Text=松本 昇平、徳竹 康成、門野 琢哉 日本アイ・ビー・エム システムズ・エンジニアリング
LinkedInで産声を上げたKafkaが、Apache Kafkaとしてオープンソース化されてから10年以上が経ち、日本国内でもさまざまなところ、さまざまな用途でKafkaが使われるようになってきた。
LinkedInでの使い方のように、Webシステム上のユーザーおよびサーバーから発せられる膨大なアクティビティ・データをKafkaに集約し、リアルタイムにストリーム処理を施すユースケースはもちろんのこと、シンプルにアプリケーションやマイクロサービス間の非同期通信の基盤として、またオンプレミスのデータベースをクラウドにリアルタイム連携するためのデータ連携基盤としてのユースケースなどが挙げられる。
Kafkaのユースケースを大別すると、以下の3つに整理できる。
1 メッセージング基盤
2 データ連携基盤
3 ストリーム処理基盤
本稿では、これら3つのユースケースについて、それぞれに求められる機能を整理し、解説する。また最後に、Kafkaと相性のよいマイクロサービスのアーキテクチャ・パターンについても紹介する。
メッセージング基盤としてのKafka
Kafkaの根幹を成すメッセージング機能は、メッセージング基盤に求められるさまざまな要件を満たすように作られている。
メッセージング機能を解説する前に、その前提となるKafkaの基本構成について簡単に説明しておく。
Kafkaの基本構成
Kafkaでは複数のBrokerでクラスタを構成し、その上にTopicを定義する。クライアントアプリケーションはTopicを介して、データ(レコード)を送受信する(図表1)。
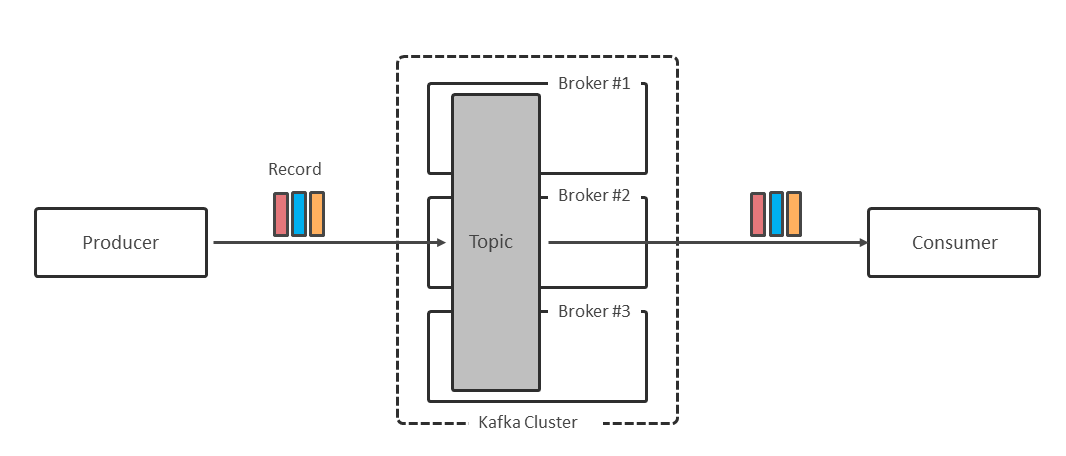
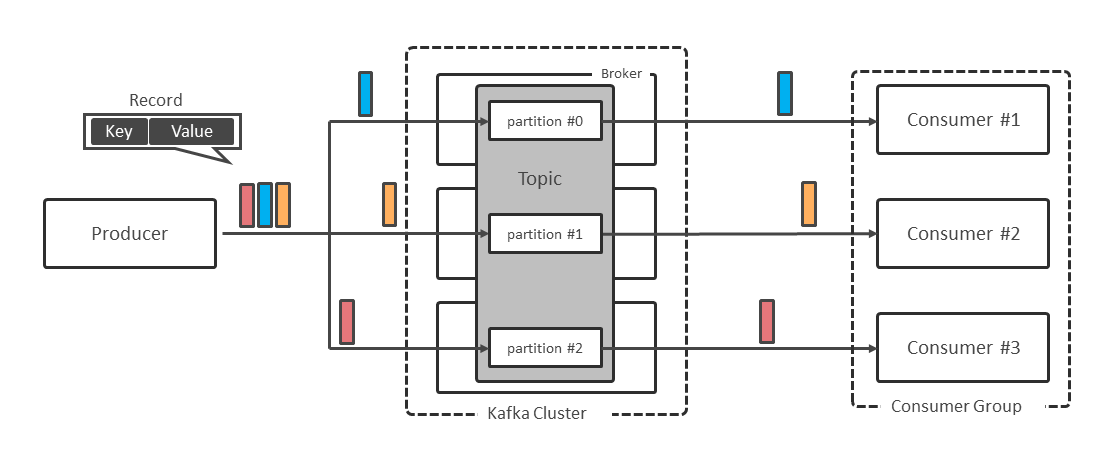
Topicは1つ以上のPartitionによって構成され、ProducerからTopicに送信されたレコードはPartitionに振り分けられる。レコードはKey-Value形式になっていて、デフォルトではKeyのハッシュ値に基づいて振り分け先のPartitionが決まる。このため同じKey値を持つレコードは、同じPartitionに送信される。
Consumerにはグループの概念があり、同じグループIDを持つConsumer同士でConsumer Groupを形成する。グループ内のConsumerにはそれぞれ担当するPartitionがアサインされ、Consumerは自分にアサインされたPartitionからレコードを受信する(図表2)。
ここからはメッセージング基盤に求められる代表的な要件に対し、Kafkaがどのように対応しているのかを解説する。
