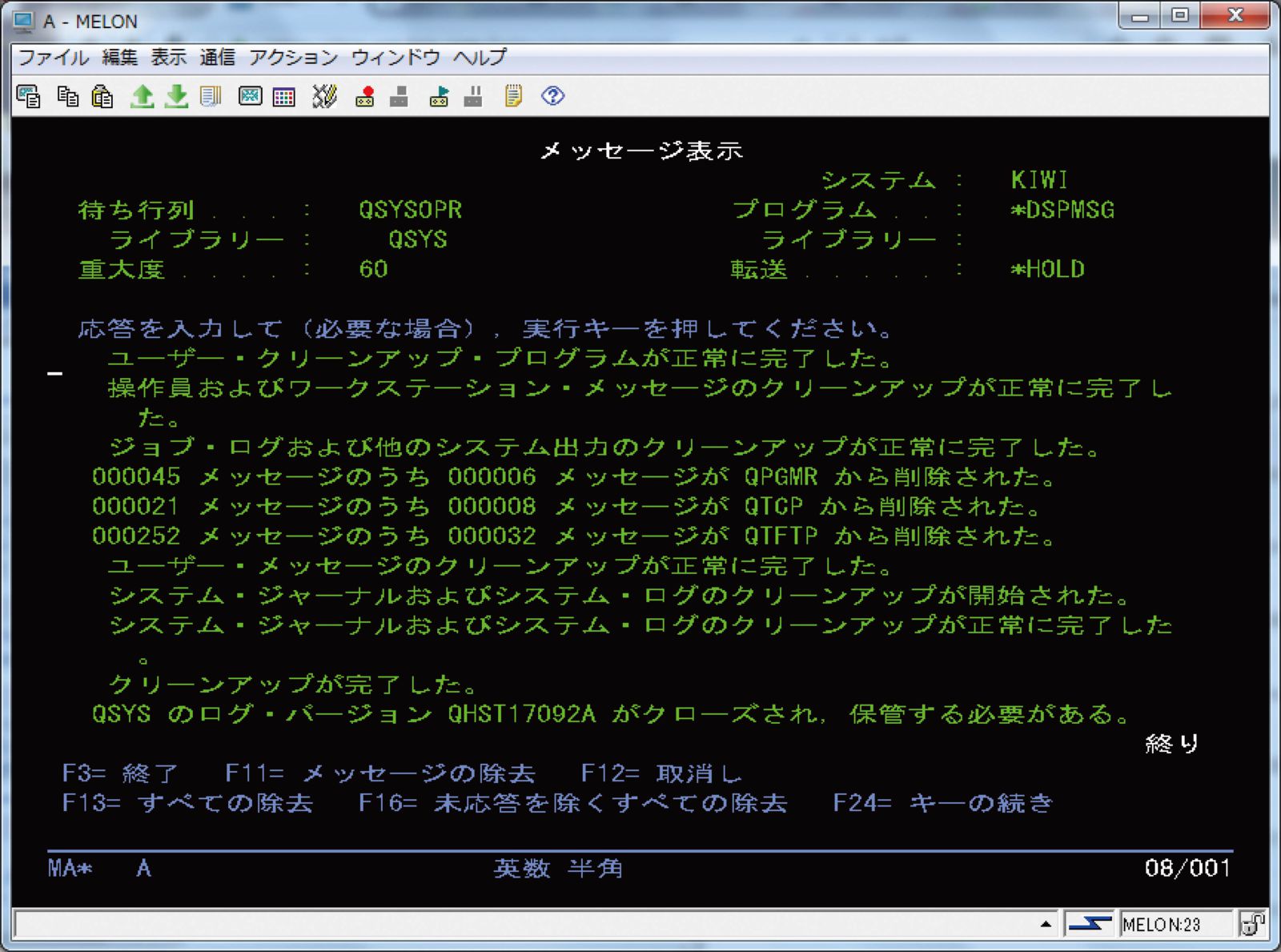
メッセージによっては、応答が必要な場合もある。QSYSOPRのMSGQは、IBM iの管理者にとって基本となるメッセージ監視対象であり、重要なメッセージを見落とさないように注意したい。
QSYSOPRの最も原始的で簡単な監視方法は、メッセージ待ち行列の属性を変更して、中断モード(*BREAK)に設定することである。この設定をしておくと、QSYSOPRのMSGQにメッセージが出力されるたびに、ジョブを中断し、メッセージが表示される。