Text=菊池 秋郎(日本IBM)、佐藤 なみえ(日本アイ・ビー・エム システムズ・エンジニアリング)、桐ケ谷 昇(日本IBM)、程 智勇(IBM China)
用途探索へのテキストマイニング適用
企業が成長していく上で、自社が保有する技術や製造する素材の新たな用途を探索し、継続的に新製品・サービスを生み出していくことが求められている。
経済産業省による企業アンケート調査(*1)でも、7割以上の企業が研究開発への投資目的は「新製品・サービスの提供」であると、最も多く回答している。
その一方、研究開発の課題として約半数のCTOが「経営戦略・事業戦略との一貫性のある研究・開発テーマの設定」および「研究・開発成果の製品化・事業化率の向上」と回答している調査結果(*2)もあり、多くの企業が保有する技術や製造する素材の具体的な用途・サービスを適切に設定できていない、あるいは見つけるのが困難な状況にあると思われる。
このような企業の課題を受けて、IT技術を活用したさまざまな新規用途・サービスの探索手法が提案されてきた(*3、*4)。これらの手法は専用のITシステムを独自開発して実施していると思われ、多くの企業にとって簡単に実施できないという課題がある。
近年、AI(自然言語処理)を活用したテキストマイニングによる特許分析手法(*5、*6、*7)が注目を集めている。これらは市販製品やオープンソースのテキストマイニングツールを活用したもので、専用のITシステムを開発することなく容易に着手できる利点がある。
この手法は新規用途探索への適用が可能で、実践企業から成果が報告(*8)されている。本稿ではIBMのテキストマイニングツールである「IBM Watson Discovery」を活用して、特許から新規用途・サービスを探索する基本的な手法を解説する。
また近年発展が著しい生成AIを活用して、用途を手軽に探索することも可能である。筆者らも生成AIを活用した用途探索を試行したが、現時点ではテキストマイニング手法と比較するといまだ課題があることが認識できた。
その課題についても解説するとともに、用途探索における今後の生成AIの活用に関する筆者らの見解を紹介する。
特許のテキストマイニング概要
特許を分析対象に用途探索する理由
特許の記載項目は図表1に示すように、国際的な統一様式が定められている。
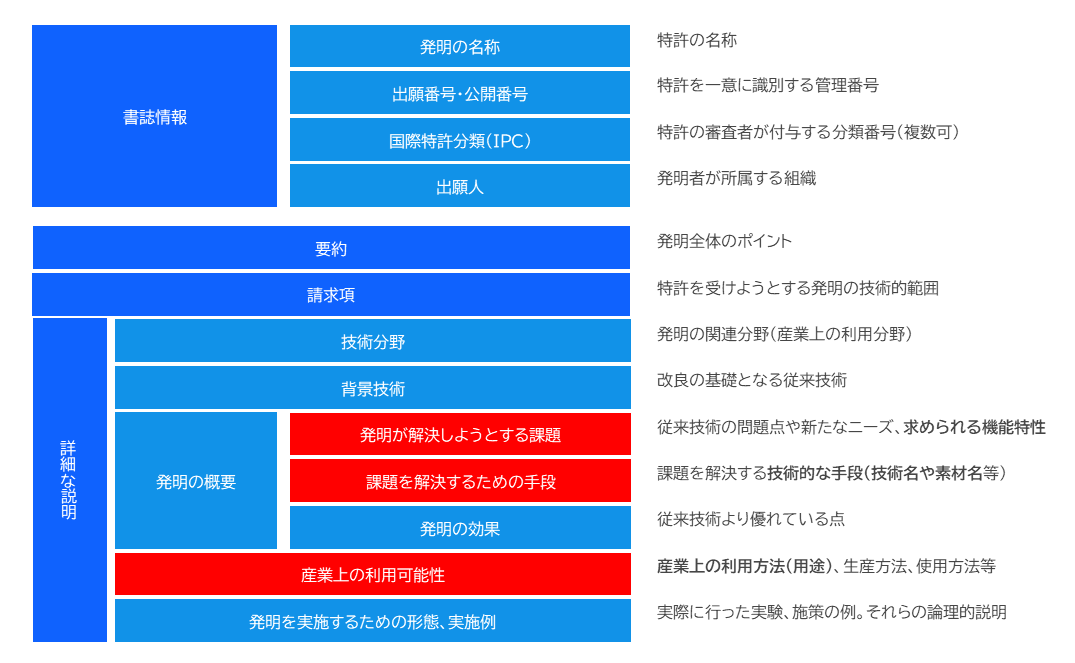
「発明が解決しようとする課題」の項目には用途・サービスに求められる機能特性、「課題を解決する手段」の項目には課題解決に利用する技術・素材名、「産業上の利用可能性」の項目には具体的な用途・サービスが記載されている。つまり、各種技術・素材の具体的な用途・サービスや求められる機能特性が記載されている。
特許は国内では年間約30万件、世界では年間約800万件が申請されており、これらの膨大な数の特許から、技術・素材、用途・サービス、機能特性に関する単語を抽出できれば、自社の技術・素材がどのような用途・サービスに利用されているのか、自社の技術・素材が提供する価値(機能特性)はどのような用途・サービスに求められているのかを網羅的に把握可能となる。
テキストマイニング概要
テキストマイニングはAIの主要技術領域である自然言語処理のテクノロジーを活用したツールで、大量のテキスト中に含まれる単語間の共起関係を可視化する機能を有する。
