Power Systems上で利用できる
機械学習支援ツール
2012年に設立された米H2O.ai(エイチツーオー・ドットエーアイ)社は、オープンソースのAIプラットフォームを提供するシリコンバレー生まれの新興企業である。同社が展開するオープンソース版の機械学習ソフトウェアは、世界で1万4000社以上の企業に利用されている。
そしてオープンソースの活発なコミュニティからもたらされる、機械学習に関する膨大なフィードバックと高度なナレッジをベースに製品化されたのが、「H2O Driverless AI」(以下、Driverless AI)である。
同社は2018年6月に米IBMと業務提携し、IBMはPower Systems上で稼働する機械学習支援ツールとしてDriverless AIの販売を開始した。それに伴い、IBM市場のVADとしてPower SystemsをはじめとするIBM関連製品の流通を一手に担うイグアスも、2019年初頭からDriverless AIの販売に本腰を入れ始めた。
IBMは現在、オンプレミス環境でのAIソリューションのラインナップを図表1のように展開している。Power Systems上で稼働するAIソリューションは大きく2つある。数値データやテキストデータを機械学習で利用するDriverless AIと、画像データを深層学習で利用する「IBM Visual Insights」(本記事の初出時は「IBM PowerAI Vision」。Web掲載にあたり現在の製品名に変更。以下、Visual Insights)である。
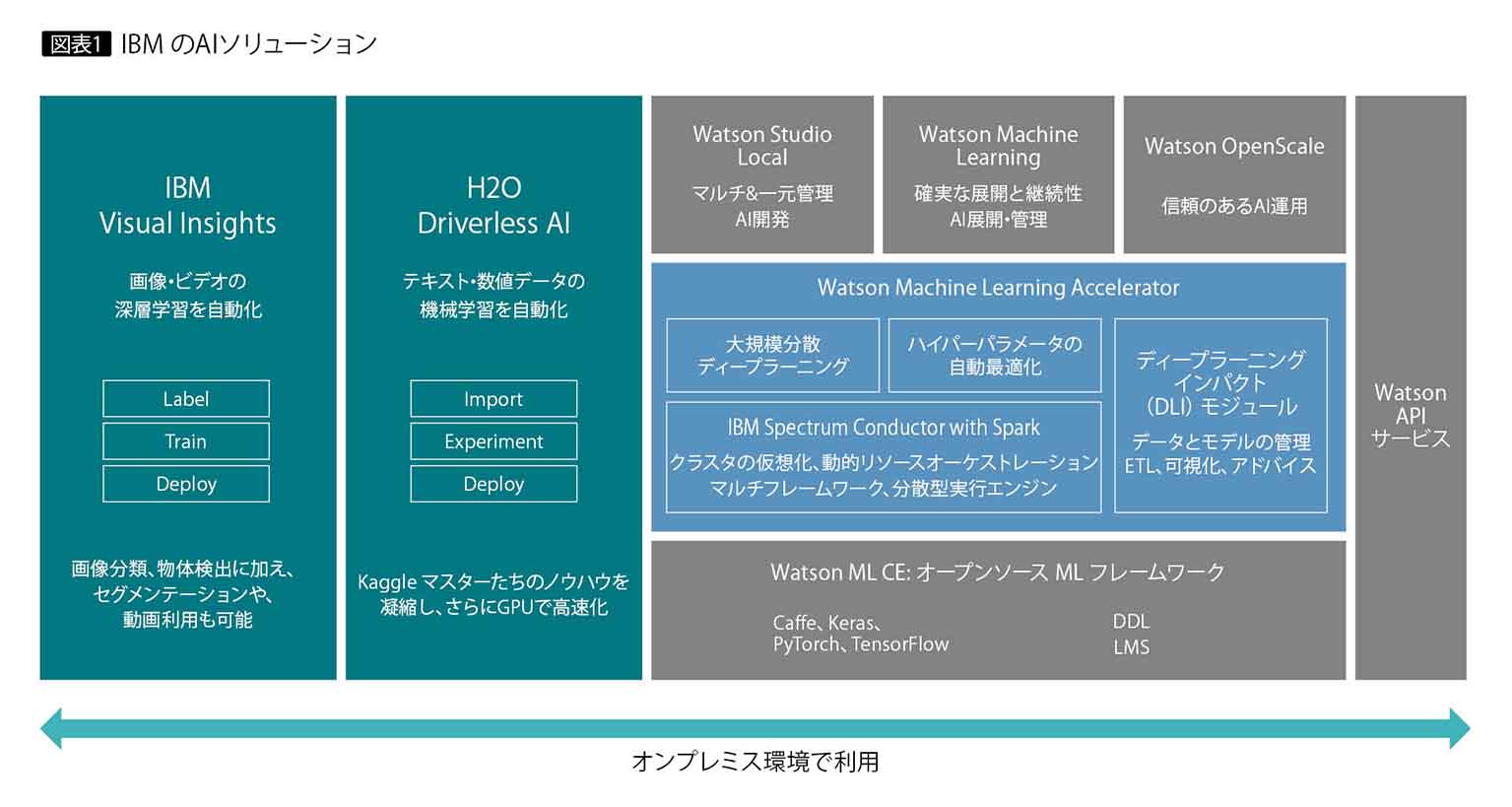
