Text=江田 幸弘 日本IBM
ネットワーク可観測性の必要性
ITアプリケーションはビジネスの中心となり、ますます重要性が高まっている。
アプリケーションの実行環境はオンプレミスだけではなくパブリッククラウド、仮想マシンではなくコンテナあるいはサーバーレスを活用し、さらにそれらを組み合わせたハイブリッド・マルチクラウドのアーキテクチャを採用することも増えている。
ネットワークはそれらの接続に必要なので、アプリケーションに関連する重要なネットワークの範囲が拡大していると言える。
可観測性とは、テレメトリデータにより、システムに入ることなく何が起こっているかを把握する仕組みを指す。
アプリケーションの観点では、分散トレース技術によりアプリケーションを構成する各コンポーネント単位で必要な統計情報を可視化し、1つ1つのリクエスト単位での詳細情報をWeb UI上で視覚的に確認できるようにすることで、問題の早期検知および早期解決を可能にする仕組みの導入が進んでいる。
一方で、可観測性をネットワークの観点から考えてみよう。
現在は多くの場合、デバイスやVLANの死活監視、疎通確認、CPU使用率、メモリ使用率、ネットワーク・インターフェース単位のトラフィック量を、5~15分単位で確認する最低限の定点監視が中心となっている。
この状態ではネットワークがつながらない、あるいは遅い、という問い合わせに対してテレメトリデータでは解決できず、膨大な調査の時間を要することになる。
前述したとおり、ITアプリケーションはビジネスの中心であり、そのアプリケーションを支えるネットワークもまたビジネスの中心と言える。
アプリケーション可観測性の導入が進み、アプリケーション観点の問題の早期検知および早期解決が図られるようになった場合、同様にネットワーク観点でも問題の早期検知および早期解決が求められる。
つまりアプリケーション可観測性の普及と同時に、または少し遅れたタイミングで、ネットワーク可観測性が求められることになると筆者は考えている。
ネットワーク可観測性の導入目的と期待される効果
次に、ネットワーク可観測性を導入する目的と期待される効果について考えてみよう。投資対効果を考慮すると、以下の3つの効果が考えられる。
