Text=滝澤 直也(日本アイ・ビー・エム システムズ・エンジニアリング)
近年、クラウドコンピューティングと生成AIの進歩により、クラウドを通じてAIを利用するクラウドAIが多く利用されるようになった。一方で、エッジコンピューティングとAIを組み合わせたエッジAIという考え方も登場している(What is edge AI?)(図表1)。
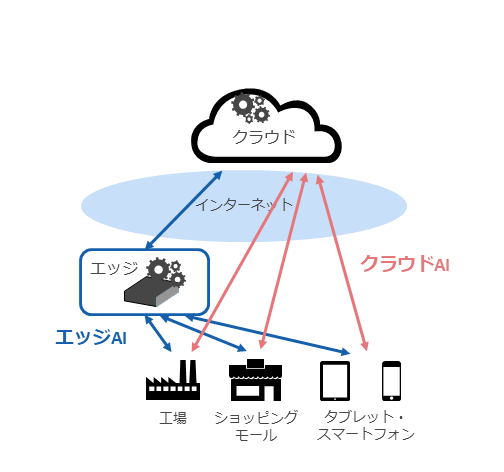
クラウドAIは大規模なデータ処理や大規模・高速なモデルの学習が可能であるというメリットを備えるが、ネットワーク帯域を多く利用するなど、ネットワーク回線品質の影響を受ける点やセキュリティリスクの懸念がある。
それに対してエッジAIは、「リアルタイム処理に有利」「オフラインでの処理が可能」「データの機密性保持が比較的容易」であるなどのメリットをもつが、多数のエッジデバイスに高速なGPUは採用しづらいため、AI処理の速度面ではデメリットがある。
クラウドAIの利用シーンとして考えられるのは、大規模言語モデルの利用、商品の需要予測、大規模モデルの学習などがある。それに対してエッジAIでは、産業用ロボット、工場の生産ライン、店舗での顧客の行動分析へのAIの活用などがある。
本稿で注目するのは、エッジAIとしてのIBM Powerである。エッジAIはセンサーやIoTデバイスでのAI活用だけでなく、オンプレミスで、かつデータの近くでAI処理を実施するケースも含まれる。
IBM Powerはオンプレミスで利用できるプラットフォームであり、スケールアウトモデルからエンタープライズモデルまでを幅広くラインナップしている。特に、全Power10モデルがAIアクセラレーターを搭載しており、これによってエッジAIの高速なAI推論処理を可能としている点が注目される。
Train Anywhere、Deploy here