また重大度の高いメッセージだけを表示させるような設定も可能である。
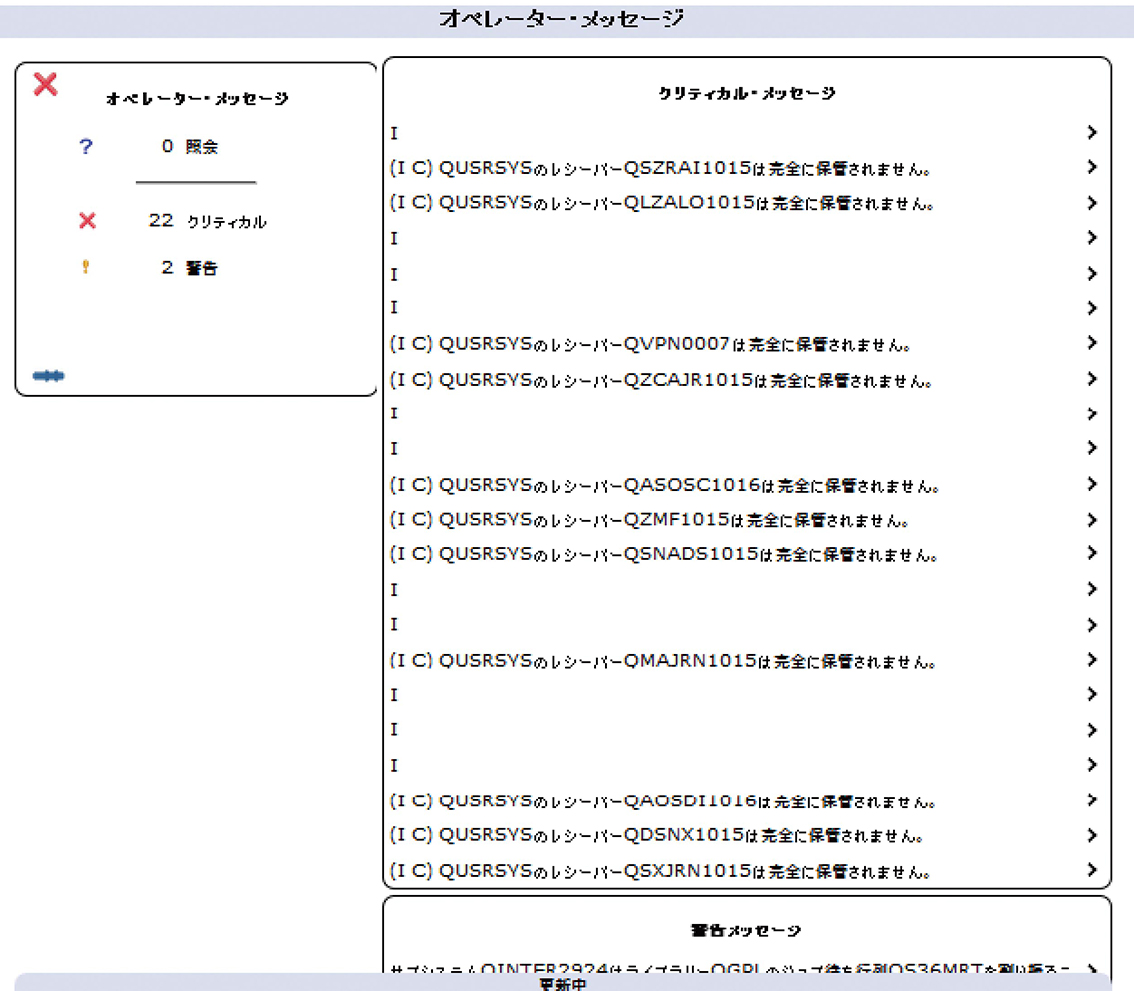
このほか、「IBM Navigator for i」のダッシュボードを使用した監視も可能である。図表4は、ダッシュボードから「オペレーター・メッセージ」のウィンドウをクリックした画面である。メッセージのタイプ別(照会、クリティカル、警告)に件数がまとめられ、クリティカル・メッセージや警告メッセージの詳細も一緒に確認できる。