① 異常の早期検知と早期解決(MTTD/MTTI/MTTRの改善)
最も大事なのは、ビジネスインパクトを最小限に抑えることである。異常を早期に検知し、問題発生箇所と根本原因を早期に特定し、迅速に復旧させる。そのために必要なテレメトリデータをすべて集める、そしてそれらのデータを容易に分析するなど、担当者がうまく使いこなす必要がある。
復旧作業についても自動化の仕組みと連動させることで、オペレーションの効率化およびヒューマンエラーの防止につながる。
② 適切な投資判断のサポート(TCOを最適化)
ネットワークは、末端を除いて基本的に共有インフラであり、複数のアプリケーションで共有利用されている。そのため、ネットワークのキャパシティ管理は重要である。そして、増強が必要となった場合は必然的に大規模な投資が必要となる。
適切な投資時期を判断するには、ネットワークのキャパシティデータを必要な期間保存し、中長期スパンで傾向分析することが必要である。
また近年、アプリケーションのマルチメディア化により、トラフィックは大幅な増加傾向にあり、単純なトラフィックの推移だけでなく、どのユーザーやアプリケーションが帯域を使用しているかといった推移も合わせて見ることで、想定外のトラフィック増加がないかを確認することも重要である。
③ 次世代アーキテクチャの推進
ビジネス、つまりアプリケーション中心で次世代アーキテクチャを検討するケースが増え、そのために必要なネットワークを含むインフラ整備を行うことが多いと思われる。
従来の運用監視ツールでカバーできる範囲は踏襲し、カバー範囲外は新しいツールを導入すると、その結果としてツールのサイロ化が進み、運用コストが膨らむという悪循環に陥る可能性がある。これを解決するには、新しいテクノロジーをサポートしつつ、一元管理していくことが求められる。
IBM SevOne Automated Network Observability
IBM SevOne Automated Network Observability(以下、IBM SevOne)は、ネットワークの可観測性を実現するためのソフトウェア製品である。
主な機能を図表1に示す。