IBM Powerは、クラウドAIやGPUで学習したモデル(Train Anywhere)を、データが蓄積されたPower上で高速に処理すること(Deploy here)を目指している。そのために、Power10はAI処理アクセラレーターであるMMA (Matrix Multiply Accelerator) を各CPUコアに4基搭載している。
IBM Powerをエッジデバイスとして利用することで、これまでCPUではリアルタイム処理が難しかった重たいAI処理を、エッジで処理することが可能となる。さらに、クラウドAIへ送信したくない機密性の高いデータをオンプレミスのIBM Power上でAI推論処理することも可能である。
ここで、IBM PowerでAI処理を実装するには特殊なライブラリなどが必要ではないかとの懸念を抱くかもしれないが、実際にはIBM PowerでのAI処理にはPyTorch、TensorFlow、ONNX Runtimeなど一般的なフレームワークを利用できる。
RocketCE for Powerを使用することで、これらのフレームワークでMMAを利用して処理を高速化することが可能となっている。
さらに、x86アーキテクチャ上で学習されたAIモデルは基本的にはそのままIBM Power上での利用が可能であり、GPUを持つx86サーバーやクラウドAIで学習したモデルをエッジ近傍のIBM PowerでAI推論処理できる。
画像処理におけるCPU/MMA/GPUの性能比較
前述したように、Power10はCPUコアにAI推論処理を高速に処理できるMMAを搭載しているが、実際のところCPUやGPUと比較して、どのぐらい高速なのだろうか。CPUやGPUと比較して、MMAが有利な処理パターンはどのようなケースなのだろうか。
これらを確かめるために、ディープラーニングによる画像処理の一種である物体検出での性能比較と、大規模言語モデルにおける性能比較の検証結果を以下に紹介する。
物体検出における性能比較
物体検出におけるCPU/MMA/GPUの性能比較は、図表2のハードウェア/ソフトウェア構成で実施した。
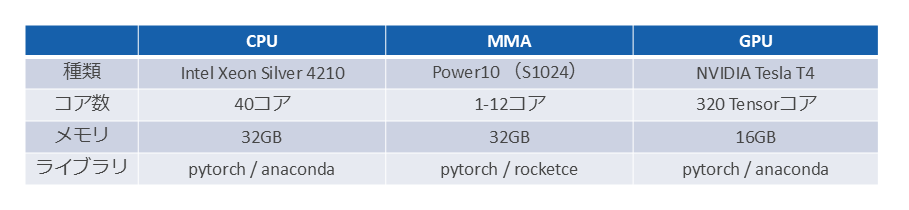
