
Text=野村 幸平 日本IBM
データファブリックとは?
データファブリックは、どのような価値を自社にもたらすのか? ガートナーの「2022年の戦略的テクノロジーのトップ・トレンド」(2021年11月、*1)に入ったこともあり、このテクノロジーに関心を持たれるお客様が昨今非常に増えてきた。その中でもお客様との会話において一番よく聞かれる質問が「既存データ基盤との違い」である。本稿では、この問に答える形で、改めてデータファブリックの本質、価値を振り返っていきたい。
データファブリックの定義自体は、IBMをはじめ、ガートナー(「Data Fabric Architecture is Key to Modernizing Data Management and Integration」2021年5月、*2)やフォレスター(「The Forrester Wave:Big Data Fabric, Q4 2016」、*3)でも提唱されている。それぞれの定義に多少の差異はあるものの、その本質は「散在したデータから、利用者が必要としたデータを適切なタイミングで届けること」にあると言える。このデータファブリックの本質をよりわかりやすく解説するために、ここからはIBMのデータファブリックの定義(*4)を前提として、具体的な機能をもとに見ていきたい。
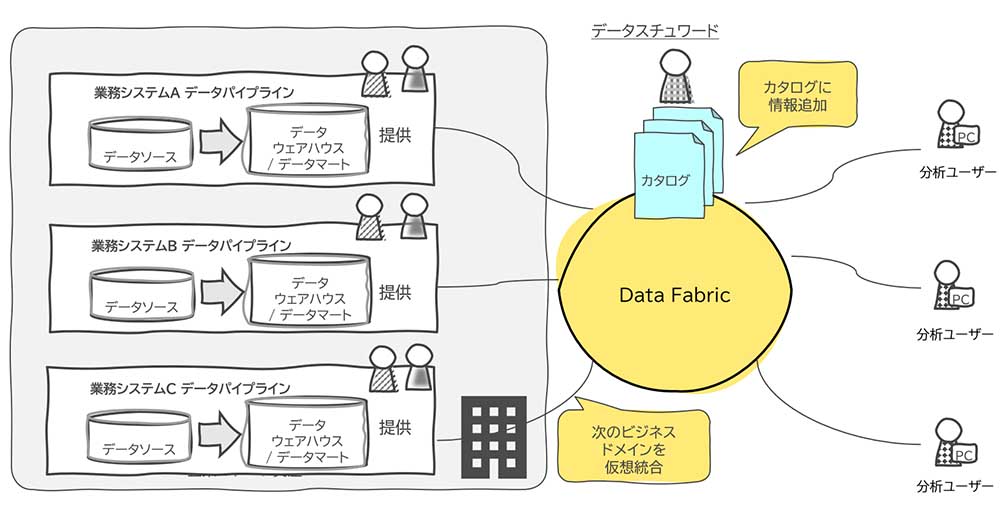
IBMでは、前述のデータファブリックの本質を提供するために、以下の4つの特徴的な機能を定義している(図表1)。
仮想化
クラウド、オンプレミスにまたがるデータを仮想的に統合し、ユーザー側に物理的な場所を意識させない透過的なアクセスを可能にする機能
データカタログ
データに対する理解を深めるための情報を利用者に提供する機能。具体的にはそのデータに付随するビジネス、およびテクニカルメタ情報をカタログとしてユーザーに提供するほか、リネージュ(来歴)や、データ品質に関わる情報も提供する
セルフサービス
必要なデータを必要なときに自分で探し出し、取得するためのさまざまなユーザーインターフェースを提供する機能
データガバナンス
ユーザーやグループごとのアクセス制御や、たとえば個人情報保護法に違反するようなデータをマスキングする、などコンプライアンスを遵守するためのデータに対するガバナンスを実現する機能
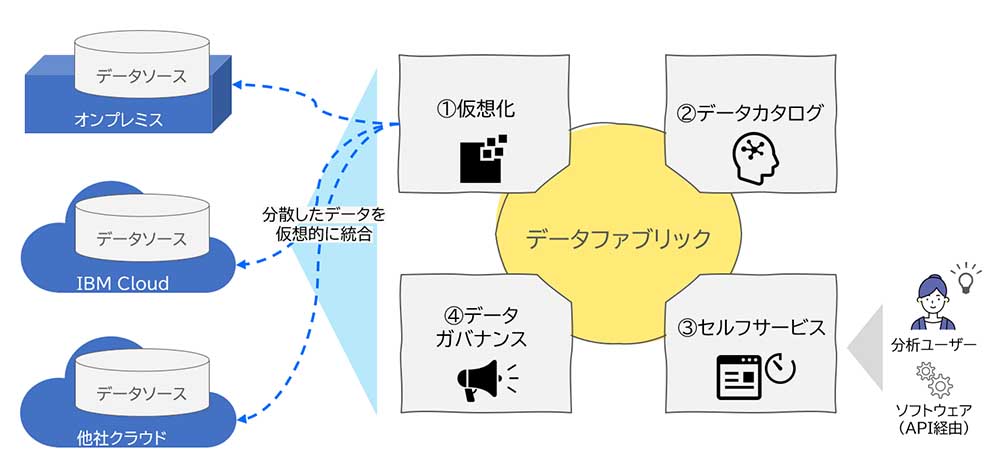