順序保証
メッセージングの世界では、送信した順番どおりにレコードが処理されることを求めることがある。
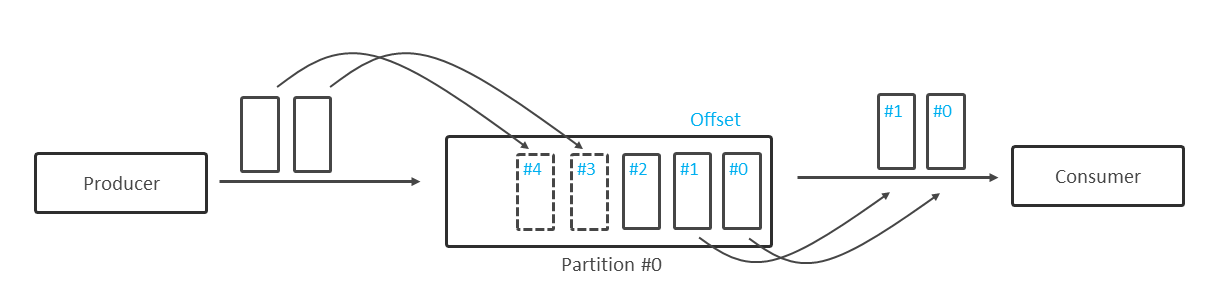
Kafkaでは、Partitionに書き込まれた順にシーケンシャルな番号(Offset)をレコードに付与する。一度付与されたOffsetが変わることはなく、Offsetによって一意にレコードを特定できる。
Consumerは、明示的にOffsetを指定した受信を行わない限り、Offsetの若い順にレコードを受信するため、Partition内ではOffsetによってレコードの順序性は保証される(図表3)。
順序保証の要件には、2つのタイプがある。
1つはすべてのレコードの順序性を保証するタイプ。もう1つは複数のレコードのグループ内でのみ順序性を保証するタイプである。
前者の場合、Topicに送信されるすべてのレコードの順序性を保証するため、Topicを1つのPartitionで構成する必要がある。これによってConsumer側は並列処理を行うことができず、性能や拡張性とのトレードオフとなる。
後者の場合は、グループ内のレコードに同じKey値をセットすることで、グループ単位に同じPartitionに送信できるため、Partitionを複数構成したとしてもグループ内でのレコードの順序性は保証できる。
データ保証
KafkaではPartitionの複製(レプリカ)を持つことで、データの永続性を保証する。Topic作成時にはPartition数とともにレプリカ数を指定できる。複製元のPartitionを「リーダー・レプリカ」と呼び、複製先のPartitionを「フォロワー・レプリカ」と呼ぶ(図表4)。
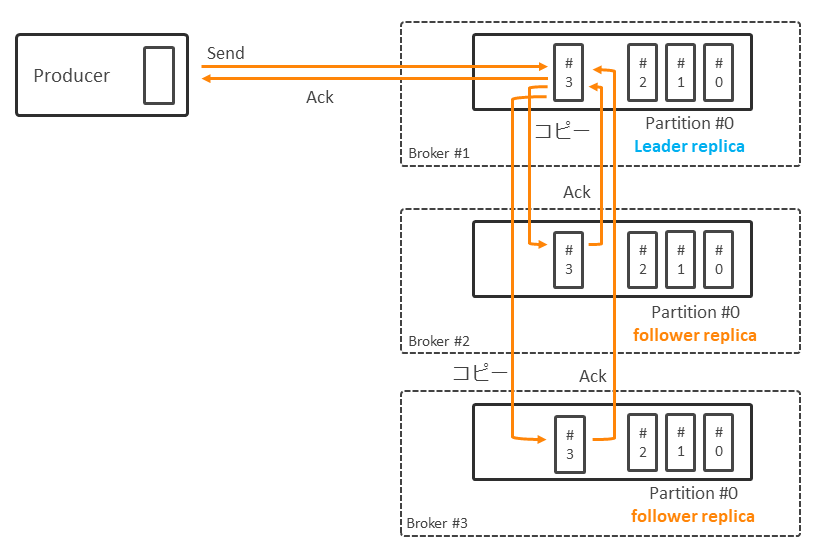
Producerから送信されたレコードがPartitionに格納される際、そのPartitionのフォロワー・レプリカにも同じ内容がコピーされる。
ProducerにAckを返すタイミングは設定次第だが、データの消失を防ぐには、少なくとも1つのフォロワー・レプリカへのコピーが完了したタイミングでAckを返すように設定しておく必要がある。Kafka自身ではディスク書き込み(Flush)は行わないため、レプリカにコピーするにしても高速で処理できる。
送達保証
ProducerからBroker、BrokerからConsumerへとレコードを送り届ける過程で、レコードの消失や重複を排除したいという要件がある。この送達保証の要件には、以下のように3つのレベルがある。
① At Most Once:最大で1回の送達を保証(消失あり、重複なし)
