IBMは7月4日、IBM watsonxを、ライセンス、サブスクリプション、クラウド(as a Service)の3種類の形態で提供する、と発表した。提供開始は7月7日で、as a Serviceは現在、IBM Cloudのダラス、ロンドン、フランクフルト、東京の4カ所のリージョンで利用できる。またこれを受けて、7月12日に「IBM watsonxの一般提供を開始した」と発表している。
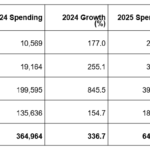
IBM watsonxの3種類の料金体系や詳細は未公表。サブスクリプション(IBM watsonx Subscription 1.0)については「最低2年間の利用が必要で、1年間ごとの延長が可能」とし、as a Serviceについては「お客様のニーズに基づいて個々のサービスを追加・削除、または結合できる、個々のクラウド・サービスの集合」と説明している。
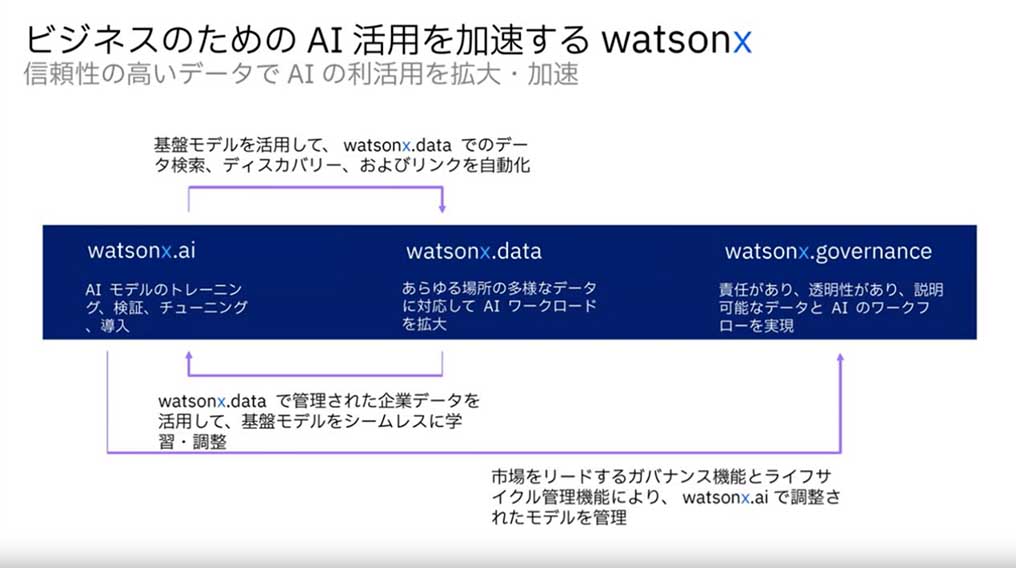
IBM watsonxは、AI構築のための「IBM watsonx.ai」、オープンなデータレイクハウス・アーキテクチャをもつ「IBM watsonx.data」、管理とガバナンスを実現する「IBM watsonx.governace」(今秋リリース予定)の3つの要素から成る。
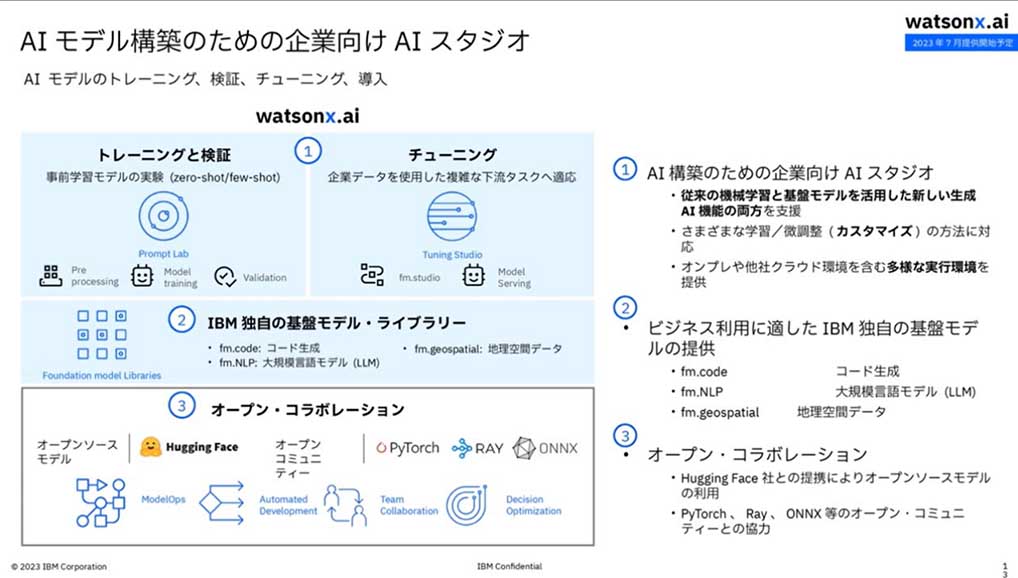
IBM watsonx.aiは、IBM独自の基盤モデル向けライブラリーと、PyTorch、RAY、ONNXなどオープンソースの機械学習用ライブラリーやフレームワークを備えるAI開発基盤。これにより基盤モデルの活用による生成AIや機械学習モデルのトレーニングや検証、調整を劇的に効率化し、推論コストを低減できる、とする。さらにHugging Faceの適用により、開発した生成AIや機械学習モデルの共有や移植性を高めている。
また、基盤モデル向けライブラリーは「信頼できるデータで、透明性を担保しながら事前学習したもの」で、コード生成、地理空間データ、大規模言語モデル、金融、化学、気象などのモデルを近日提供の予定という。
IBM watsonx.dataは、クエリー・エンジン、オープン・テーブル・フォーマット(データ・フォーマット)、メタデータ&ガバナンスの3階層で構成される。PrestoやSparkなど多種類のクエリー・エンジンを同時に使え、オープン・テーブル・フォーマットにより異なるデータベースやデータソースへ同時にアクセスしてデータを共有でき、メタデータによりデータを移動することなくデータを活用し、かつセキュリティ管理やガバナンスを実現することができる。

GPT-4は約13兆個のトークン(単語や言葉の断片)と約1.8兆個のパラメータのデータセットを有していると言われる。これに対して、IBMはIBM watsonx.aiの基盤モデルを約1兆個のトークンのデータセットで開発した。「IBMの顧客が必要とするビジネス用AIには、GPT-4ほど大きなデータセットは必要ない」というのがその理由だが、「ビジネスに関連する学習データの中で、最大規模のリポジトリを保有している」とも強調する。
IBM watsonxによって、ビジネス向けの本格的な次世代AI構築・活用基盤が姿を現した、と言えそうである。
[i Magazine・IS magazine]