
text:江崎 洋平 日本アイ・ビー・エム システムズ・エンジニアリング
本章では、デジタルサービス・プラットフォーム基盤(以下、DSP基盤)において、マルチテナント環境でのログの「集約」「還元」「閲覧」の要件を、fluetd、LogDNAを使用して実装した事例を紹介する。
DSPにおけるログ管理要件
DSPにおけるログ管理は、システムの利用状況の把握、障害時における問題判別、対監査性の向上などを目的としている。管理の対象となるログは、Red Hat OpenShift on IBM Cloud/IBM Cloud Kubernetes Service (以下、ROKS/IKS)のクラスター、IBM Cloud Virtual Servers (以下、VSI)のOSやミドルウェア、ネットワーク機器といったインフラ基盤から出力されるログのほかに、IBM Cloud上でのAPI操作履歴や、DSPの利用者が開発したアプリケーションから出力されるログもあり、その種類は非常に多い。
また、DSPは複数の利用者が共同利用するマルチテナント環境であることから、各利用者がROKS/IKSのクラスターやVSIに直接入ってログを参照するような運用は避けたいという背景があった。
そこでDSPでは以下の3つをログ管理の要件として定義した。
1 集約
DSP基盤、アプリケーションが出力するログを集約し、長期保管する。
2 還元
DSP基盤によって集約されたログを、所有権を持つ利用者へ還元する仕組みを用意する。
3 閲覧
集約したログをGUI形式で表示できるようにする。
ログ管理のアーキテクチャ概要
この3つの要件を実装するためのアーキテクチャが図表1となる。
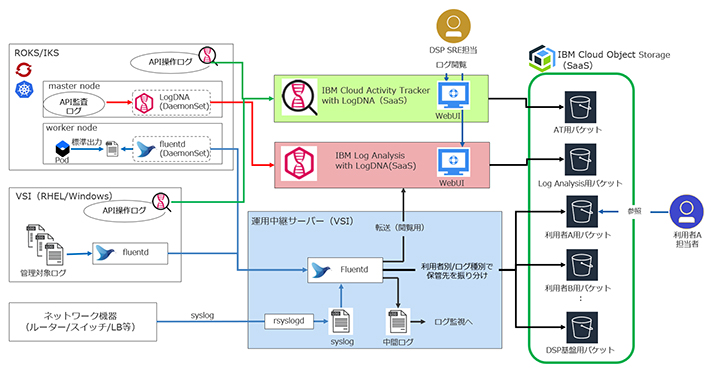
ログの集約にはオープンソースのログ管理ソフトウェアであるfluentdを採用した。運用中継サーバーと呼ばれるVSIに導入されたfluentdがログの集約先となり、ROKS/IKS、VSI、およびネットワーク機器にて出力されたログはfluentdによって運用中継サーバーに集められる。
ROKS/IKSのクラスターでは、ワーカーノード上で動くPodが出力するログが集約の対象となる。各クラスターにてデーモンセットとして稼働するfluentdがPodから標準出力されたログを読み込み、運用中継サーバーへの転送を行う。
VSI上のログについては、各VSIにfluentdを導入し、対象のログを運用中継サーバーに転送する。
ネットワーク機器にはfluentdを導入することはできないため、syslog形式でログを運用中継サーバーへ送信し、運用中継サーバー上に出力されたsyslogファイルをfluentdが読み込む。
そして運用中継サーバーに集められたログは、IBM Cloud Object Storage(ICOS)のバケットに転送し、長期保管する。
ICOSのバケットはDSP利用者ごとに用意し、収集したログを各ICOSバケットへ振り分ける処理は運用中継サーバー上のfluentdが行う。DSPの各利用者には、この利用者用ICOSバケットに保管されたログを見てもらう運用方式とした。