つまりテキストマイニングツールで特許に記載のある技術・素材とその用途・サービス、および技術・素材が提供する機能特性と用途・サービスの共起関係を分析できれば、容易に自社が持つ技術・素材の既知の用途・サービスや、自社が持つ技術・素材が提供する機能特性を必要としている用途・サービスを探索できるようになる。
テキストマイニングの機能をより詳細に説明する。図表2に、IBM Watson Discoveryを例にテキストマイニングの主要機能を示す。

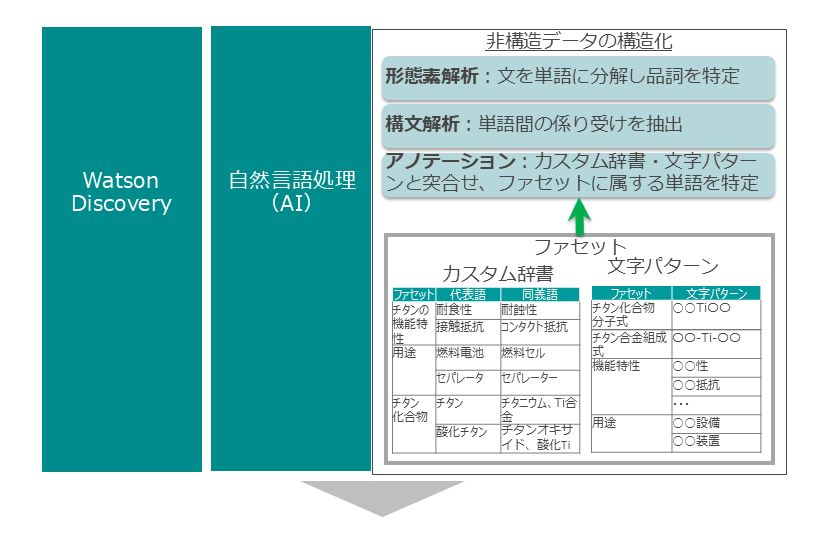

最初にファセットと呼ばれるカスタム辞書や文字パターンをツールに登録する。ファセットは分析の軸となるもので、ターゲットとする市場における各種用途・サービスや用途・サービスに特有の文字パターン(たとえば〇〇装置や〇〇機器等)、分析したい技術や素材が提供する機能特性語などを登録する。
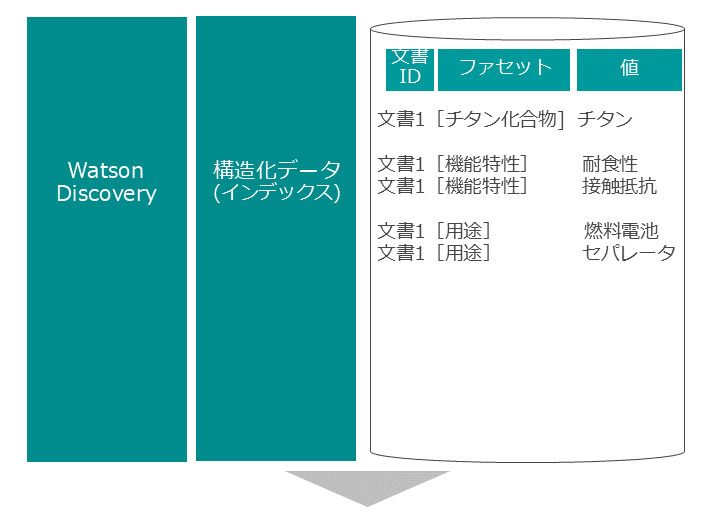
テキストマイニングツールは形態素解析、構文解析、アノテーション等の技術を利用して大量のテキストからファセットに登録した単語・文字パターンと合致する単語を抽出し、構造化データを作成する。
構造化データは、どの文書に、どのファセットの、どの単語が含まれているのかをインデックスにしたものである。さらに、テキストマイニングツールは作成された構造化データを可視化する分析機能を備えており、技術・素材とファセットに登録された単語との共起関係をグラフで示す。
具体的には、技術・素材と共起する用途・サービスを共起文書数や相関値の棒グラフで示したり、技術・素材と共起する機能特性語を含む文書数の時系列推移を折れ線グラフで示す等の機能を提供する。
分析者はこの可視化機能を活用して、ターゲットとする技術・素材と共起している用途・サービスを探索したり、技術・素材が提供する価値(機能特性)を必要としている用途・サービスを探索する。
IBM Watson Discoveryの特徴
IBM Watson Discoveryは、特許を分析する上で優れた機能を有している。具体的には以下のような利点がある。
①超並列処理技術を活用して大量のテキスト(特許)を分析できる
②共起関係を“相関”を利用して表現できる。
以下にそれぞれの利点について解説する。また、近年は生成AIを活用した用途探索も注目を集めていることから、現時点での生成AIとテキストマイニングで用途を探索した場合の差異についても説明する。
大量文書の分析
オープンソースを活用したテキストマイニングの公開事例は、概ね数万件の特許を対象としている。これに対してIBM Watson Discoveryは超並列処理技術を活用して大量テキストの分析が可能で、最大で約1000万件の特許を分析した事例もある。
用途探索を実施する際、広範囲の特許を分析対象としたほうがより多様な新規用途・サービスの候補を得られる。たとえば、国内出願の特許だけを分析するよりも、世界各国で出願された特許を対象としたほうが、より多くの新規用途・サービスの候補を得られる。
またターゲットとする技術や素材が出現する特許に加えて、技術や素材が提供する機能特性、競合技術・素材が出現する特許も分析対象にすることで、置き換え用途の探索も可能となり、さらに多くの新規用途の候補を得られる。
筆者らがこれまでに参加した分析でも、ターゲットとする技術や素材に機能特性、競合技術・素材が出現する特許を追加すると、その数が100万件を超える場合が多くあり、大量文書を分析できることは用途探索を実施する上で非常に重要なポイントとなる。
相関分析