② At Least Once:少なくとも1回の送達を保証(消失なし、重複あり)
③ Exactly Once:厳密に1回の送達を保証(消失なし、重複なし)
ProducerからBrokerへの送達は、BrokerのPartitionにレコードを書き込むことで処理が完了する。この処理では、Exactly Onceの保証を実現できる。
前述のAckの機能だけでは、同じ内容のレコードを重複してPartitionに書き込む可能性があるが、Version 0.11.0から導入されたIdempotent機能を利用することで、確実に1回だけPartitionに書き込むことが可能となる(図表5)。

一方、BrokerからConsumerへの送達は、単にConsumerがレコードを受け取るだけでなく、そのレコードの内容に基づいて何らかの処理(データベースやファイルなど外部リソースへの書き出し処理など)を行うことで完結する。
この一連の処理では、KafkaレベルではAt Least Onceまでの保証となる。Consumerは、どのOffsetのレコードまで処理したかをコミットして、保管できる。
レコードを受信し、何らかの処理を実行してからOffsetをコミットする実装とした場合、コミットの直前でConsumerがダウンすると、Consumer再開時に、前に処理したレコードを再度読み込むことになる。つまり重複処理が発生する。
Consumerおよび外部リソースにて、レコードの内容に基づいて重複排除の仕組みが実装できれば、Exactly Onceを実現できる。たとえばレコード内にユニークなトランザクションIDが含まれていれば、このトランザクションIDをキーに重複処理を排除する仕組みを実装できる。
トランザクション処理
Kafkaでは、Version 0.11.0で導入されたTransaction機能により、複数の送信処理や受信処理を1つのUOW(Unit of Work)として処理するローカル・トランザクションをサポートしている。
ただし、2フェーズ・コミットで実現される外部リソースに対する更新処理も含めたグローバル・トランザクションはサポートしていない。
外部リソースに対する処理とKafkaに対する処理は、それぞれでコミットする必要がある。片方のコミットだけが実行される可能性があるため、トランザクションの不整合が起こり得る。
このようにKafkaではメッセージング基盤に求められる代表的な要件をおおむね実現できる一方で、トランザクション・サポートのように従来のメッセージング技術(IBM MQなど)とは異なる部分もある。
このようなKafkaの特徴を理解した上で、求められるメッセージング要件に応じて、Kafkaと従来のメッセージング技術を使い分ける必要がある。