前述した導入目的に対する機能を以下に記載する。
① 異常の早期検知と早期解決(MTTD/MTTI/MTTRの改善)
・IBM SevOneは取得したすべてのメトリックに対して、機械学習によるベースラインを自動的に計算し、トラフィックの急増などの異常を早期に検知できる。
・すぐに使える組み込みのダッシュボード(IBM SevOneでは「レポート」と呼ぶ)が豊富にあり、運用担当者はデータを取得した直後からさまざまな分析やトラブルシュートに役立てられる。
・オンプレミスからクラウドまでのすべてのデータ、またカスタムのKPIを俯瞰的に保持することによって、根本原因を特定できる。
・ローコードのワークフローエンジンを使用して、障害復旧や定常運用作業の自動化の推進を可能とする。
② 適切な投資判断のサポート(TCOを最適化)
・取得したデータは分析のために、ポーリングデータであれば1年間、フローデータであれば7日間、生データのまま保持しており、より精度の高い分析を行える。
・キャパシティに関してゴールラインを設定し、日次平均や日次最大値の観点でどれだけ超過が発生しているかの推移や、あと何日で超過するかの予測など、さまざまな観点で可視化・分析できる。
・単純なトラフィックの推移だけでなく、どのユーザーやアプリケーションが帯域を使用しているのかの推移も合わせて見ることで、想定外の帯域使用がないかを確認できる。
③ 次世代アーキテクチャの推進
・IBM SevOneは次世代テクノロジーのサポートに積極的に取り組んでおり、SD-WAN、SDN、Wi-Fi、パブリッククラウド、リモートワーク環境(VPN)に関してはテクノロジー特有のデータの可視化が可能である。
・無制限のスケーラブルアーキテクチャが特徴であり、大規模なネットワークへの対応や多拠点時の柔軟な構成など一元管理が可能である。
本稿では、特に上記1について例を挙げて説明する。
IBM SevOneの活用例
ビジネス・アプリケーションを意識したトラブルシューティング
IBM SevOneを使用してどのように問題解決するか、具体的な例を挙げて説明する。