通常のテキストマイニングでは単語間の共起関係を文書数で表現するが、IBM Watson Discoveryは文書数に加えて“相関”と呼ぶ概念で分析が可能で、この機能を活用することで効率的な用途探索が可能となる。
“相関”は確率統計用語の“相関”とは定義が異なり、「検索条件下において全母集団と比較して単語の出現確率が何倍になるか」を示しており、値が高いほど検索条件に特異な単語であることを意味する。
相関を具体的な算出例を用いて説明する。図表3の例では、分析対象とする特許が100万件あり、その中には用途Aが1万1000件、用途Bが300件出現している。
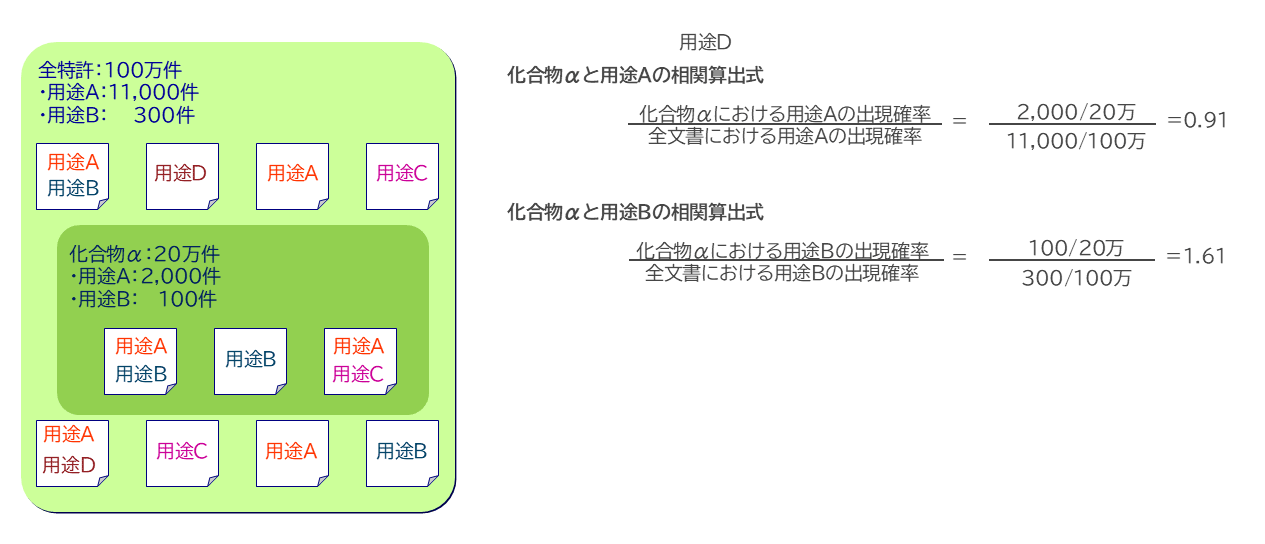
100万件の特許の中には化合物αが20万件出現し、その中には用途Aが2000件、用途Bが100件出現している。従来の文書数をベースとした共起分析では、化合物αと最も多く共起している用途Aが候補になり、共起文書数100件と少ない用途Bは注目されない存在となる。
次に“相関”の視点で考察する。化合物αと用途A、Bの相関は母数における用途A、Bの出現確率と、化合物αと供出する用途A、Bの出現確率の比で算出する。それぞれを図表3の右図のように計算する。
この結果を見ると、化合物αと用途Aの相関は0.91と1以下となることから、全体平均以下の出現確率であることがわかる。つまり供出している特許数は多いが、用途Aは化合物αに特異な用途ではないことがわかる。
一方で化合物αと用途Bの相関は1.61となり、全体平均よりも1.61倍出現していることがわかる。つまり用途Bは、供出数は少ないが、化合物αに特徴的な用途であることがわかる。
このように“相関”の視点で見ると、少数ではあるが化合物αに特異な用途を容易に見つけることが可能となる。
※IBM Watson Discoveryで相関値を算出する際には、さらに区間推定で補正した値を利用している。
図表4に実際の分析例として、酸化チタン(TiO2)と共起する用途関連語(〇〇装置や〇〇システムのパターンを持つ単語)を文書数順(左)と相関順(右)で比較した結果を示す。
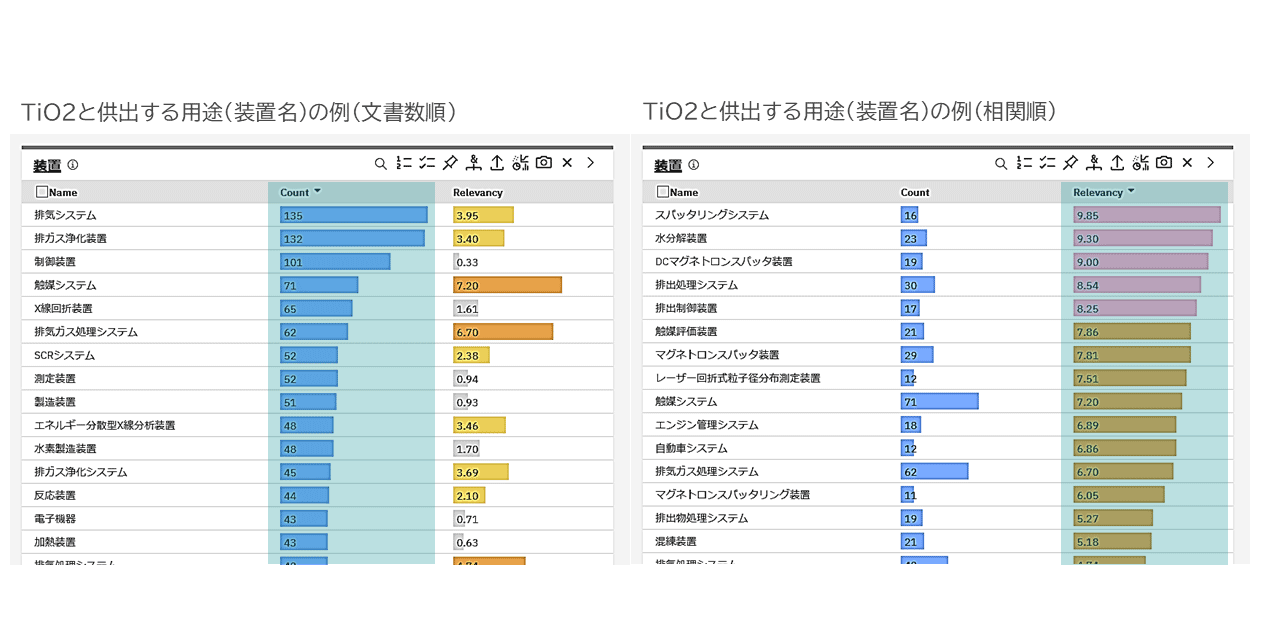
従来のテキストマイニングで用いられる文書数順(左図)を見ると、排ガス浄化関連の装置(排気システム、排ガス浄化装置、排気ガス処理システム、SCRシステム、排ガス浄化システム)名が上位に出現している。
酸化チタンが排気ガス浄化の触媒として利用されていることは、酸化チタンの市場レポートには必ず記載されており、有識者にとって目新しさはない。
これに対してIBM Watson Discoveryに固有の機能である相関順(右図)で見ると、半導体製造における各種スパッタリングシステム、水素製造における水分解装置などが上位に出現している。これらは酸化チタンの市場レポートにも記載はなく、有識者にとっても目新しい用途である。
このように相関を活用することで、ターゲットとなる技術や素材に特有の用途を効率的に探索できる。
分析方法
テキストマイニングを活用した用途探索の代表的な方法は、以下の3種類に大別できる。
・ターゲットとする技術や素材と供出する用途・サービスを探索する方法(既知の用途探索)
・ターゲットとする技術や用途が提供する機能特性と供出する用途・サービスを探索する方法(置き換え用途探索)
・有識者が持つ仮説の検証を通じて用途を探索する方法(仮設検証)
以下に、それぞれの方法について解説する。
既知の用途探索