これらの4つの機能は、それぞれ独立して稼働するというよりは互いに連携しあって稼働する。たとえば、ユーザーが必要なデータを「セルフサービス」で取得する際には、「データカタログ」が提供するメタ情報にアクセスし、また見つけたデータを実際に利用する際には「仮想化」の機能で必要なデータが取得される。さらには、ユーザーにデータが渡されるタイミングには、自動で「データガバナンス」が働き不要なデータがマスキングされ提供される。このように各機能が連携しあって、データファブリックとしての機能を成り立たせているわけである。
既存データ基盤との違いとデータファブリックの価値
データファブリックの概要を理解したところで、ここからは図表2を見ながら、従来の中央集権型のデータ基盤との違いを考えていきたい。従来のデータ基盤は、図表2の上部にあるような3層構造を取ることが多く、その特徴としては、ユーザーの「決まった用途」のために必要なデータを、指定の時刻までに用意することに主眼を置いてきた。指定の時刻まで、ということがポイントで、どのような大量のデータであっても分散処理技術などを活用し、必ずそのデータパイプラインを完了するといった高い非機能要件が求められる。このような高い非機能要件を満たすためには、データ活用のユースケースをある程度事前に固定化し、データパイプラインの最適化を行うということを実現する必要がある。
一方データファブリックでは、事前に特定のユースケースを固定化することなく、データ利用者が必要とするデータをいつでも組織内から取得することができる。ここが従来のデータ基盤とデータファブリックの最も大きな違いと言える。昨今フォーカスされているデータドリブン経営を実現するためには、データ利用者が思いついたビジネス仮説をさまざまなデータを用いて検証していくことが求められるため、従来のデータ基盤と比較して、データファブリックのアプローチが適していると言える。
このように言うと、従来のデータ基盤よりデータファブリックのほうが優れているように思われる方もいるかもしれない。しかしながらあくまでも主目的の違い、その基盤の用途次第によるものだと筆者は考えている。
たとえばデータ活用のユースケースが決まっているケースにおいては、従来通りのデータ基盤を活用し、適切なデータパイプラインを経たデータを活用することがコスト、パフォーマンスの面でも最適といえるだろう。一方で、さまざまなデータ活用ユースケースを想定しているケースにおいては、事前にデータパイプラインを構築することが困難であることからも、データファブリックを活用することがよいといえる。このようにデータ基盤としての目的とするゴールの違いで、採用するアーキテクチャが変わってくる。筆者はこれら2つのアーキテクチャは相互補完であると考えており、図表2のように従来のデータ基盤の横にデータファブリックを構成することで互いに不足する要件を満たすことが可能となる。