データ連携基盤としてのKafka
ここからは、データ連携基盤としてのKafkaと周辺システムの関係性について説明する。
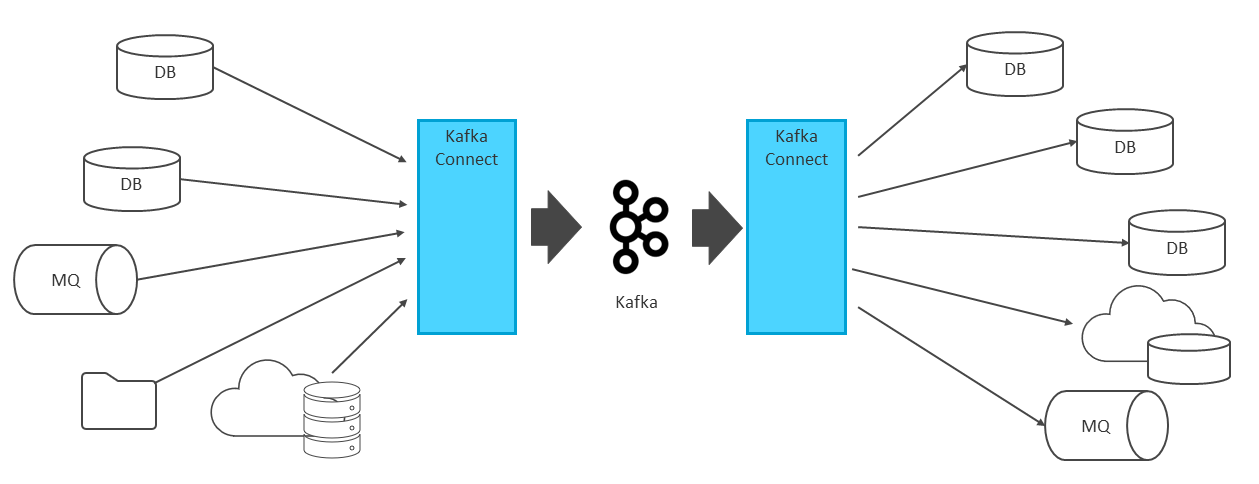
企業のオンプレミスやクラウド環境には、データベースなどさまざまなシステムが存在する。Kafka Connectを使用することで、それらシステムとKafkaを連携できる。
Kafka Connectとは、Apache Kafkaに含まれる外部システムからデータをインポート/エクスポートするためのフレームワークであり、ランタイムである。Kafka Connectにより外部システム間のデータ連携をKafkaに集約し、一元管理できる。
また、Kafka Connectというフレームワークがあることで、多様な外部システムと容易かつ短時間にデータ連携を実現できる(図表6)。
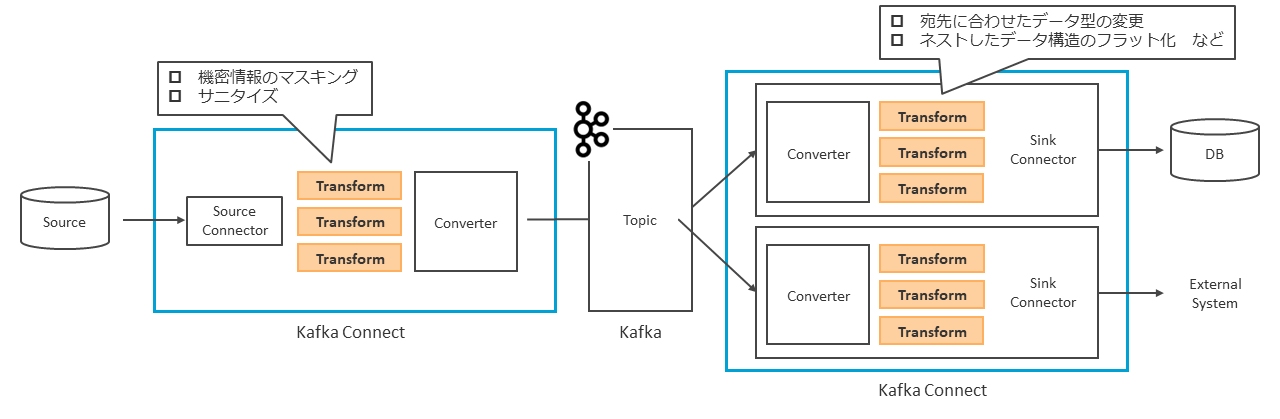
Kafka ConnectはConnector、Transform、Converterという3つの主要なモジュールで構成される(図表7)。
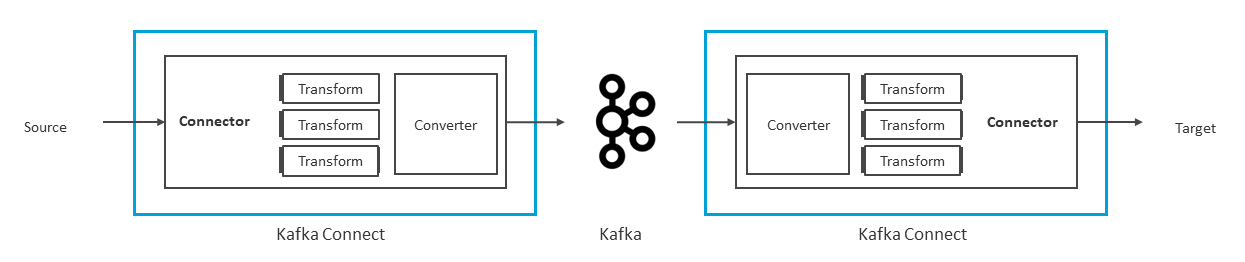
ConnectorがKafkaと外部システム間のデータのインポート/エクスポート処理を行い、そのデータに対してTransformを使用することで、ユーザーやシステムの必要に応じたデータ変更を加えられる。そして、ConverterがKafkaに出入りするデータのフォーマットのシリアライズ/デシリアライズを実行する。
データ連携を行うには、Connectorを外部システムごとにインスタンス化する必要がある。インポート側のConnectorは、外部システムのデータをTopicにコピーし、格納する。
エクスポート側のConnectorは、Topicからデータをコピーし、宛先となる外部システムにデータをエクスポートする。エクスポートされるデータはコピーであるため、同じTopicから複数の外部システムにデータをエクスポートできる。
Kafka ConnectはBrokerとは別の独自のプロセスで実行されており、複数サーバーに配置することでKafka Connectでクラスタを形成できる。これにより、クラスタ内でConnectorが行う処理を分散するロードバランシングや、クラスタ内のあるサーバーがダウンした際に残りのサーバーで処理を継続するフォールト・トレランスなどの機能を利用できる。
ここからは、Kafka Connectを構成するConnector、Transform、Converterの詳細について1つずつ説明する。
Connector