数値データやテキストデータを活用するDriverless AIと、画像データを活用するVisual Insightsの両輪で、Power SystemsでのAI活用領域を広げようという戦略である。
どちらもオンプレミスでの運用が前提で、推奨モデルは「Power System AC922」。NVIDIA社との共同開発によるGPU、すなわちNVLink 2.0で接続される「NVIDIA Tesla V100」を搭載し、AIやアナリティクスの利用に最適化したPOWER9サーバーである。
またDriverless AI とVisual Insightsはともに、「PowerAI」と呼ばれるフレームワークをベースにしている。Visual Insights にはCaffe、Keras、PyTorch、TensorFlowをはじめ、IBM独自のフレームワークであるDDL(Distributed Deep Learning)やLMS(Large Model Support)などが用意されており、ハードウェアと並んで処理の高速化に貢献している(図表2)。

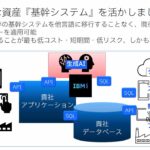
Power Systemsに搭載されるIBM i上では、多くの基幹システムが稼働している。IBM iユーザーにとっては、基幹データを運用するのと同じプラットフォーム上で、基幹データを活用した各種の予測分析を実現できる点は大きなメリットと感じられるだろう。またクラウドの普及が進む一方で、重要な基幹データを社外のクラウドサービスで利用する際のセキュリティリスクを懸念し、オンプレミスでの運用を望む企業は少なくない。