既知の用途探索では、ターゲットとする技術・素材が出現する特許にどのような相関の高い用途・サービスが供出しているのかを探索する。つまり、他社が既に特許に記載している用途・サービスの中から、自身がまだ気づいていないものを見つける方法である。
通常、ターゲットとする技術・素材の有識者は当該領域の特許について調査を実施済みであることが多いため、得られる結果は既知のものを多く含むが、有識者の調査の網から漏れていたり、近年新たに出現した用途・サービスを検知できる。
最初に分析対象とした特許全体を俯瞰して、未知の用途・サービスが存在するかを確認し、次に事業戦略で重視している領域や有識者が興味ある領域に絞り込んで用途・サービスを探索する。さらに時系列分析で近年増加傾向にある単語を見つけ、そこに新たな用途・サービスが出現していないかを確認する。
以下に、その詳細を解説する。
既知の用途の俯瞰
ターゲットとする技術や素材が、どのような技術領域(IPC、テーマコード)や用途・サービスを意味する単語と相関を示しているのかを確認する。
図表5はチタン化合物とテーマコード(※1)の相関を、出現数が多い単語を対象にネットワーク図で示した例であり、どのチタン化合物がどのような技術領域で活用されているのかを把握できる。
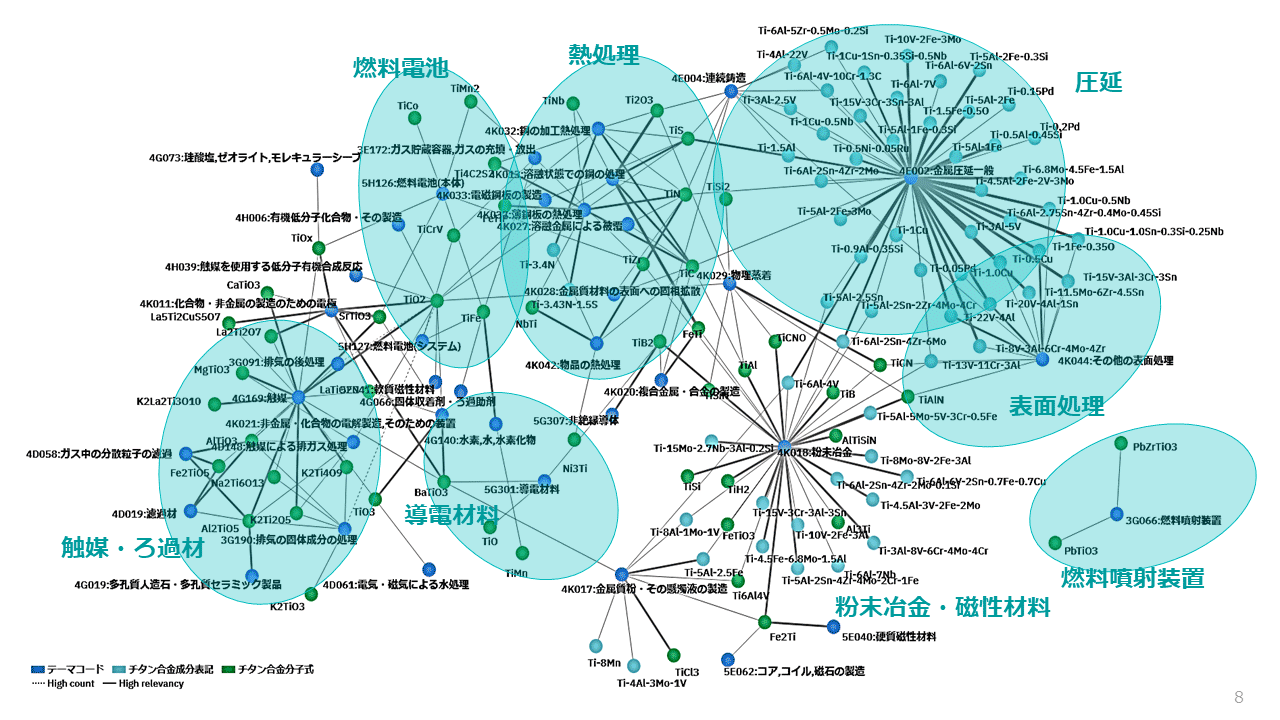
この中に、自社にとって未知の技術領域や用途・サービスが出現していないかを探索する。
※1:テーマコード
日本国特許庁が定義する技術領域。約3400種類の技術領域で構成され、日本国特許庁に出願された特許に対して付与される。同様のものにIPC(国際特許分類)があり、各国の特許庁が出願された特許に付与している。海外の特許を分析する際にはIPCを利用する。
既知の用途の深掘
次に、事業または研究開発戦略上で重要視している領域や、有識者が興味ある領域(従来の方法では有識者が十分に調査できていなかった領域など)に特許を絞り込んだ上で俯瞰する。
図表6は、IPCのFセクション(機械工学、照明、加熱等)に絞り込んで、IPCのメイングループとチタン化合物・合金との相関を見た例である。
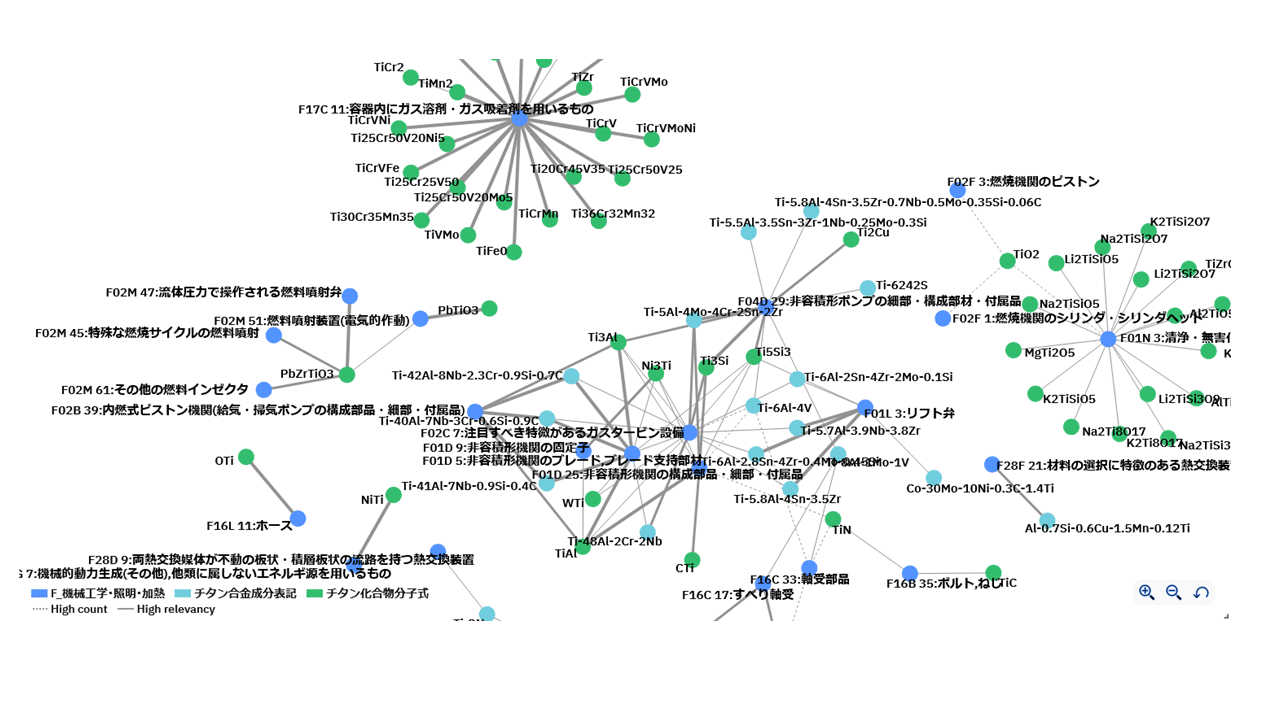
全体を俯瞰した分析結果と比較すると、より具体的な用途を確認できることがわかる。このように、最初は全体を俯瞰し、次に特定領域に絞り込んで再度俯瞰する作業を繰り返し、有識者が認識していなかった新規用途の候補・サービスを探索する。
自社の事業・研究開発戦略に沿った用途・サービスを探したい場合には、ターゲットする領域の用途辞書ファセットを作成して探索する。
たとえば、カーボンニュートラル対応で新たに水素関連の市場が生まれると期待されることから、水素事業に関する用途を探索したい場合がある。
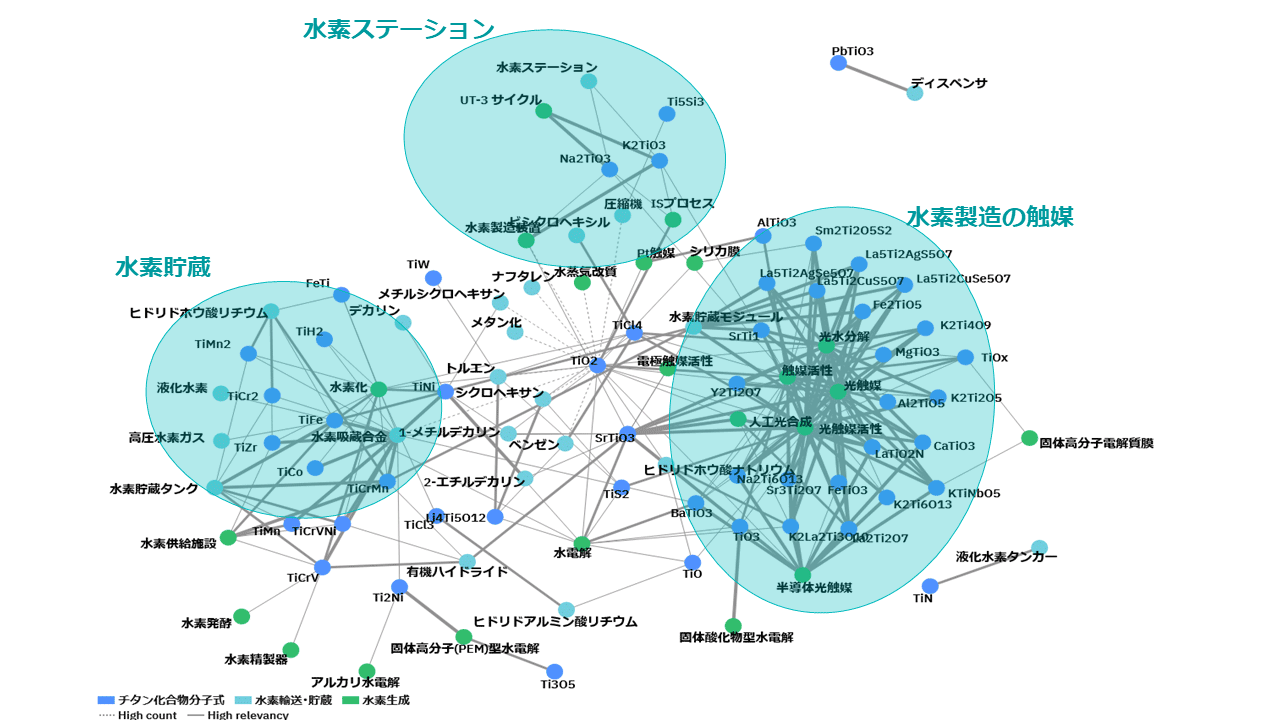
この場合、水素の製造・輸送・貯蔵といったサプライチェーンに関係する装置・設備名のファセットを作成し、自社の持つ技術・素材との相関を確認する。
図表7は、チタン化合物と水素の製造・輸送・貯蔵関連の単語からなるファセットとの相関を分析した図である。水素製造の触媒、貯蔵タンク、および水素ステーションなどと高い相関を示すチタン化合物が存在していることを確認できる。
時系列探索
ターゲットとする技術や素材に関する主要な分析軸(技術名、その技術を利用した主要な部品名、化合物の種類等)を対象に時系列分析を実施し、近年増加傾向にあるものを探索する。
たとえば図表8は、特許におけるチタン化合物が出現する特許数を時系列で見たものである。