シナリオ:あるWebアプリケーションで障害が発生した。現在は復旧しているが、アプリケーション・レイヤーに問題は見つからず、根本原因が不明であるため、ネットワークチームに調査の依頼があった。
ネットワークチームとしては、膨大なネットワーク環境を管理していることを前提に考えると、ビジネス・アプリケーションを意識して可用性および性能の分析を行うことが重要である。
つまり、ビジネス・アプリケーションに関連のあるスイッチ、ルータ、ファイアウォール、ロードバランサなどを効率よく網羅的に調査する必要がある。
IBM SevOneでは、デバイスが持つコンポーネントを「オブジェクト」と呼び、オブジェクトが持つメトリックを「インジケーター」と呼ぶ。また、デバイスをグループ化したデバイス・グループや、オブジェクトをグループ化したオブジェクト・グループを自由に定義できる。
たとえば、当該Webアプリケーションに関連するオブジェクト・グループとして、「Public Website」という定義を作成しておくことで、即座に当該Webアプリケーションに関連するデータだけを絞り込み、ダッシュボードに表示できる。
IBM SevOneのダッシュボードは基本的にデバイスに依存しない汎用性があり、管理対象全体から適切なフィルタリングをかけて、データを閲覧・分析するように作られている。また、ダッシュボード間をシームレスに遷移しながら深掘りしていくことが可能であり、この機能が強力であることを強調しておく。
本稿の例では、「ビジネスアプリケーションレポート」を使って状態を確認していく。
まず、左上のApplicationのところでオブジェクト・グループ 「Public Website」を選択する(図表2)。
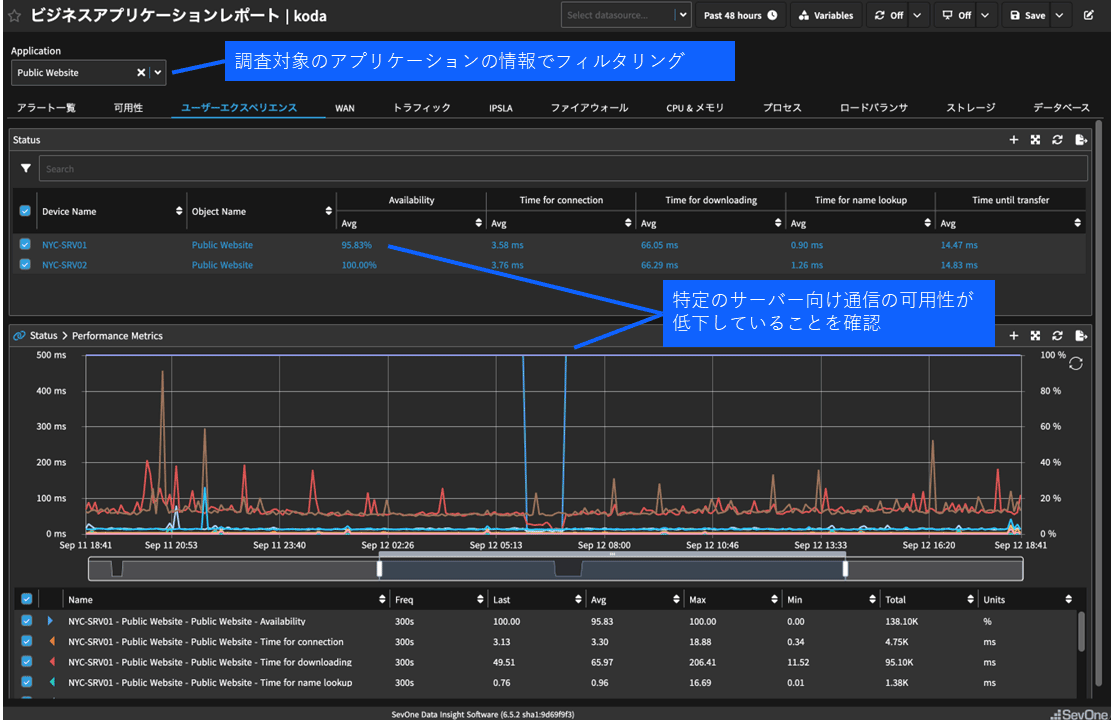
Public Websiteに関連する情報のみで、このビジネスアプリケーションレポートを見ていく。
まず、「ユーザーエクスペリエンス」タブを選択すると、このアプリケーションを提供している2台のサーバーのうち、1台向けの通信の可用性が低下していることが分かる。
次に、「ロードバランサ」タブを開くと、ロードバランサのVirtual Serverのコネクションでスパイクが発生していることが分かる。