「そこでIBM iの販売に実績のあるイグアスでは、こうしたニーズのあるお客様に向けて、Driverless AIを積極的に提案していきます。すでにビジネスパートナー様を経由し、基幹データを活用して予測分析を実現したいというDriverless AIの案件が何件も寄せられています」と語るのは、イグアスの藤沼貴士部長(製品&ソリューション事業部 ソリューション本部 テクニカル&サービス推進部)である。
データサイエンティストの
高度なノウハウを製品化
一般に数値データやテキストデータを使って、機械学習で需要予測をモデル化するには、経験のあるデータサイエンティストの存在が不可欠と言われる。しかし専門的な知識を備えるデータサイエンティストは不足しており、社内での育成にも限界がある。
Driverless AIの最大の特徴は、トップクラスのデータサイエンティストだけがもつノウハウをソフトウェア化し、機械学習に必要なモデル作成業務を自動化・高速化している点にある。
製品名のDriverlessにある「Driver」は、データサイエンティストを意味する。つまりデータサイエンティストと呼ばれるAIの運転者(ドライバー)が不在でも、機械学習による予測分析を自動的に実行するソフトウェアなのである。
世界中のデータサイエンティストが最適モデルを投稿して競い合う、「Kaggle」と呼ばれるコンペサイトがある。優秀なAI人材の宝庫として注目されるKaggleの最上位入賞者であるGrand Masterは、世界で100名しかいないが、そのうちの7名がH2O.ai社に在籍している。