物体検出のモデルはUltralytics YOLOv5を使用し、画像データは640×640ピクセルのJPEG画像を使用した。
検証内容では図表3のようにRESTサーバーを構成し、REST API経由で物体検出の処理を実行した。
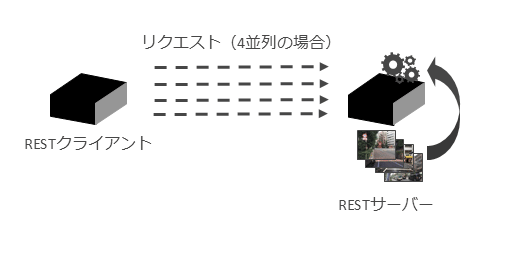
ここでREST APIのリクエストを同時に、かつ並列度を変えて実行し、性能を測定した。並列度は1、2、4、8、16の5種類をテストした。MMAのコア数は1、2、3、4、8、12コアで比較した。比較対象のCPUは40コア、GPUはTesla T4を使用した。
物体検出における性能比較の指標としては処理時間、スループット、応答時間を計測した。
処理時間はRESTの全リクエストを処理するのにかかった時間で、値が小さいほど性能がよいことを示す。
スループットは1秒当たりに処理した画像枚数で、値が大きいほど性能がよいことを示す。
応答時間は1枚の画像を処理するのにかかった時間で、値が小さいほど性能がよいことを示す。
それぞれのテスト結果は、図表4~図表6のようになった。
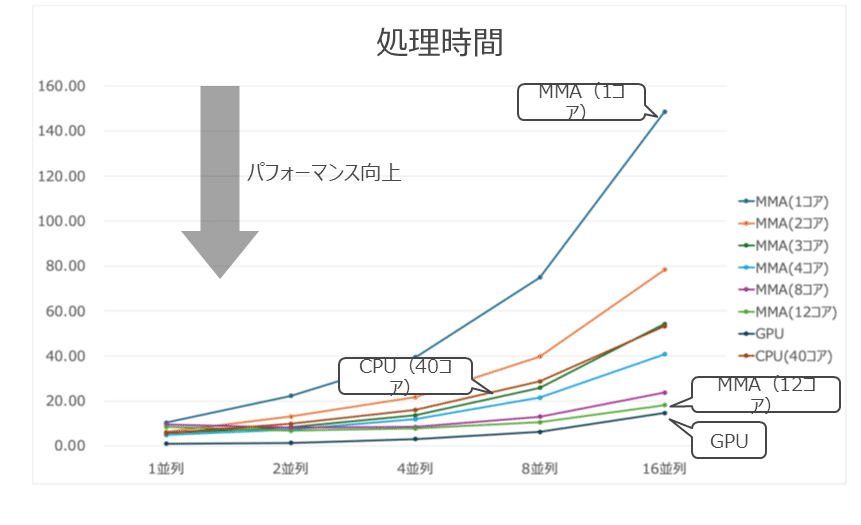
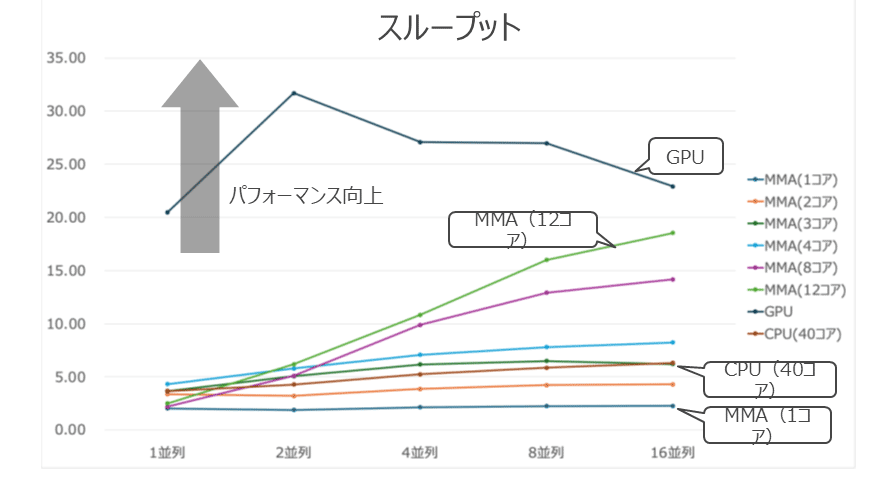
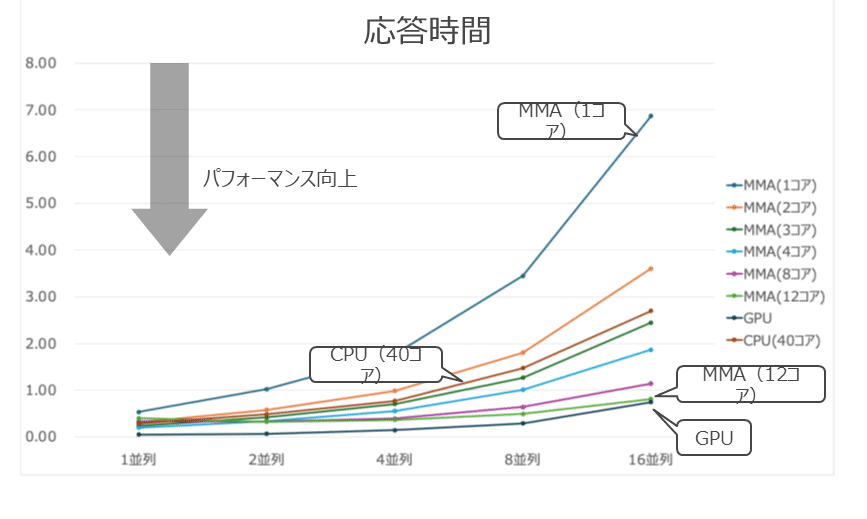
処理時間の結果を見ると、MMAはコア数が増加すると徐々に性能が改善していくことがわかる。今回のテスト結果では、MMAが3コアの場合に、40コアのCPUとほぼ同等の性能を発揮した。さらにMMAが12コアで並列度が16の場合に、GPUの結果に最も近づいた。
スループットの結果を見ると、MMAはコア数と並列度が増加するとスループットが改善することがわかる。一方で、CPUはMMAと比較すると、並列度が増加した際のスループットの改善が小さいことがわかる。また、GPUは今回の検証環境では1GPUの構成であることから、並列度の増加によるスループットの改善は見られなかった。