グラフ上にカーソルを合わせると、値がポップアップされるため、LDAPのコネクションであると判断できる。
またPoolのコネクションでも、時間差でスパイクが発生していることが分かる。同様にグラフ上にカーソルを合わせることで、どのPoolであるかを特定できる(図表3)。
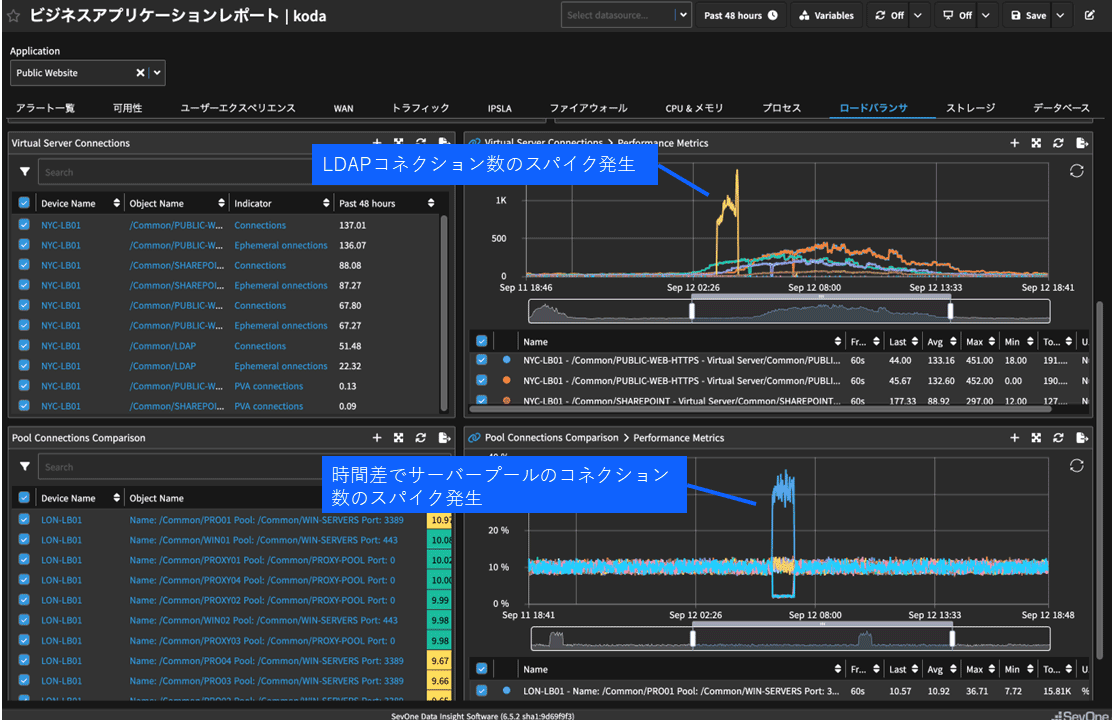
ロードバランサの挙動に異常があるため、次はその状態を確認する。
今開いているレポートの左表で、「Device Name」列で青字になっている文字列(NYC-LB01)をクリックする。そうすると、BIG-IPのレポートに直接ジャンプできる。
BIG-IPのレポートでは、BIG-IPから取得したさまざまな情報を閲覧できる。
「Memory」タブを開き、TMMメモリ使用率が100%張り付きになっている時間帯があったことを確認できる(図表4)。
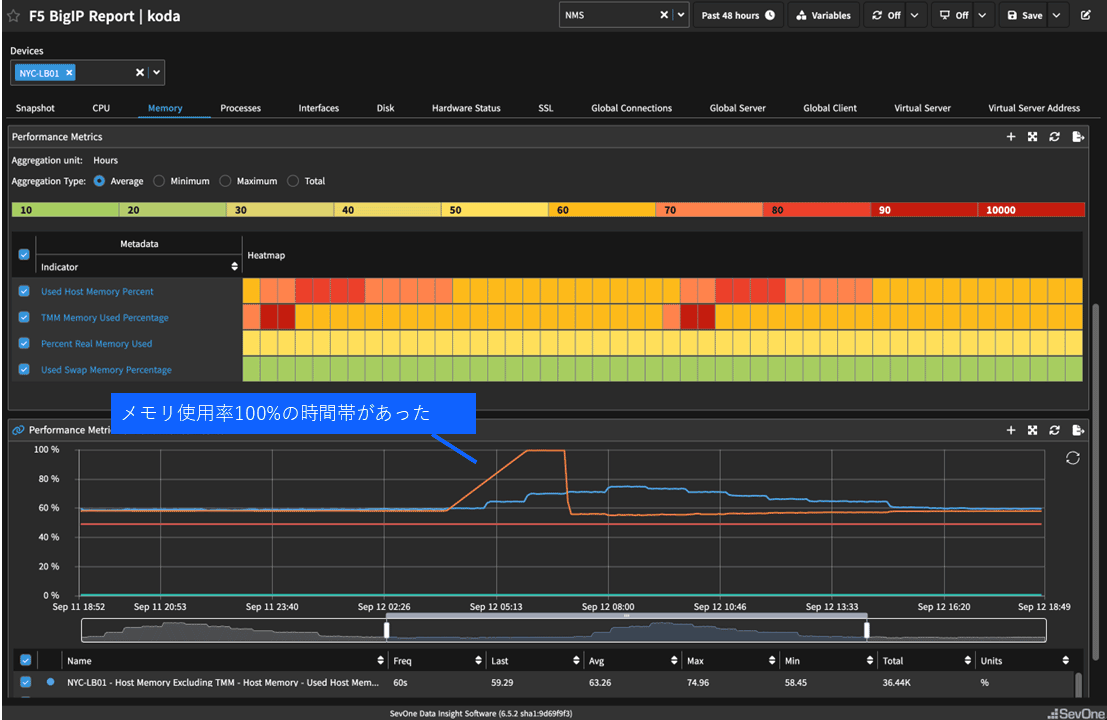
今までの情報だけでも、コネクション数の異常とメモリ使用率100%は関連があると推測できるが、同じ時系列で相関を確認したい場合は、さらに深掘りして関連性を分析できる。
開いているレポートの左上表の「Indicator」列から、青字の文字列(TMM Memory Used Percentage)をクリックし、「Data Analytics Workspace」または「Instant Graphs Workspace」にジャンプする。
この2つのレポートでは共通で、任意のデバイス、オブジェクト、インジケーターを同一のグラフに重畳させることで相関分析を行える。
Data Analytics Workspaceでは、ベースライニングや過去データとの比較、トレンド分析など分析機能を容易に実行できる。
本稿のケースで、関連するものをまとめたグラフが図表5である。
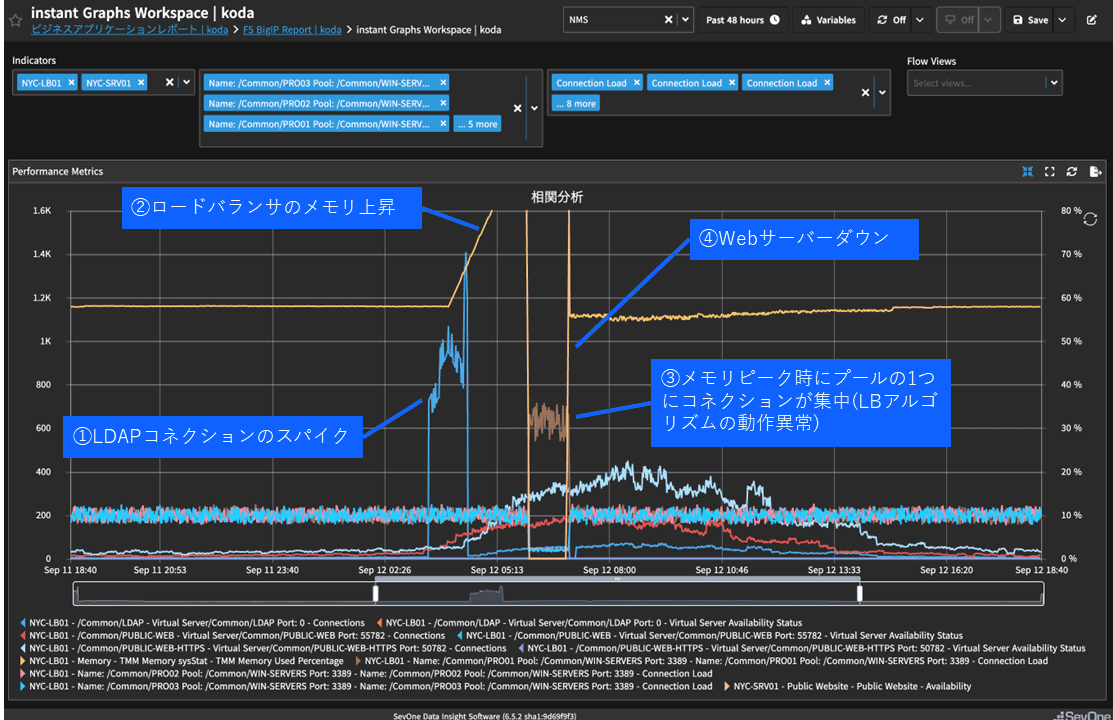
相関を示すことにより、以下のようにまとめられる。
❶ LDAPコネクション数のスパイクが発生
❷ ロードバランサ(BIG-IP)のメモリ使用率が上昇