折れ線グラフは、当該語が出現する特許数の時系列推移を示す。背景のヒートマップは当該語の当年の区間平均値比が、他の全単語と比較して高いものに強調色を付与している。つまり濃い強調色の年は、“他の単語と比較して増加が顕著なもの”を示している。
近年増加が顕著な化合物は、当該化合物の新たな用途に関する記載があったり、従来用途・サービスに新機能が付与された特許が出現していることを示唆している。
この場合、当該単語・当該年の特許に範囲を限定して図表4に示すような相関分析を実施することで、容易に当該単語・年に特徴的な用途を把握できる。
置き換え用途探索
ターゲットとなる技術や素材が提供する機能特性と相関の高い用途を探索する。
具体的には、ターゲット技術・素材が提供する機能特性語を含む特許から、ターゲット技術・素材が出現する特許を除外した特許を分析対象とし、自社の技術や素材が提供している価値(機能特性)を別の方法で実現している特許を見つけ、自社の技術・素材で置き換えることで、より高付加価値をもたらすことができる特許を探索する。
図表9に、その具体例を示す。
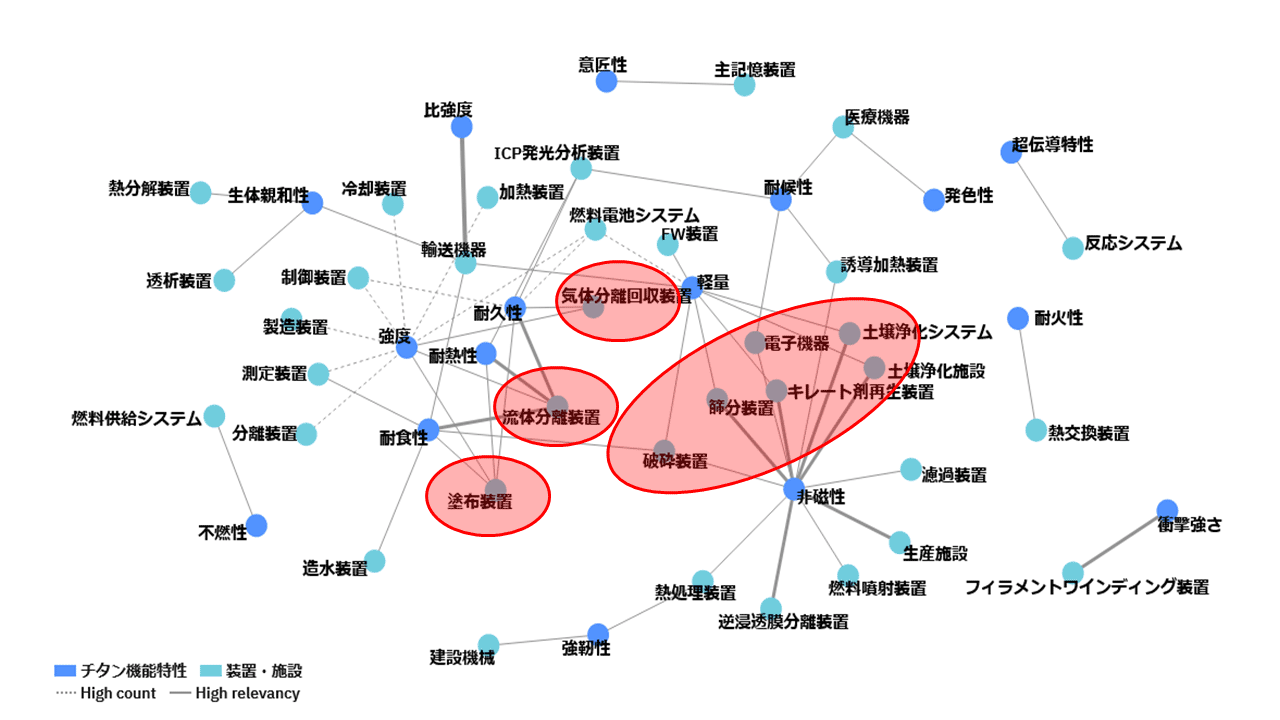
これは「チタン」が出現しない特許を対象に、チタンが持つ機能特性と用語の相関をネットワーク図で示したものである。
チタンが持つ複数の機能特性語と相関を持つ用途、つまりチタンが提供する機能特性をより多く必要としている用途を中心に、置き換えができる特許を探索する。
ここでも、前述した「既知の用途の深掘」に記載したのと同様に、最初は全体の俯瞰から分析を開始し、次に注目すべき領域に絞ってさらに分析を繰り返す。
この手法の欠点として、機能特性の単語だけで絞り込んでも自社技術・素材が実現できる性能にそぐわない用途が多数出現し、探索効率が悪化する場合がある。
たとえば「耐熱性」は、技術領域によって意味する温度帯が200℃であったり、1000℃であったりとまったく異なる。
この場合、テキストマイニングの文字パターン機能を利用して、本文中から温度の表記を抽出し、自社技術・素材が対応できる温度が出現する特許に絞り込んで分析したり、あるいは自社技術・素材が対応可能な範囲の耐熱性試験の規格名で特許を絞り込んで分析したりするなどの工夫で効率性を向上できる。
仮説検証
前述の分析を実施すると、分析者が持つ知識や経験との相乗効果により、分析者はさまざまな用途・サービスの仮説を持つようになる。仮説の例としては、以下がある。
◎自社の素材にある添加剤を配合すれば、さらに機能特性を強化できる可能性があり、適用用途を拡大できる。
◎別素材にて機能特性Aと機能特性Bの2つの機能特性を活用した用途が多数存在する。自社の素材には機能特性Bはないが、添加剤の工夫により比較的簡単に機能特性Bも発現できるはずであり、別素材の置き換えが可能となる。
このような分析者がたてた仮説を確認するため、注目する添加剤、機能特性およびその発現メカニズム(反応名、現象名等)などが出現する特許とファセットを追加して分析し、仮説を検証していく。
動向・市場・リスク調査
次に、見つけた用途の候補の動向を分析し、当該市場の有効性を評価する。
たとえば、ある業界大手の企業が自社技術・素材が提供する機能特性の改善に関する特許を継続的に出願している場合、その企業は自社の技術・素材を採用する可能性があり、一定の市場規模を持つ可能性があることを示している。