【図表4 画像をクリックすると拡大します】
メッセージ待ち行列はQSYSOPRのようにシステムで提供されるものもあるが、ユーザーが作成することも可能である。たとえば業務アプリケーションごとに専用のメッセージ待ち行列を作成し監視することで、アプリケーションが正常に完了したかを確認したり、応答が必要なメッセージに速やかに対応できる。
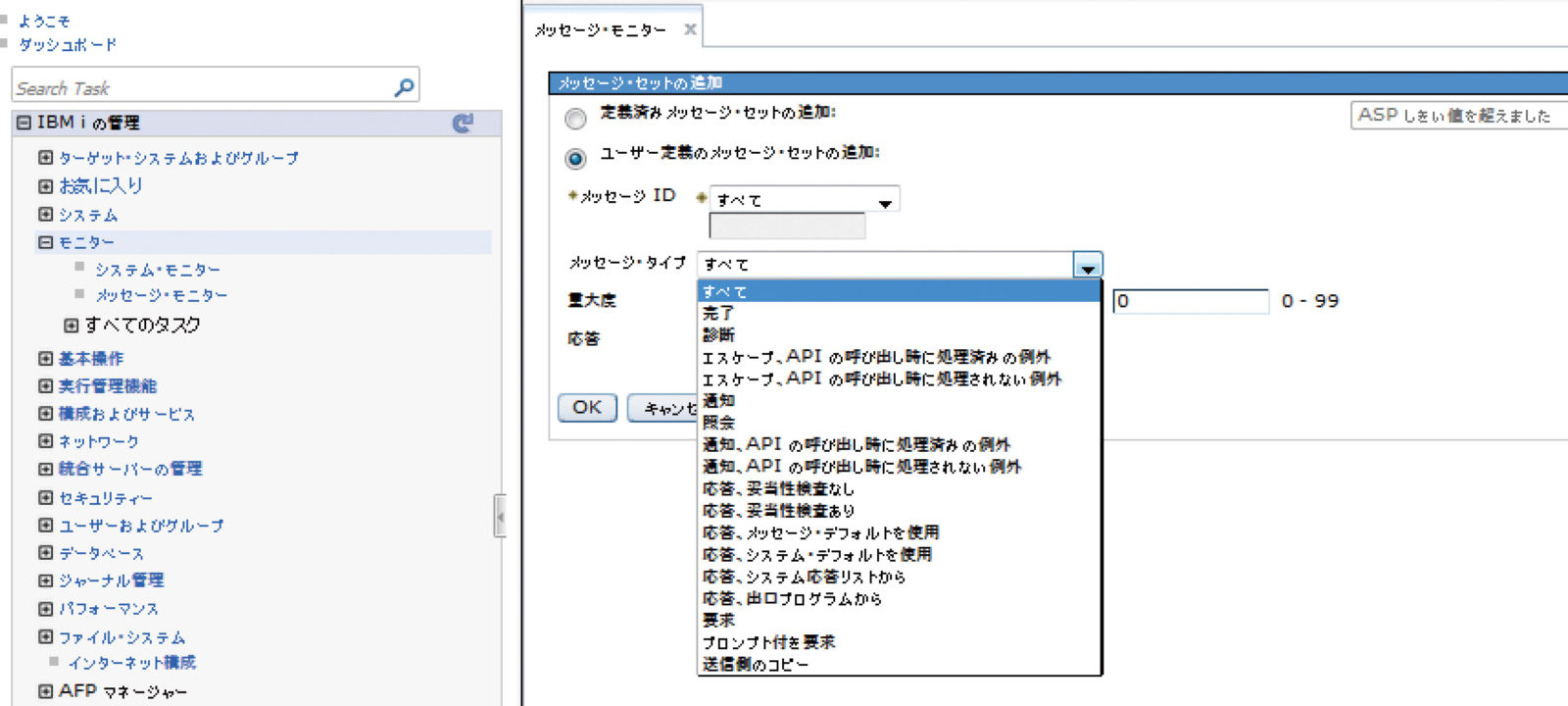