またこのほかのデータファブリックのメリットとして、従来のデータ基盤と異なり、データ収集・蓄積の機能を構築する必要がないことも挙げられる。これはデータファブリックがデータを中央に集めず、仮想化の機能でデータが必要になったタイミングでユーザーが持つサンドボックス上にデータを持ってくるアーキテクチャだからである。昨今のマルチクラウド環境下で増え続けるアプリケーションのデータを迅速に分析に回していくことが求められる現在においては、綿密なデータ収集・蓄積の機能の設計・構築を省略できることは大きなアドバンテージと言える。ただしこのデータファブリックの特性は、データ量が多いケースなどにおいては、データを利用するタイミングでデータソース側からデータのコピーを行い、また場合によってはETLをユーザー側で行う必要がある。そのため、最適化されたデータパイプラインをもつ従来データ基盤と比べると、データ利用までのコストが高くなる傾向にあると言える。
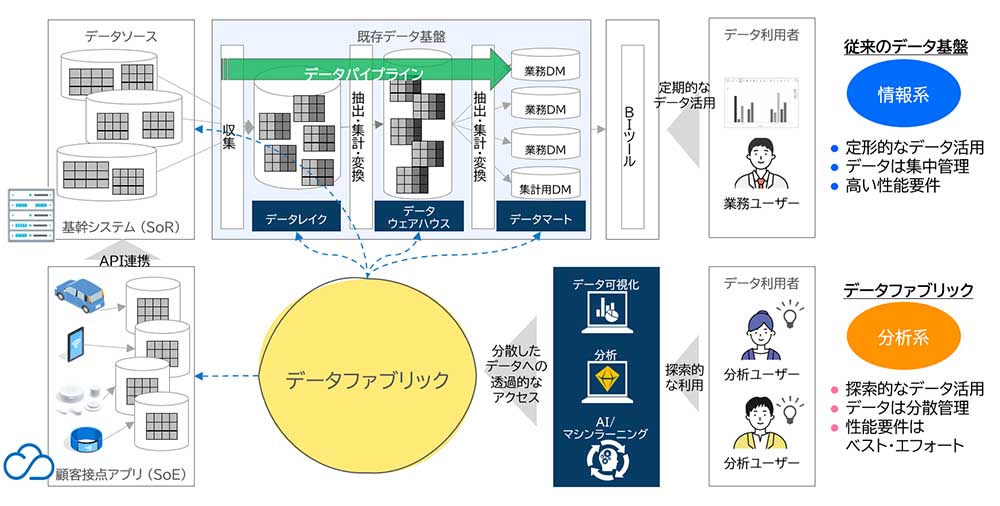
データファブリック適用にむけて
これまで説明してきたように、従来型のデータ基盤とデータファブリックは相互補完の関係にある。また、既存データ基盤をすでに構築済みの企業も多いだろう。したがって、多くの企業においては既存データ基盤を中心におきながらも、図表2で示したように、その横にデータファブリック環境を構築し、データ分析のスモールスタートを行うアプローチがよいと筆者は考えている。
データファブリックを効果的に活用するにはデータカタログの整備が重要になるが、その整備コストを躊躇する企業も少なくない。だからこそスモールスタートが重要となる。企業に散在するデータのうち、ある程度ビジネス価値を見据えた特定ビジネスドメインに対して、必要最小限のデータ整備、またデータカタログの整備から始めていくアプローチである。この過程を通して、データ整備、分析のノウハウを企業に溜め込みながら、段階的にデータ活用範囲を拡大していくアプローチだ。なお、このアプローチを筆者はカタログ・ファースト・アプローチと名付けた。
カタログ・ファースト・アプローチでは、データ活用範囲が拡大していくとともに、データカタログも成長していくことで、企業内に散在していたデータの見通しもよくなる(図表3-1〜図表3-3)。もともと企業内に存在している各種システムが生成するデータをどのように管理し、分析に繋げていくかと悩まれている企業にとっても1つの有効な解になるだろう。