また、DSPでは収集したログに対するメッセージ監視の要件があったことため、運用中継サーバー上のfluentdに集約されたログを監視用の中間ログ・ファイルに出力する処理も行っている。その際、後続のログ監視処理が行いやすくなるよう、さまざまなフォーマットで集められたログを統一されたフォーマットに整形した上で中間ログ・ファイルに出力している。
ただし例外として、fluentdでは収集できないログも存在する。たとえばIBM CloudにおけるAPIの操作履歴が該当するが、これはIBM CloudのSaaSであるActivity Trackerを使って収集する形とした。
またROKS/IKSのマスターノード上に出力されるAPI監査ログについてもfluentdでは収集ができないため、こちらは別のログ管理ソフトウェアであるLogDNAのAgentをデーモンセットとして実行し、同じくIBM CloudのSaaSであるLog Analysisへ送る形とした。なお、これらのログについても、それぞれ専用のICOSバケットで長期保管する。
ログの閲覧については、Activity TrackerとLog Analysisが提供するWeb UI機能を利用する。また、運用中継サーバーに集められたログもこのWeb UIにて閲覧できるように、運用中継サーバー上のfluentdからLog Analysisへログを転送する経路も用意した。
fluentdの実装
1.タグ付け
前述のとおり、ログ管理の対象となるログの種類が非常に多く、またfluentdに行わせる処理内容も複雑であることから、fluentdにおけるタグ付けの設計は非常に重要となる。DSPでは図表2のように、最低7種類の情報をドットでつなげるタグ付けルールを定め、ROKS/IKS/VSI上のfluentd側でタグ情報を付与した上で運用中継サーバーに転送させることにした。
階層 情報 設定値例
1 収集元種別 ROKS-Infra、ROKS-App、IKS-Access、VSI-Linux、VSI-Windows、Network
2 業務種別 infra、app、audit
3 ログ監視の有無 監視対象外:0
監視対象:1~4(通知時のイベント重大度を指定)
4 SW種別 syslog、mw、app 等
5 利用者コード 各DSP利用者に付与した4桁のコード
6 ノード名/Pod名 ROKS、IKS:worker nodeのIPアドレス、Pod名
VSI、ネットワーク機器:ホスト名
7~ 補足情報 クラスター名、コンテナ名、OS名、MW名、ログ・ファイル名 等、必要に応じて階層を追加
図表2 タグ付けルール
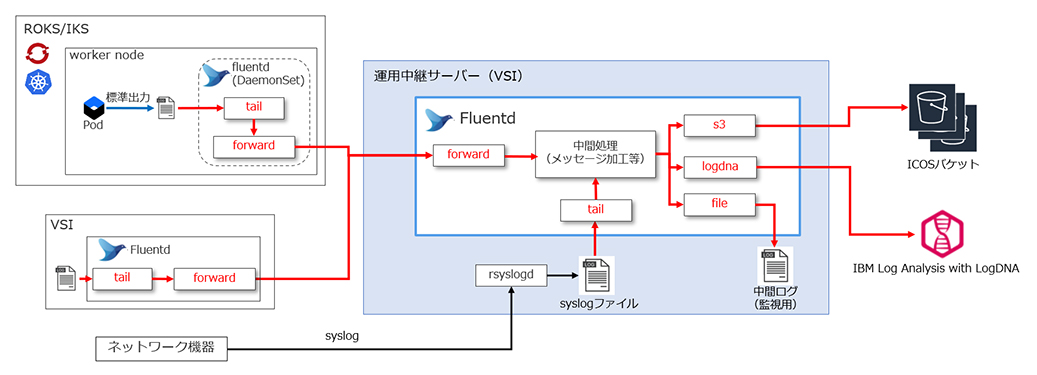
2.使用したプラグイン
fluentdの実装において使用した主なプラグインは図表3のとおり。
プラグイン名 種別 機能
tail INPUT テキスト形式のログ・ファイルを読み込む
forward INPUT
/OUTPUTfluentd同士でのログの受け渡しを行う
s3 OUTPUT ICOSバケットにログを転送する *1