Connectorにはデータ連携を行う向きによって、固有の呼び名が存在する。外部システムからKafkaへデータ連携を行うConnectorを「Source Connector」、Kafkaから外部システムへデータ連携を行うConnectorを「Sink Connector」と呼ぶ(図表8)。
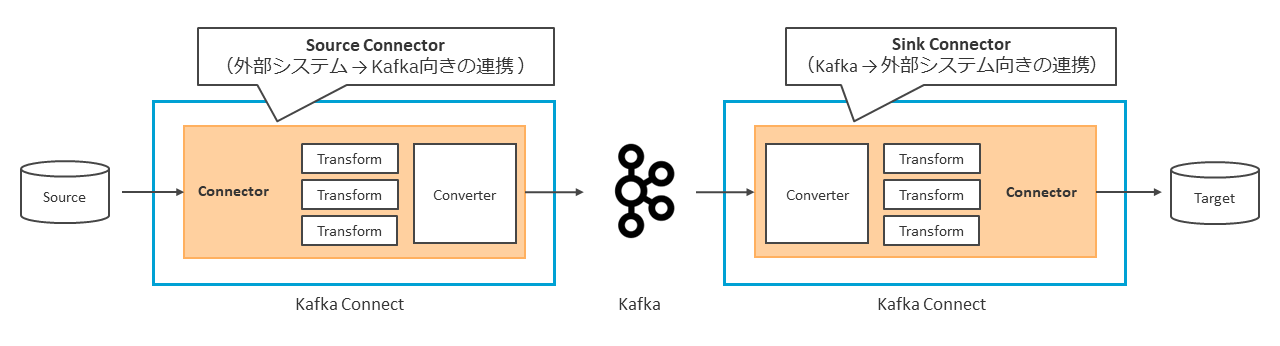
Kafka Connectを使用する最大の利点の1つが、多種多様なConnectorが作り出すエコシステムである。Connectorによりデータ連携可能な外部システムの一部を以下に記載する。レガシー系のシステムからクラウドベースのシステムまで、広い範囲でエコシステムを形成できる。
・Db2やPostgreSQLなどのリレーショナル・データベース
・MongoDBやCassandraなどのNoSQLデータベース
・IBM MQやActiveMQなどのメッセージング・システム
・Amazon S3やGoogle Cloud Storageなどのクラウドオブジェクトストア
・SnowflakeやGoogle BigQueryなどのクラウドデータウェアハウス
エコシステム形成を実現するためのConnectorはすでにいくつも用意されており、Confluent Hubから提供される120以上のConnectorやGitHub、他のマーケットプレイスからもConnectorをインストールして使用できる。
これにより、ユーザーがゼロからConnectorを設計・構築する必要はなく、容易かつ短時間にデータ連携を実現できる。また、既存のConnectorを拡張して使用することも可能である。もし用途に合うConnectorがない場合には、Kafka Connectのフレームワークを使ってユーザー独自のConnectorを作成できる。
Connectorが作り出すエコシステムの中で、最も用途が多いと考えられるのがリレーショナル・データベースとのデータ連携である。
このデータ連携を実現するためのConnectorの選択肢は2つある。1つがJDBC Source Connectorというクエリー・ベースのConnectorである(図表9)。

このConnectorはデータベースに対して定期的にSQLクエリーを実行し、その結果をKafkaレコードとしてKafkaに伝搬する。
ただし、ポーリング・インターバル中、データベースの同じレコードに対して複数回の変更が加えられた場合、最新の状態のみがキャプチャされることや、データベース上からレコードがDELETEされた場合はクエリーを実行できないため、そのレコードはKafkaに取り込めない点などに注意が必要である。