そのほかにも130名以上のAIエキスパートが同社に所属しており、彼らの高度なノウハウをDriverless AIに集約することで、高速・高精度な機械学習フローの自動化に成功した。
通常、機械学習では図表3のようなライフサイクルに沿って、各種のノウハウが必要となる。
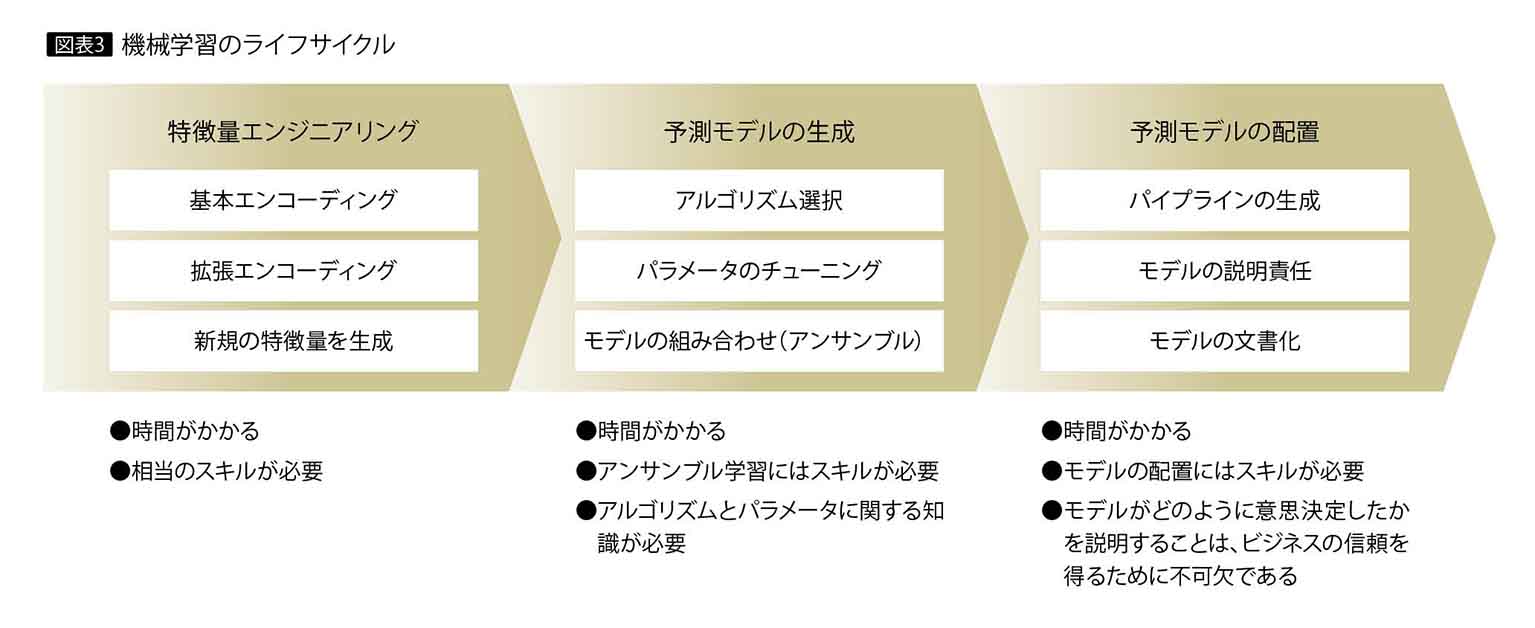
たとえば特徴量エンジニアリングでは、機械学習モデルの性能を向上させるため、新しい特徴量の追加、既存の特徴量の変更、不要な特徴量の削除など特徴量を設計する人的作業が発生する。あるいは目的に最適なアルゴリズムの選定、複数のモデルを融合させて1つの学習モデルを生成するアンサンブル学習の手法など。こうしたプロセスは通常、試行錯誤を繰り返しながら、数週間から数カ月の工数を要する。
しかしDriverless AIであれば、これらのプロセスがすべて自動化されている。実際には、(1)データのアップロード、(2)ターゲットの選択、(3)モデルの作成・実行という3ステップ(3クリック)だけで完了できる。
「前工程となるデータの準備やクレンジングなどの作業は今までどおり人手で行いますが、特徴量エンジニアリングや予測モデルの作成・配置など、データ投入からスコアリング機能の実装までのプロセスは完全に自動化されており、人的作業は一切不要になります」と、イグアスの大崎了平氏(製品&ソリューション事業部 プラットフォーム製品本部 システム製品営業部)は指摘する。