複数の企業で当該用途の出現頻度が上昇傾向にあるなら、各社が当該市場に注目していること、成長市場となる可能性があることを示している。これらの情報は、発見した用途の将来性を評価する重要な参考情報となる。
最後に、発見した新規用途の市場に関する詳細な情報(市場規模、市場成長率、サプライチェーン上のリスク等)を把握する必要がある。
近年は大量のニュース(経済新聞、業界新聞、技術専門誌)の記事や市場調査レポート等をテキストマイニングツールで分析し、当該市場の詳細情報を効率的に取得する試みも実施されている。
たとえば、ある電波透過性の高いプラスチック素材が自動車用レーダ・LiDARの保護ケースに適用できることを発見したとする。時系列分析によりADAS(先進運転支援システム)用センサとして自動車用レーダ・LiDARの特許数が増加傾向にあり、当該市場が拡大する可能性のあることがわかる。
さらにニュース記事をテキストマイニングで検索すると、ADAS関連センサの市場予測に関する記事を見つけ、市場規模、市場成長率の予測値等を把握できる。
PESTEL(政治、経済、社会文化、技術、環境、法律)の視点でニュース記事を分析すると、自動車用レーダ・LiDARの保護ケースには電波透過性が優れたコバルト化合物が利用されているが、その主要産出国に地政学リスクがあり、調達が困難になる、あるいは価格が上昇する懸念が年々高くなっていることが把握できる。
図表10はコバルトの主要産出国である“コンゴ民主共和国”と供出するPESTEL関連語の推移を示しており、インフレーション、クーデター、汚職、殺人、軍、干ばつ、暴力などの社会不安に関する単語の供出回数が増加しており、地政学リスクが高まりつつあると推測できる。
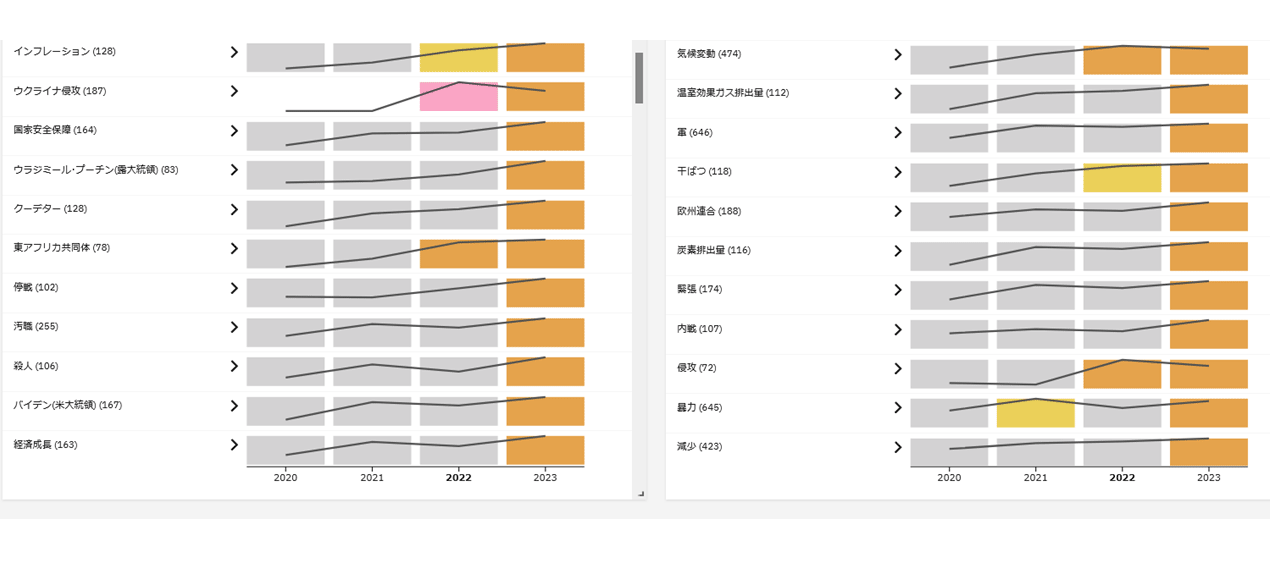
そしてコバルト化合物について再度特許を分析すると、コバルトフリー素材に関する特許が増加傾向にあり、どの企業がどのような用途で“コバルトフリー”に取り組んでいるかも把握でき、コバルト化合物の置き換え需要が望める市場を探索することも可能である。
このように、市場の評価作業にもテキストマイニングを活用することで、従来の手法より効率的に有用な情報を収集できる。
生成AIの活用
近年、生成AIは急速に進歩し、簡単な操作でターゲット技術や素材の用途を調べることが可能になってきた。
生成AIを活用した用途探索の最大の利点はその手軽さで、分析者がプロンプト・エンジニアリングのスキルを習得すれば、簡単に短時間で用途を探索できる。しかしテキストマイニングと比較すると、以下のような課題がある。
生成AIで用途探索を実施する課題
解の範囲
生成AIが回答する内容は、学習したデータに依存する。このため、得られる新規用途の候補が学習した文書の範囲に限定されてしまう。
テキストマイニングと生成AIの双方で用途探索を実施した結果を比較すると、生成AIで得られる用途は一般的で広く知られている用途を網羅できるが、広範囲の特許をテキストマイニングで分析した際に得られるような先端的な用途や粒度の細かい具体的な用途を得られない場合が多い。
生成AIに対して大量の特許をファインチューニングすれば、この問題は解決すると思われるが、ファインチューニングにはコストと膨大な処理時間を要する。たとえば100万件の特許をファインチューニングするコストを試算すると、数億円の費用が発生し、現実的な手法とは言えない。
定量的な分析
テキストマイニングは、供出する単語の時系列推移や相関値をグラフや値で分析者に示す。