❸ メモリ使用率が100%になり、Poolの1つにコネクションが集中(LBアルゴリズムの動作異常発生)
❹ コネクションが集中したWebサーバーがダウン
ローコードのワークフロー自動化
IBM SevOneには、ローコードのワークフローエンジンがバンドルされている。
運用者は複雑なスクリプトを書くことなく、事前定義された1000以上のビルディングブロックを組み合わせて、APIベースの自動化ワークフローを作成できる(図表6)。
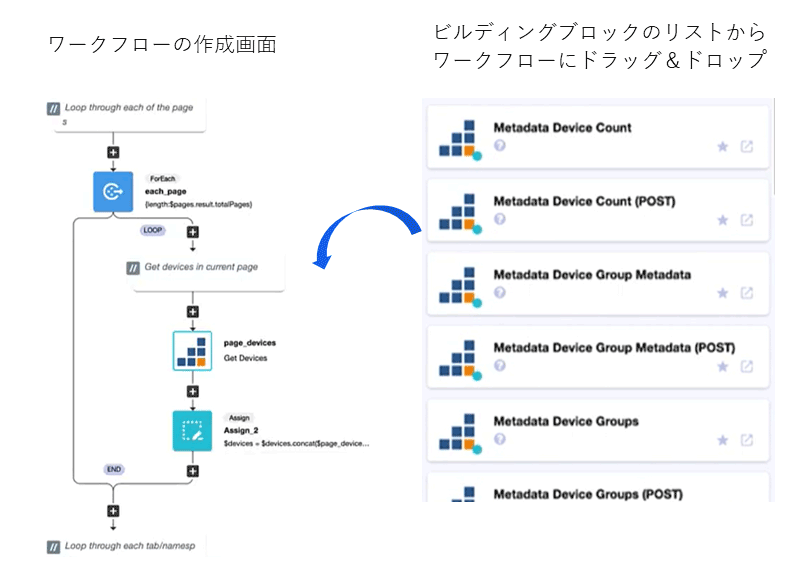
これは単純な障害復旧作業の自動化に留まらず、手作業・スクリプトによる作業を組み込める。
例えば、以下のユースケースが考えられる。
・通信品質(QoS)が低下した際に、自動的に帯域幅を変更
・機械学習ベースの異常検知(トラフィックの急増など)と連動したアクションの実行
・Excel、CSVファイル、外部CMDBで管理されているデータをメタデータとしてエンリッチメント
・事前処理を加えたチケットシステムの自動チケット作成
・IBM SevOneがネイティブで未対応の監視対象データをAPI連携で取り込み
さらなる運用の高度化
本稿では、ネットワーク可観測性の必要性とIBM SevOne製品によって提供されるソリューションを中心に説明した。
IBMではアプリケーション可観測性の製品として「IBM Instana Observability」を、AIOpsプラットフォームとして「IBM Cloud Pak for AIOps」を提供している。
IBM SevOneは、これらのソリューションと柔軟に連携できる。組織の課題や運用チームの体制に応じて製品を組み合わせ、より高度なソリューションを検討することが可能である。

*本記事は筆者個人の見解であり、IBMおよびキンドリルジャパン、キンドリルジャパン ・テクノロジーサービスの立場、戦略、意見を代表するものではありません。
当サイトでは、TEC-Jメンバーによる技術解説・コラムなどを掲載しています。
TEC-J技術記事:https://www.imagazine.co.jp/tec-j/
![]()
[i Magazine・IS magazine]