Driverless AIで利用可能なデータは、数値やカテゴリ分類、時刻・日付、文字列、欠損値などの半構造化データ。予測分析に特化しており、売上・需要予測、生産設備の故障予測、顧客離反予測、不正検知、ダイレクトマーケティングなど業種・業務を問わず、幅広い領域の予測分析に活用できる。
イグアスが販売予測モデルを
Driverless AIで検証
イグアスではDriverless AIの販売開始に際して、実業務に即した具体的な予測分析モデルを作成し、製品の機能や利用時の注意点などを検証しようと試みた。
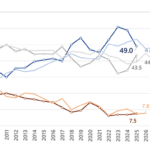
そして社内業務を見渡し、将来の売上を予測してフォーキャストに反映させるため、「見積もり後、どのぐらいの確率で受注できるか」「受注できる場合、どのぐらいの日数で受注できるか」(たとえば、「見積もり提出から30日後に96%の確率で受注できる」など)を予測したいと考えた。そこで見積もりデータと受注データをもとに、Driverless AIを使って、上記の検証を実施したのである。
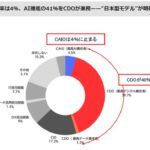
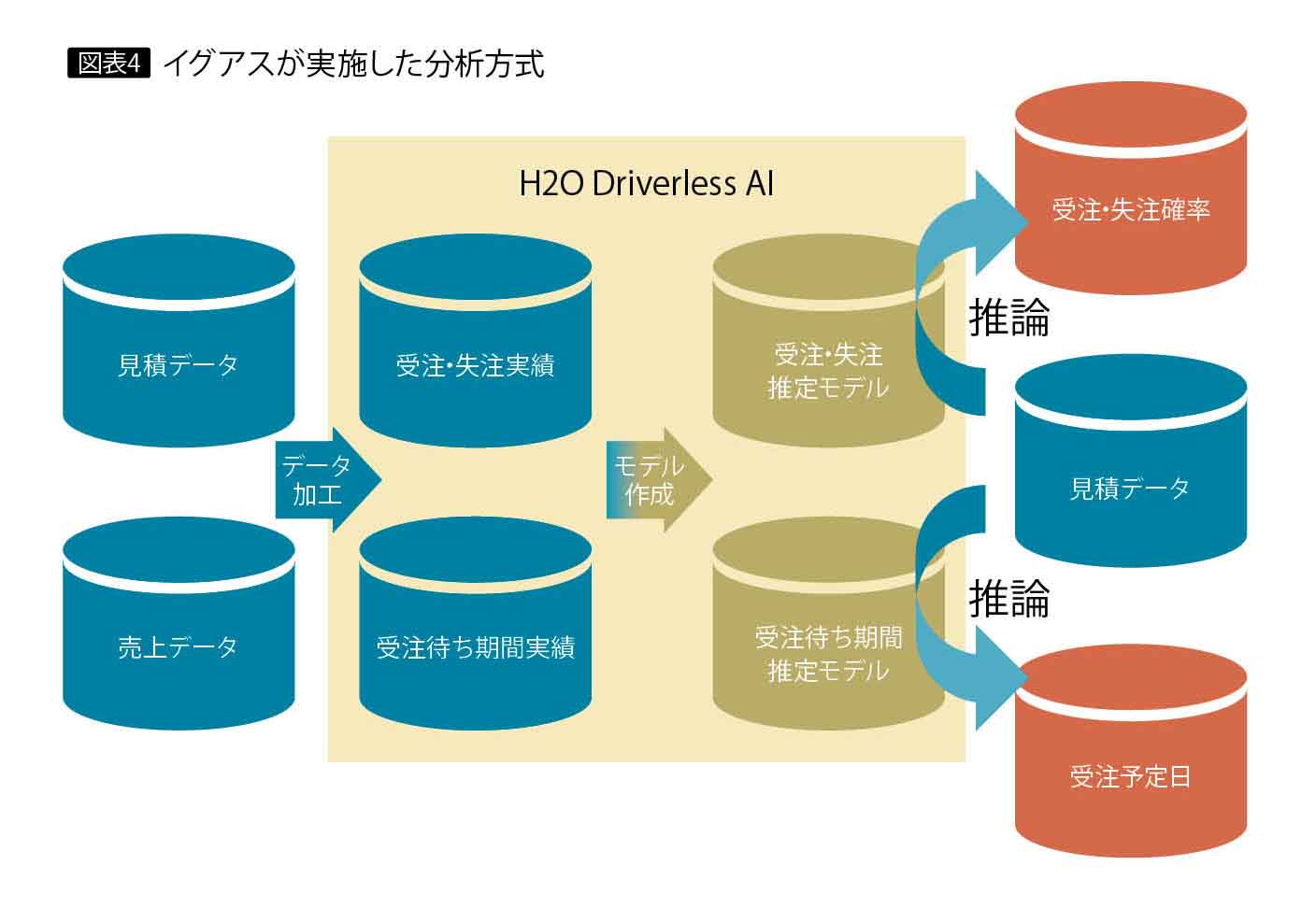
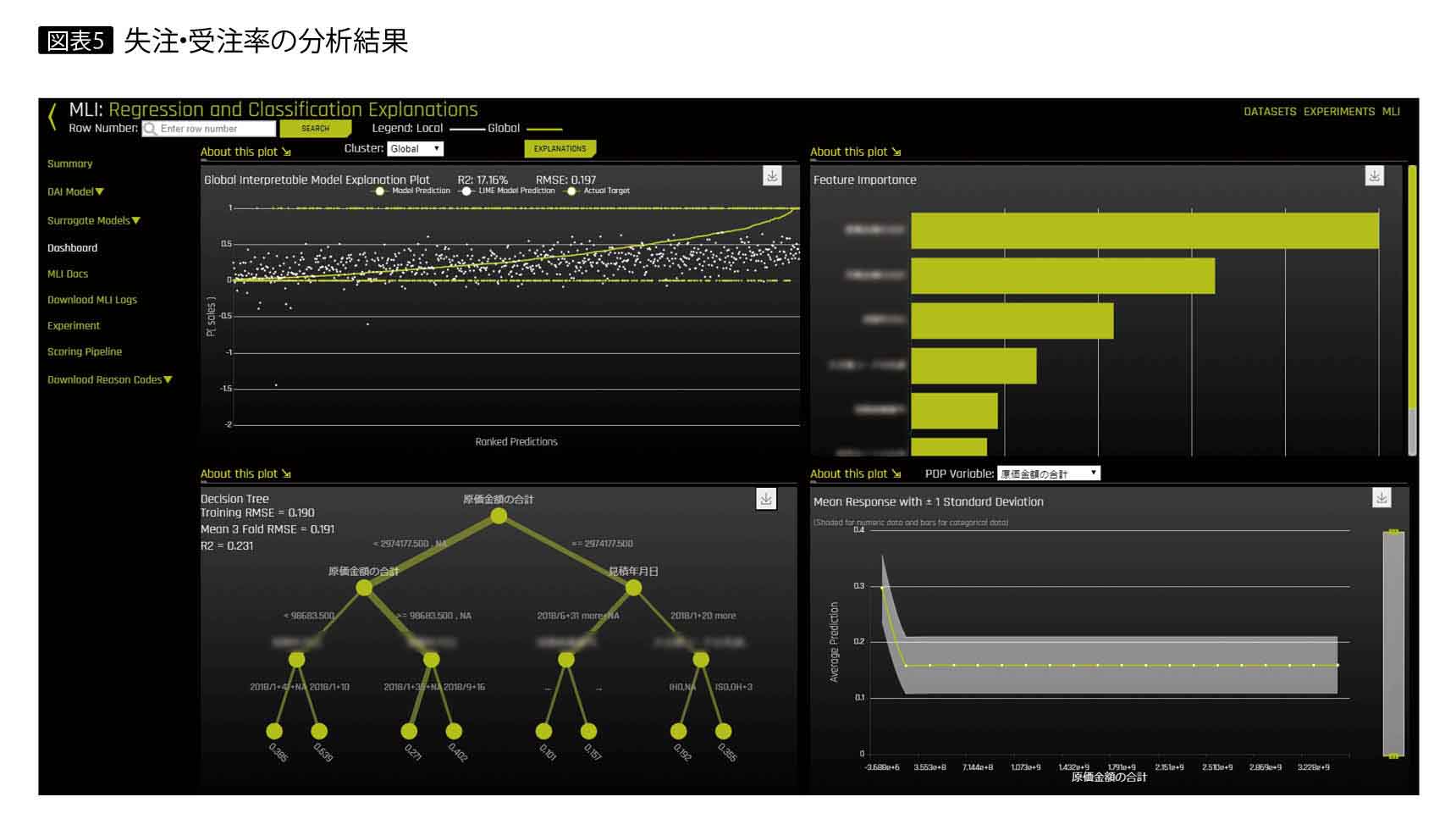
この売上予測では、基幹システムに蓄積した1年分の見積もりデータと受注データに対し、クレンジングを行い、受注・失注実績と受注待ち期間実績データとして、CSVファイルによりDriverless AIに送る(図表4)。ここからのモデル作成は自動的に実行し、ディシジョンツリーを作成して、受注・失注確率(図表5)や受注予定日を出力する。