増加傾向にある技術や素材を調査した場合、いつから増加しているのか、他の技術や素材と比較してどれだけ増加率が高いのかなどを容易に、かつ定量的に把握できる。このため注目すべき用途の絞り込み等を定量的な値で判断できる。
これに対して多くの生成AIモデルは定量的な値を示せなかったり、値は示すがその値の根拠が不明確であるなど、定量的な判断が難しいという課題がある。
詳細情報の取得
特許分析で用途の候補を得た際、分析者はその候補に関する特許の内容、特に実施例などを読み込んで、自社の技術や素材の適用可能性を評価する。
たとえば、特許に記載されている性能値やその製造方法などを確認し、自社の技術や素材でより高い性能値を実現できる可能性があるのか、あるいはより低いコストで実現できる可能性があるのか、などを評価する。
テキストマイニングで用途探索を実施する場合は、候補となった用途に関する特許、および同特許中でファセットにヒットしたセンテンスをツール上で簡単に確認できるため、この“新規用途の候補発見→確認”のプロセスをシームレスに進めることが可能である。
しかし多くの生成AIモデルでは、特許の実施例に相当する情報を得られなかったり、得られたとしてもその出典があいまいな場合が多く、あらためて特許情報システムで当該特許を探して詳細な情報を確認するという手間が発生する。
また生成AIの回答にはハルシネーションによる誤りを含むため、特許情報を検索しても当該用途に関する記述が見つからない場合も多いといった問題もあり、確認作業にかなりの時間を要する。
そのため、生成AIは新規用途のアイデアを得るというレベルでは実用域にあるが、技術的な裏付けのある用途を探索するにはテキストマイニングのほうが優れていると言える。
生成AIの活用
このように生成AIによる用途探索の課題をテキストマイニングとの比較で説明したが、生成AIとテキストマイニングは二者択一の関係にあるのではなく、双方の長所を活かし組み合わせて活用することで相乗効果を得られる可能性を秘めている。
たとえば初期の用途探索作業は、生成AIにより短時間で実施し、解の候補を洗い出し、テキストマイニングで精緻に分析するといった役割分担をしたり、RAGと呼ばれる手法でテキストマイニングの分析結果を生成AIにコンテキストとして示して、解の精度を向上させるといった方法がある。
また、テキストマイニングで見つけた特許を生成AIで翻訳・要約して分析者の作業負荷を削減したり、生成AIを活用して辞書作成作業を効率化するなどの補助的な活用も考えられる。
成果
IBM Watson Discoveryにより特許からの用途探索を実践した企業の多くが、実際に新規用途を発見しており、その一部はプレスリリースされている(*8、*9、*10)。以下に、実践したユーザーの声を紹介する。
・過去数年にわたり自社主力製品の用途探索をさまざまな手法で実施してきたが、有力な新規用途の候補が見つからなかった。大量の特許をIBM Watson Discoveryで分析することで、有力な新規用途の存在に気付くことができた。
・食品包材用の素材Aが電子部品部材にも使える、建築材料向けの素材Bが衛生用途にも使える、半導体関連用の素材Cが調理設備にも使える、といったように既存素材の新市場・新用途の発見が可能となった。
・従来の方法では新規の用途が見つからず、研究開発テーマは既存顧客からの改善要望が中心となり、将来の拡販につながるテーマを創出できていなかった。テキストマイニングによる分析で新規用途の候補が見つかり、拡販につながる研究開発テーマを多数得ることができた。