応答時間の結果を見ると、MMAはコア数が増加すると応答時間が改善し、並列度が増加すると応答時間が悪化していくことがわかる。GPUも並列度が高い場合には応答時間が悪化し、MMAが12コアで並列度が16の場合で比較すると、両者の応答時間の差は10%程度となった。
以上の結果をまとめると、MMAは少ないコア数で多くのコア数のCPUと同等の性能を発揮でき、並列度が高い場合にコア数を増やすことでGPUの性能に近づく傾向があると言える。
今回の検証では実施できなかったが、さらに並列度が高い状況でMMAのコア数を増加させることでGPUを上回る性能を発揮することも期待される。
大規模言語モデルにおける性能比較
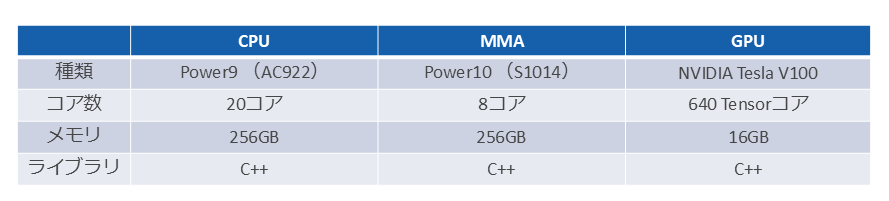
大規模言語モデルにおける CPU/MMA/GPUの性能比較は、図表7のハードウェア/ソフトウェア構成で実施した。大規模言語モデルは、llama-2-7b-chat(INT8)を使用した。
検証内容は図表8のように、IBM Power上で大規模言語モデルを稼働させ、長文プロンプトを投入し、プロンプト処理と生成処理の性能を比較した。
ここで大規模言語モデルはモデルの重みを量子化することで、GPUなしでも大規模言語モデルを稼働させられるllama.cpp を使用した。また、検証に使用したIBM Powerは筐体上の別LPARの影響を避けるために、検証用LPARは占有区画とした。
大規模言語モデルにおける性能比較の指標としては、tokens per secondを計測した。これは1秒当たりに処理するトークン数であり、値が大きいほど性能がよいことを示す。
テスト結果は、図表9のようになった。

大規模言語モデルではGPUが圧倒的な性能を示しており、CPU/MMAともにGPUの性能には及ばないことがわかる。
ただし、MMAで大規模言語モデルが実用に耐え得るかについてはケースバイケースと考えられる。たとえばチャットでの応答を考えた際、短い質問にすぐに回答できれば、長い質問への回答に多少時間がかかっても問題ないと判断できるケースもあるだろう。