そしてConnectorのもう1つの選択肢が、Debezium PostgreSQL CDC Source ConnectorといったログベースのConnectorである(図表10)。

このConnectorはトランザクション・ログをキャプチャし、更新をレコードとしてKafkaに伝搬する。そのため、DELETEを含むすべての変更をKafkaに伝搬することが可能である。
Connectorの送達保証については、Source Connectorは基本的には最小で1回の送達を保証し、重複の可能性はあるものの、データの損失は起きないことを保証する(At least once)。
Kafka Connectのフレームワークとしては、データの損失と重複がないことを保証する(Exactly Once)ための仕組みは用意されているが、利用できるかどうかはConnectorの実装次第である。
Sink Connectorも基本的にはAt least onceであるが、データベースの一意制約や主キー制約などの外部システムの機能を利用し、二重処理を排除することでExactly onceを実現できる。
Transform
Transformは、ユーザーやシステムの必要に応じたデータ変更を可能にするモジュールである。
データ連携にて使用頻度の高い変換(フィールド名の変更やフィールドのデータタイプの変更、マスキング、レコードのフィルタリングなど)を行うTransformは、Kafka Connectのフレームワークに同梱されている。
また、Confluent HubやDebeziumなどの別コミュニティが提供するTransformをインストールして使用することや、既存のTransformで提供されない変換が必要な場合には、 Custom Transformとしてユーザーが独自に作成することもできる。
TransformはSource ConnectorとSink Connectorのどちら側でも使用可能であり、使い方の明確なルールなどは存在しない。
一般的な使い方として、Source Connector側ではデータ変更を加えず、なるべくそのままのデータをインポートする。理由としては、Source Connector側で特定の外部システムに合わせて細かく変更を加えると、他の外部システムでの再利用が難しくなる可能性が生じるためである。
汎用的なデータフォーマットでKafkaに連携し、Sink Connector側で、利用者が利用したい形に変更を加えることで、レコードを複数のConsumerで読み取れるというKafkaの利点が生きる。例外として、機密情報などの連携すべきでない情報に関しては、Source Connector側でマスキングやサニタイズを実施する(図表11)。
Converter