この場合には、IBM Navigator for iで提供されているメッセージ・モニター機能が便利である。メッセージ・モニターはメッセージ待ち行列ごとに設定する必要がある。図表5のようにモニターするメッセージ・タイプとして、「すべて」を設定したり、「完了」だけを設定したりできる。
【図表5 画像をクリックすると拡大します】
障害監視
障害監視では、ハードウェアやソフトウェアの障害を監視する。IBM iではこれらの障害や警告についてもQSYSOPRメッセージ待ち行列に出力されるので、まずはここを監視することになる。
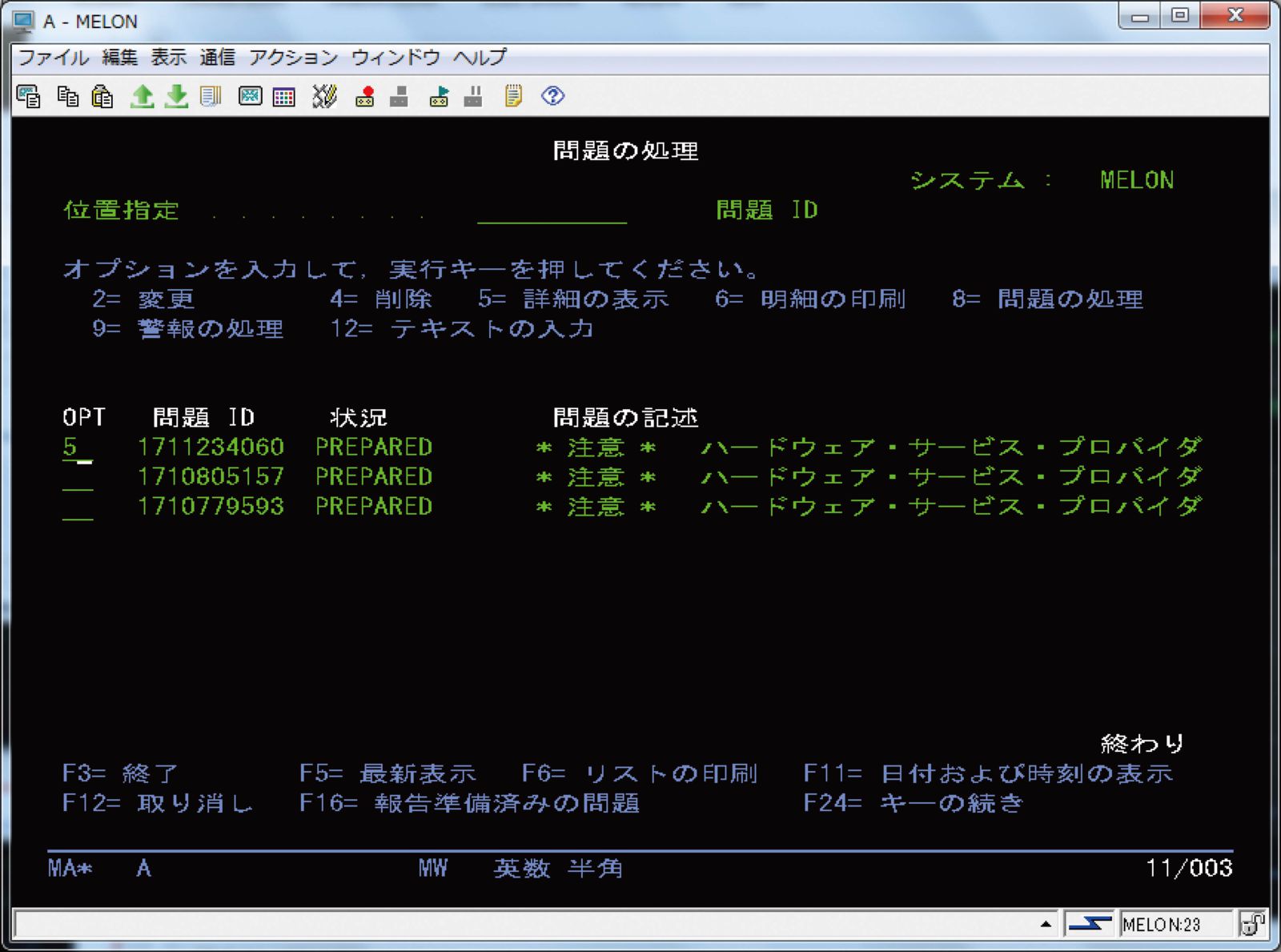
実際の障害時には、QSYSOPRメッセージ待ち行列に出力されたメッセージをトリガーとして、図表6に示す問題の処理画面(WRKPRBコマンドで出力)で関連情報が表示されているか、図表7に示すプロダクト活動ログ(PAL)でシステム、ライセンス内部コード、ソフトウェア・コンポーネント、入出力装置などに関する詳細情報が表示されていないかを確認する。