・新たな用途の発見とともに、当社の技術・素材を欲している顧客(出願人)も同時に把握でき、「誰に売りに行けばよいか」を高い確度で把握できるため、従来の方法よりも早期に成果を上げられた。
また、用途探索以外にも付帯効果があることも報告されている。
・自社技術とIPCの相関を示すネットワーク図には衝撃を受けた。この図には当社の研究開発テーマの偏りや特許侵害に関する調査範囲に漏れがあることを明確に示している。これからの時代はビッグデータ(大量の特許)を分析するアプローチが必須であることを痛感させられた。
・大量の特許を俯瞰することで、当社が取り組んでいる技術課題について新たな解決方法があることに気づくことができた。同方法は特許として出願し、その利権も確保できた。従来の方法では手間がかかりすぎて実行できなかった大量特許の俯瞰を、簡単に実行できることは非常に有用である。
・重要顧客の特許を分析することで、当該顧客から寄せられた要件の技術的な背景を理解でき、より付加価値の高い提案を実施できるようになった。
・研究開発の過程で発生するさまざまな課題に対する解決方法のアイデアを特許分析で探索できるようになり、課題解決で発生する停滞期間が短くなり、研究開発のスピードを向上できた。
以上が主だったユーザーの声であるが、いずれもAIを活用したテキストマイニングは人が一生かかっても読めない大量のテキストを可視化し、従来のツールでは困難だった新たな洞察が得られることを非常に高く評価している。
IBMはこれまで多くのユーザーにテキストマイニングを活用した用途探索の支援サービスを提供してきた。10種類以上の特許情報サービスの前処理の実績、計約600個・50万語以上のサンプル辞書、分析者へのツールの操作と分析手法のスキトラ教材など、テキストマイニングのプロジェクトを効率的に推進するツール、スキル、ドキュメントを有している。
あるユーザーからは、「我々がオープンソースのテキストマイニングで半年かけてできなかったことを、IBMのコンサルティングサービスを利用すると2週間で分析できた」との高い評価を得ている。テキストマイニングにチャレンジする際には、ぜひIBMのコンサルティングサービスの活用を検討いただければ幸いである。
<参考資料>
*1 経済産業省 2023 令和4年度製造基盤技術実態等調査 我が国ものづくり産業の課題と対応の方向性に関する調査
*2 日本能率協会 2020 CTO Survey 2020 『日本企業の研究・開発の取り組みに関する調査』報告書
*3 太田貴久ら 2018 『特許文書を対象とした因果関係抽出に基づく発明の新規用途探索 人工知能学会全国大会論文集』 2L1-03
*4 高石静代ら 2018 『段階的発想法による用途探索 情報の科学と技術』 68 (4), 180-185
*5 菰田文男、那須川哲也 2014 『技術戦略としてのテキストマイニング』中央経済社
*6 那須川哲也 2018 『テキストアナリティクスの動向と特許情報処理』 Jaoio YEAR BOOK 2017
*7 豊田裕貴、菰田文男 2011 『特許情報のテキストマイニング』 ミネルヴァ書房
*8 三井化学 プレスリリース 2022 「三井化学、IBM Watsonによる新規用途探索の全社実用をスタート ビッグデータとAIの活用で営業DXを推進」
*9 三井化学 プレスリリース 2023 「三井化学、生成AIとIBM Watsonの融合による新規用途探索の高精度化と高速化の実用検証スタート」
*10 日本ゼオン プレスリリース 2021 「日本ゼオン、AI を活用した『技術動向予兆分析システム』の稼働を開始」