Source Connector側では、Kafka Connectの仕様として、データをインポートする際には、KafkaでサポートされているAvro、JSON、Protobuf、CSVなどの特定のデータフォーマットにデータをシリアライズする必要がある。この役割を担うのが、Converterである。
Sink Connector側のConverterは、Topicに格納されたシリアライズ済みのデータをデシリアライズして、シリアライズ前のデータフォーマットに戻す役割を担っている(図表12)。
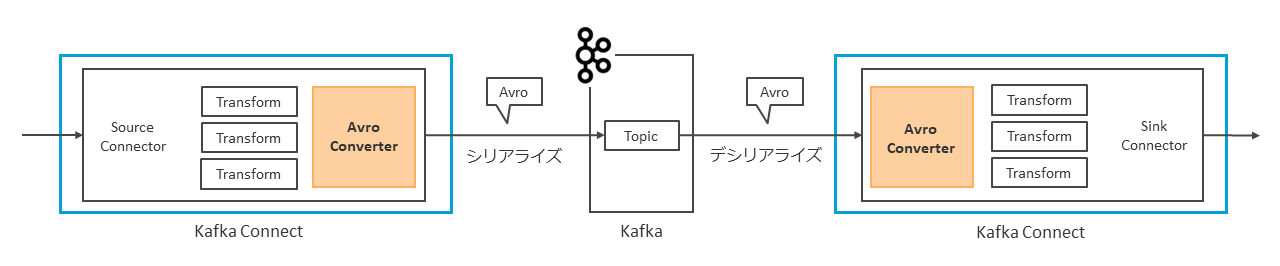
デシリアライズの際には、シリアライズに使用されたデータフォーマットと同じフォーマットを使用する必要がある。
ここまで説明した3つのモジュールを使用することで、データ連携を実現できる。ただしスキーマ情報を持つデータについては、その取り扱いを考慮する必要がある。
データベースのテーブルを例に挙げると、レコードデータとデータ型やカラム名などのスキーマ情報が存在する。Kafka Connectでは、連携するデータの構造を把握するためにスキーマ情報が不可欠であり、スキーマ情報の保管方法やSource ConnectorとSink Connector間でスキーマ情報をどのように共有するか、カラム追加などスキーマ情報の変更にどう対応するかなどについて、考慮する必要がある。
対応方法としては、個々のレコードにスキーマ情報を乗せてインポート/エクスポートする方法や、スキーマを保管するためのサービスを利用する方法などが考えられる。
スキーマの一元管理
Kafkaでは、ConfluentのSchema Registry、AMQ Streamsのapicurioなどを使用することで、Kafkaで扱うレコードのスキーマを一元管理できる。
Schema Registryでは、レコードのKey/Valueそれぞれでスキーマが管理され、スキーマ情報はTopic(_schemas)に格納される。
そのため、スキーマ保管のために別のデータストアを用意する必要はない。スキーマ形式としては、Avro、JSON、Protobufの3つを扱える。
またスキーマのバージョン管理を行い、バージョン間の互換性チェックも可能である。Schema RegistryとKafka Connectを連携させることで、外部システムからインポートされたデータのスキーマ情報が自動的にSchema Registryに登録・保管され、データ連携に利用される(図表13)。
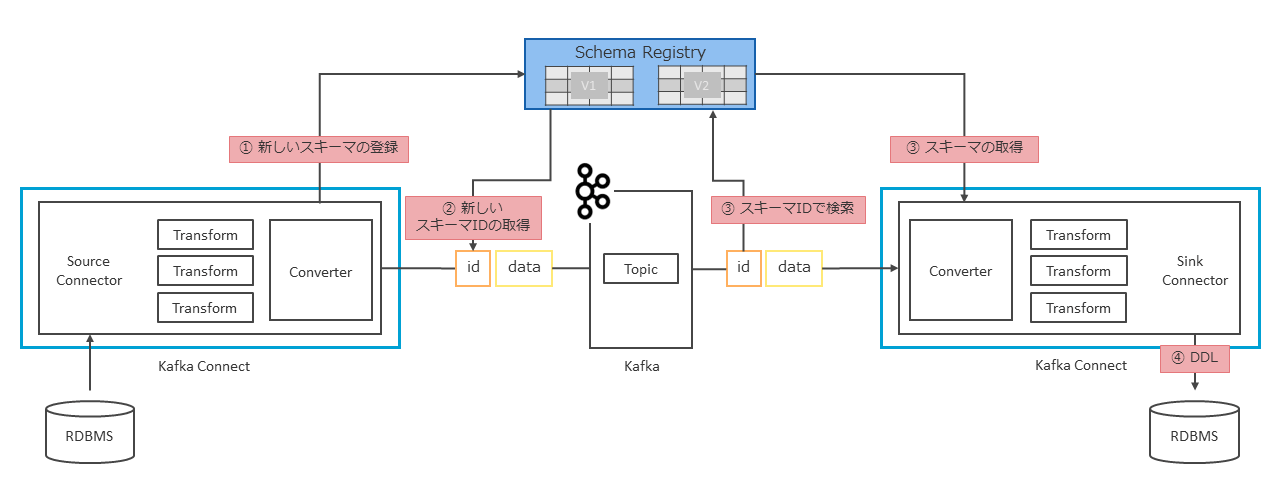