【図表6 画像をクリックすると拡大します】
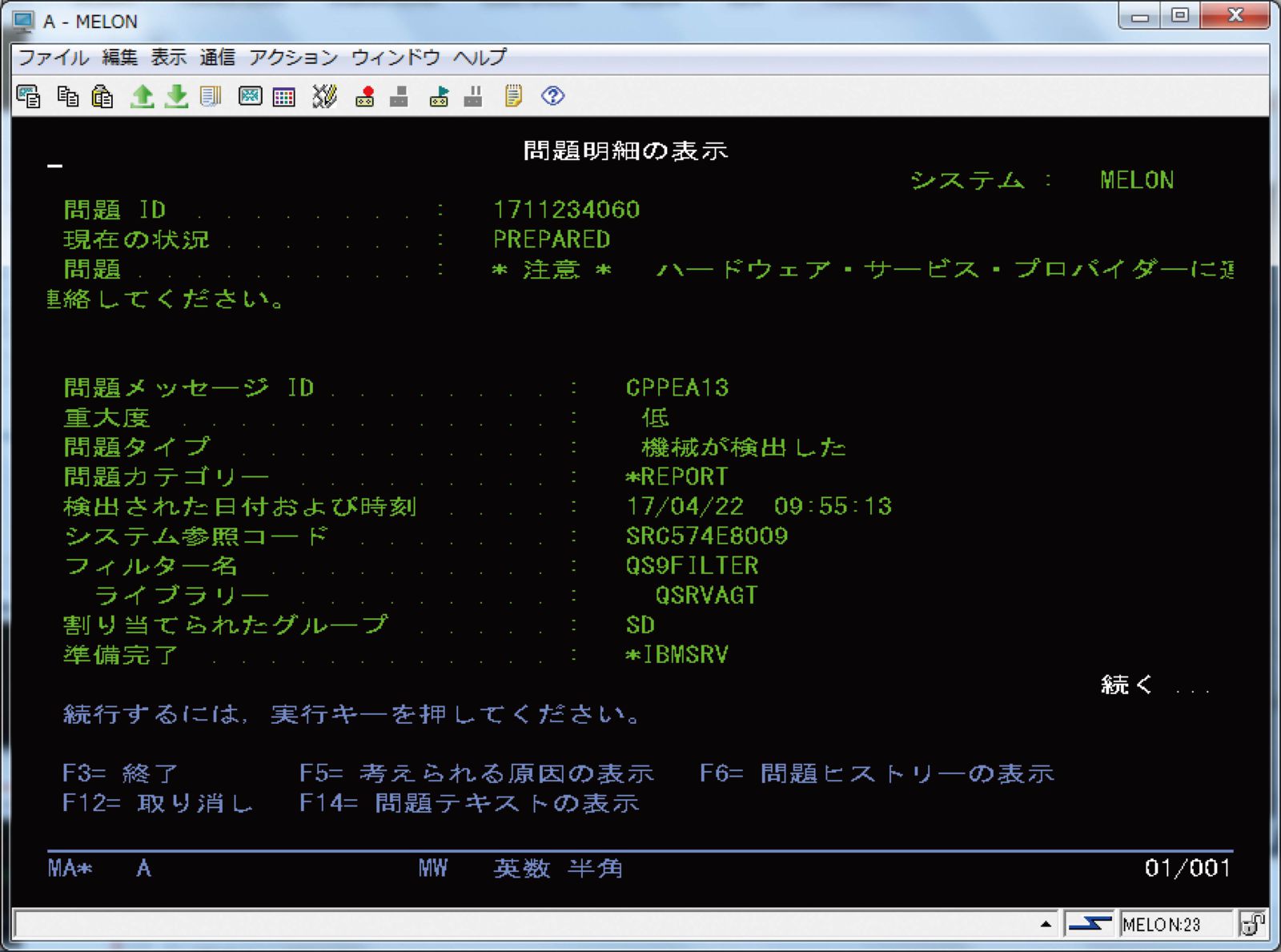
【図表7 画像をクリックすると拡大します】
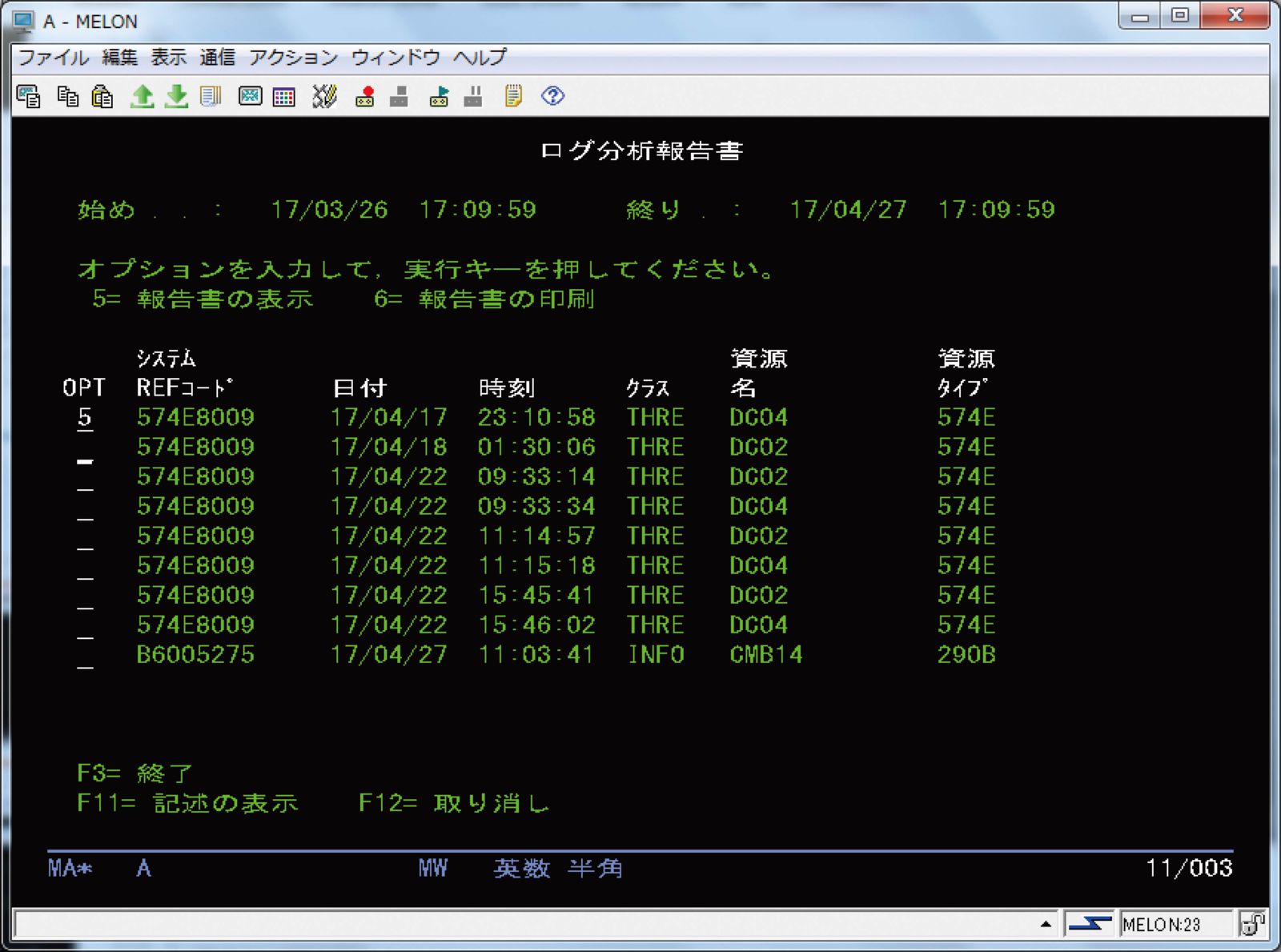
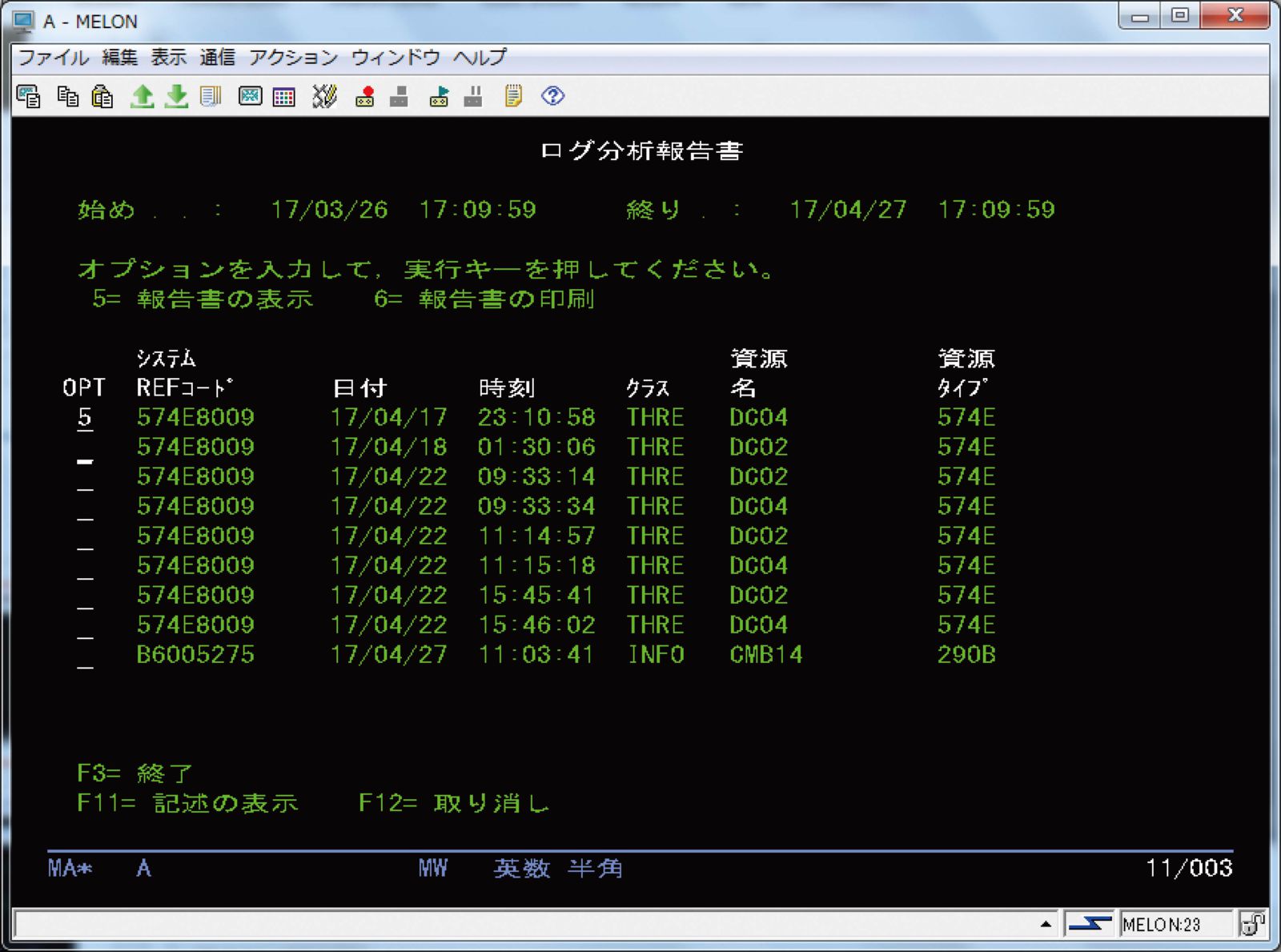
まず最初に確認すべきポイントは、QSYSOPRメッセージ待ち行列であることを覚えてほしい。
なお、IBMではシステム運用の負担を軽減するために、ROMSやESA と呼ばれるサービスを提供している。ROMSはIBM i 運用監視サービスと呼ばれ、メッセージ監視やシステム活動監視などを提供している。ESAはElectronic Service Agent(エレクトロニック・サービス・エージェント)の略で、IBM iやHMCがハードウェア障害時にIBMに問題を自動発報する機能である。必要に応じて、これらのサービスも有効に利用できる。【松川 真由美】