上記の観点で見た場合、CPUでの処理は体感として明らかに回答が遅く、実用に耐え得るレベルではないと感じた。一方でMMAは長文プロンプトでは多少遅く感じるものの、ケースによっては実用に耐え得ると考えられる。
以上により、大規模言語モデルではGPUが優位であるものの、たとえばGPUマシンが用意できない場合やクラウド上の大規模言語モデルにアクセスできない環境では、代替手段としてMMAで対応できるケースもあると考えられる。
IBM Power10 (MMA) のユースケース
前述した検証結果から、MMAの特徴として大量のリクエストを複数コアで並列処理する場合、MMAの性能はGPUに近づいていくことがわかった。また、オンプレミス環境でもllama.cppによる大規模言語モデルでの推論処理が実行可能であり、データが配置された場所で生成AIによる処理を比較的低コストで実行可能である。
このような特徴を持つMMAであるが、その性能を発揮できるユースケースには何があるのだろうか。
ここではMMAの性能を発揮するための指標として、リアルタイム処理の必要性、並列処理の必要性、データの機密性の必要性、GPUの必要性を考慮し、例として図表10に示したように、「工場での画像検査処理」「カードの不正利用検知」「システム障害の解析支援」という3つのユースケースについて説明する。

工場での画像検査処理
工場での画像検査処理はラインで生産される製品の画像検査を実施するもので、図表11のような構成が考えられる。
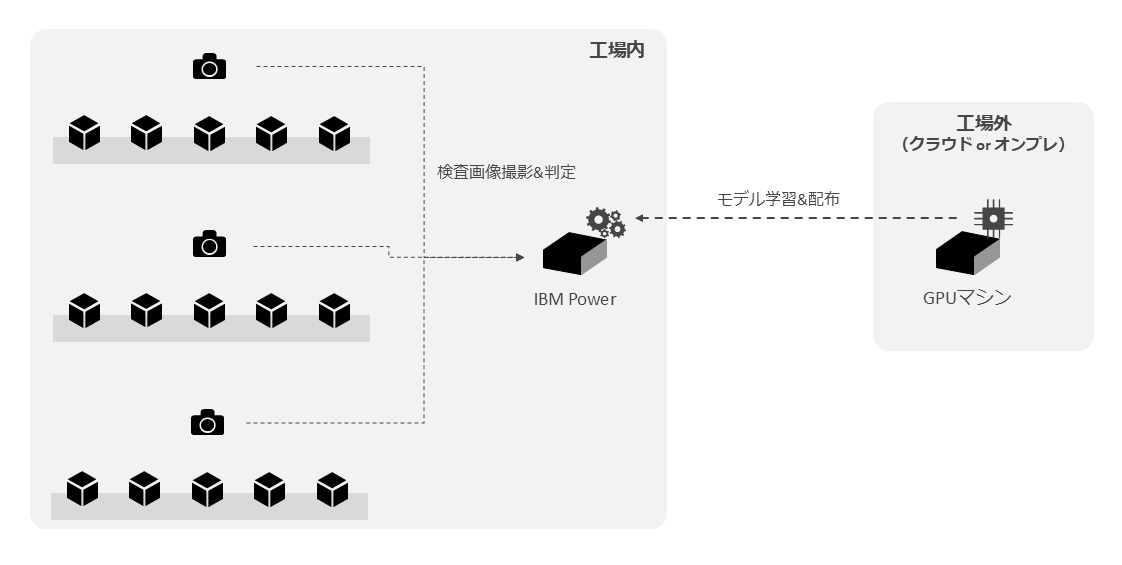
ここでは、工場全体の画像をオンプレミスのIBM Power10 (MMA) により、リアルタイムに画像検査を実施する。画像検査のモデルは、工場外のクラウドまたはオンプレミスのGPUマシンで学習し、工場内のIBM Powerにデプロイする。