連携方法は、Kafka ConnectのConverterとしてAvroConverter、ProtobufConverter、JsonSchemaConverterのいずれかを使用することで、2つのコンポーネントが連携される。
以下に、Schema RegistryとKafka Connectが連携された場合の挙動について簡単に説明する。
① Converterはデータのシリアライズに加えて、Schema Registryへのスキーマ情報の登録を行う。登録の際には、スキーマに一意のスキーマIDとバージョン番号が付与される。
② シリアライズされたデータと一緒に、スキーマIDがTopicに格納される。スキーマIDが使用されることで個々のレコードにスキーマ情報を載せるより、レコードのオーバーヘッドが減少する。
③ 受け取ったスキーマIDでSchema Registryを検索し、スキーマIDが一致するスキーマ情報を使用してレコードのデシリアライズが行われる。
④ スキーマ情報によりデータ構造を把握でき、データベースであればテーブルの作成や列の追加などのDDLの自動実行、Elasticsearchであればインデックスの自動作成などの追加機能を利用できる。
Kafka Connectを使用してデータ連携を実行する場合、ユーザーが行うのはSource ConnectorとSink Connectorのインスタンスの起動である。
JSON形式で各インスタンスの定義を記述し、REST APIを発行することでインスタンスを起動できる。以下に、Source Connectorのインスタンスを作成するためのJSONの記述例を記載する(図表14)。

プロパティには、Connector共通のプロパティ(ConnectorやTransform、Converter、連携するSchema Registryの指定など)やConnector固有のプロパティが存在する。
上記の記述例では、ConnectorにDebezium PostgreSQL CDC Source Connectorを使用しているため、Connector共通のプロパティに加えて、データベースの接続情報やデータ連携対象テーブルなどを記述する。
Kafka Connectの最大の利点は、多種多様なConnectorが作り出すエコシステムであり、Connectorにより多様な外部システムとデータ連携を行い、Kafkaにデータを集約できることである。
データ連携の中でTransformがユーザーやシステムの必要に応じた変更を加え、Converterが外部システムのデータフォーマットを吸収する役割を担う。
後編で説明するKafka StreamsやksqlDBと組み合わせることで、Kafka Connectによって集約されたデータにさらなる付加価値を与えられる。
後編につづく