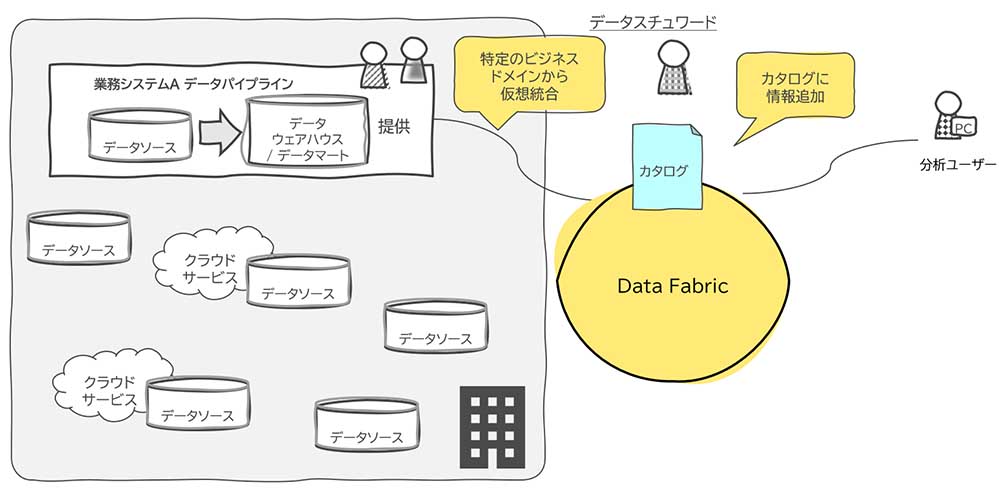
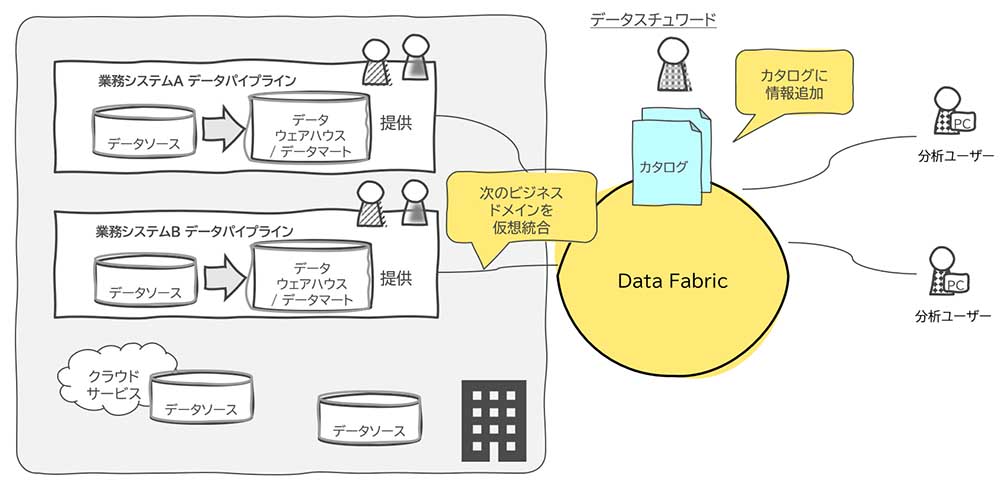
既存の中央集権型のデータ基盤では、昨今の多様化したデータ分析要件を賄うことが難しいケースが頻出してきていることは事実だ。一方で、データファブリックの導入をコスト面、またワークロードの面からも躊躇されたいるお客様にとって、このカタログ・ファースト・アプローチは投資のリスクを押さえた非常に理にかなったアプローチであると考えている。データファブリック適用を検討されている企業にとって本稿が一助となれば幸いである。
◎参考文献
*1 Gartner「Gartner、2022年の戦略的テクノロジのトップ・トレンドを発表」(2021/11)
https://www.gartner.co.jp/ja/newsroom/press-releases/pr-20211117
*2 Data Fabric Architecture is Key to Modernizing Data Management and Integration (2021/5)
https://www.gartner.com/smarterwithgartner/data-fabric-architecture-is-key-to-modernizing-data-management-and-integration
*3 The Forrester Wave:Big Data Fabric, Q4 2016 (2016/11)
https://www.forrester.com/report/The-Forrester-Wave-Big-Data-Fabric-Q4-2016/RES132141
*4 Data Fabric Solutions | IBM
https://www.ibm.com/jp-ja/analytics/data-fabric

*本記事は筆者個人の見解であり、IBMの立場、戦略、意見を代表するものではありません。
当サイトでは、TEC-Jメンバーによる技術解説・コラムなどを掲載しています。
TEC-J技術記事:https://www.imagazine.co.jp/tec-j/
![]()
[i Magazine・IS magazine]