開発を担当した寿村聡氏(製品&ソリューション事業部 ソリューション本部 テクニカル&サービス推進部)によれば、初めての利用ゆえの試行錯誤はあったものの、データの準備・加工を含めて要した工数は約1週間であったという。
しかし、作成されたモデルの精度は必ずしも高くはなかったと、寿村氏は次のように指摘する。
「特定部門のデータが多いために、モデルが偏ったと判断しました。そこで2回目に、説明変数として部門コードを削除したところ、1回目よりモデルの精度を大きく向上させることに成功しました」
さらに精度を上げていくには、過去データの量を増やす必要があったが、同社では基幹システムのリプレースがあり、現時点ではこれ以上のデータ確保は難しいと判断して、検証作業をいったん終了した。今後の実績データの蓄積を待って、分析を再開する予定だ。
経験豊かなシステム開発者ではあるが、データサイエンティストではない寿村氏でも、わずか1週間で予測分析モデルを作成できた経験から、同社ではDriverless AIの機能性に自信を深めている。今後は、Driverless AIの販売に関してビジネスパートナーを積極的に支援していく計画である。
たとえば同社のGPU搭載マシンを利用して、ビジネスパートナーに向けたDriverless AI やVisual Insightsのデモや研修を実施する。また事例提供やコールセンターサービスなど、通常のソリューションとは異なるAI案件に必要なスキルやサービスの提供に注力していくようだ。



[IS magazine No.25(2019年10月)掲載]