logdna OUTPUT Log Analysisへログを転送する *2
file OUTPUT テキストファイルへログを出力する
図表3 使用したfluentdプラグイン
*1 本来はAWS S3用のプラグインだが、同じS3プロトコルを使用しているICOSでも使用可能
*2 fluentdの標準プラグインではないため、gemコマンドによる導入が必要
これらのプラグインを使ったログの集約から出力までの処理フローの概要は図表4のとおりとなる。
3.処理能力向上のための措置
fluentdのプロセスはシングルスレッドで動くため、運用中継サーバーに複数のCPUが搭載されていたとしてもそれを有効活用することができない。DSPでは非常に多量のログを扱う必要があり、fluentd自体がボトルネックとなる懸念があったことから、fluentdの「マルチ・ワーカー」と呼ばれる機能を採用し、処理性能の向上を図ることにした。
マルチ・ワーカー機能は公式マニュアルにも記載されている手法で、事前に定義した数だけ「ワーカー」と呼ばれるfluentdのプロセスが起動され、それぞれのワーカーに別々の処理を割り当てるため、運用中継サーバーのCPUを有効活用できる利点がある。
このマルチ・ワーカー機能を利用したfluentdの実装結果が図表5となる。
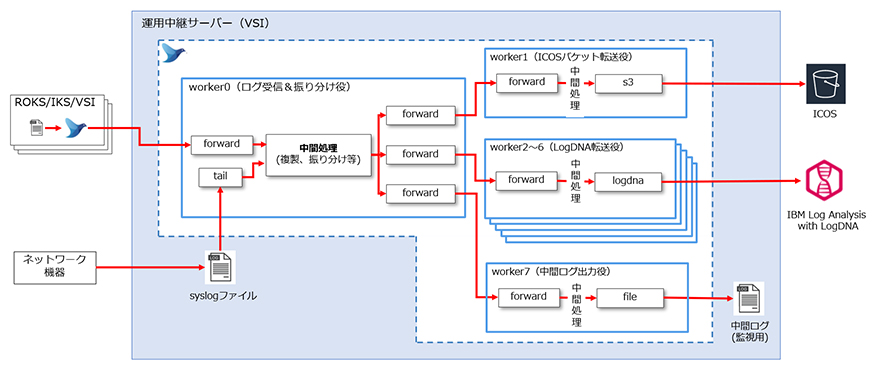
マルチ・ワーカー機能では、各ワーカーに0から始まる数字を採番して区別する。今回は、ワーカー0をログの受信および後続処理への振り分け役とした。そしてワーカー1をICOSへの転送役、ワーカー2~6(*)をLogDNAへの転送役、ワーカー7を中間ログへの出力役と、それぞれ明確に役割を分けた。また、各ワーカー間でのログの受け渡しはforwardプラグインによる内部転送で実現した。
*テストの結果、LogDNA転送の遅延が確認されたため、最終的に5つのワーカーを起動させることになった。
本章ではDSP基盤におけるログ管理の要件、およびそれを実現するためのfluentdを中心とする実装例を紹介した。fluentdに関しては実績の少ない機能やプラグインを取り入れたため、まだ改善の余地はあると思われるが、今回紹介した内容を活用いただければ幸いである。
江崎 洋平 氏
日本アイ・ビー・エム システムズ・エンジニアリング株式会社
クラウド・イノベーション
アドバイザリーITスペシャリスト
2003年、日本アイ・ビー・エム システムズ・エンジニアリングに入社。入社以来、システム運用管理分野のスペシャリストとしてIBM Netcool等のテクニカルサポートを担当。金融系のお客様を中心にイベント管理、ネットワーク監視のシステム構築案件にも数多く参画している。

DSP冒険の書 Contens
0章 はじめに ~発表から1周年を迎えたDSP
1章 ログ管理システムの構築
2章 ジョブ管理システムの構築
3章 クローン環境の構築
このサイトの掲載内容は著者自身の見解であり、必ずしもIBMの立場、戦略、意見を代表するものではありません。
[i Magazine・IS magazine]