製品検査画像は機密情報に相当するケースもあり、応答時間や調達コストも考慮すると、GPUではなく、オンプレミスで処理できるMMAにメリットがあると考えられる。
カードの不正利用検知
カードの不正利用検知はクレジットカードの利用データから不正利用を検知するもので、図表12のような構成が考えられる。
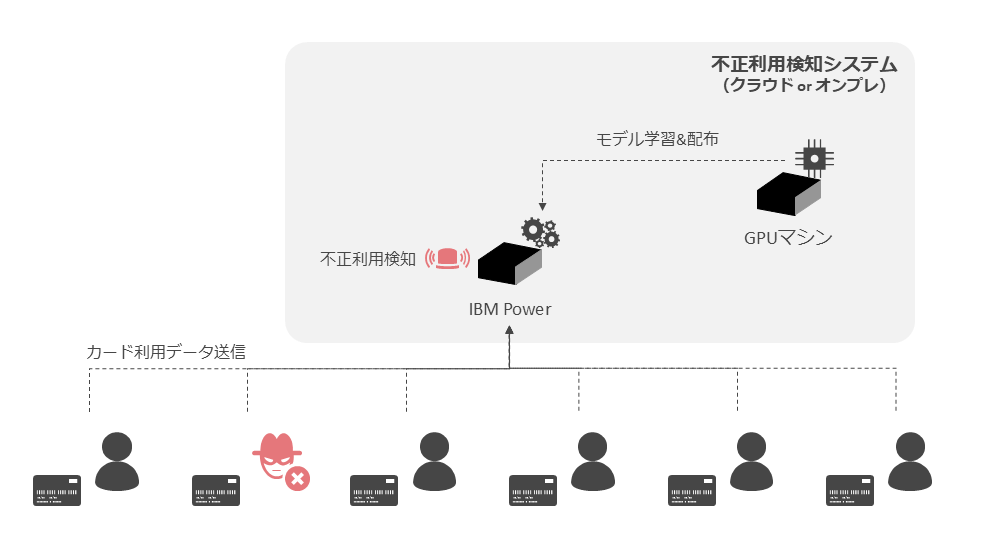
ここでは、カードが利用された場合にネットワークを通じてカード会社の利用情報が送信され、カード会社のシステム上のIBM Power10 (MMA) がカード不正利用検知の機械学習モデルによりカードの不正利用を検知する。
カードの利用データは機密性の高い情報であり、クラウド上のGPUマシンでデータを処理することはリスクとなる。また、カードの利用者は非常に多いと考えられ、データ処理は並列度の高い処理であることを考慮するとMMAにメリットがある。
システム障害の解析支援
システム障害の解析支援は、システム障害時に障害原因の解析を生成AIで支援するもので、図表13のような構成が考えられる。
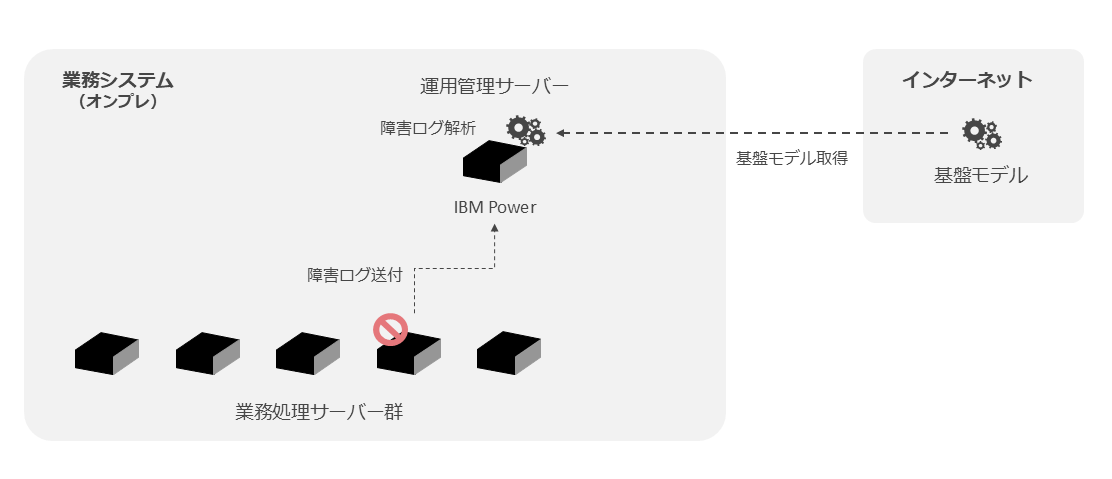
ここでは業務処理サーバーで発生した障害の障害ログをIBM Power10 (MMA) に送付し、障害ログ解析を実施する。ここで使用する生成AIの基盤モデルはインターネット上で公開されているものをダウンロードし、IBM Power上でllama.cppとしてビルドする。
システムの障害ログは機密性の高い情報であり、クラウド上の生成AIを利用したくないケースではMMAにメリットがあると考えられる。
このように大量の並列処理では、MMAがGPUに近い性能を発揮することやリアルタイム性、データの機密性などを考慮した上で、MMAにメリットがあるかどうかを検討してほしい。
また、単純な性能ではMMAよりもGPUが優れているケースが多いと考えられるが、コスト面を考慮した場合に、コストパフォーマンスに優れるMMAが選択肢となるかどうかも検討する価値があるだろう。