リコーは8月21日、製造業で重視される日本語・英語・中国語に対応した700億パラメータの大規模言語モデル(LLM)を開発した、と発表した。オンプレミスまたはクラウドのいずれへも導入可能で、導入企業のクローズドな環境下で機密情報を含めた追加学習が可能。代表的なLLMと比較して高いベンチマーク性能を示したという。2024年秋から国内企業向けに提供を開始し、その後海外の企業へ提供する。
今回リコーが開発したLLMは、米Meta社の「Meta Llama 3 70B」の日本語性能を向上させた「Llama 3 Swallow 70B」をベースモデルに採用し、日本語、英語、中国語のオープンコーパスを追加学習させたもの。
入力された文章をトークン(単語、文字セット、単語と句読点の組み合わせなど)に分割しLLMが理解できる形に変換するトークナイザーの独自改良により、日本語の処理効率を43%向上させた(ベースモデル「Llama 3 Swallow 70B」との比較)。これにより、リソース削減、レスポンス時間の短縮、省コスト、省エネルギーを実現したという。
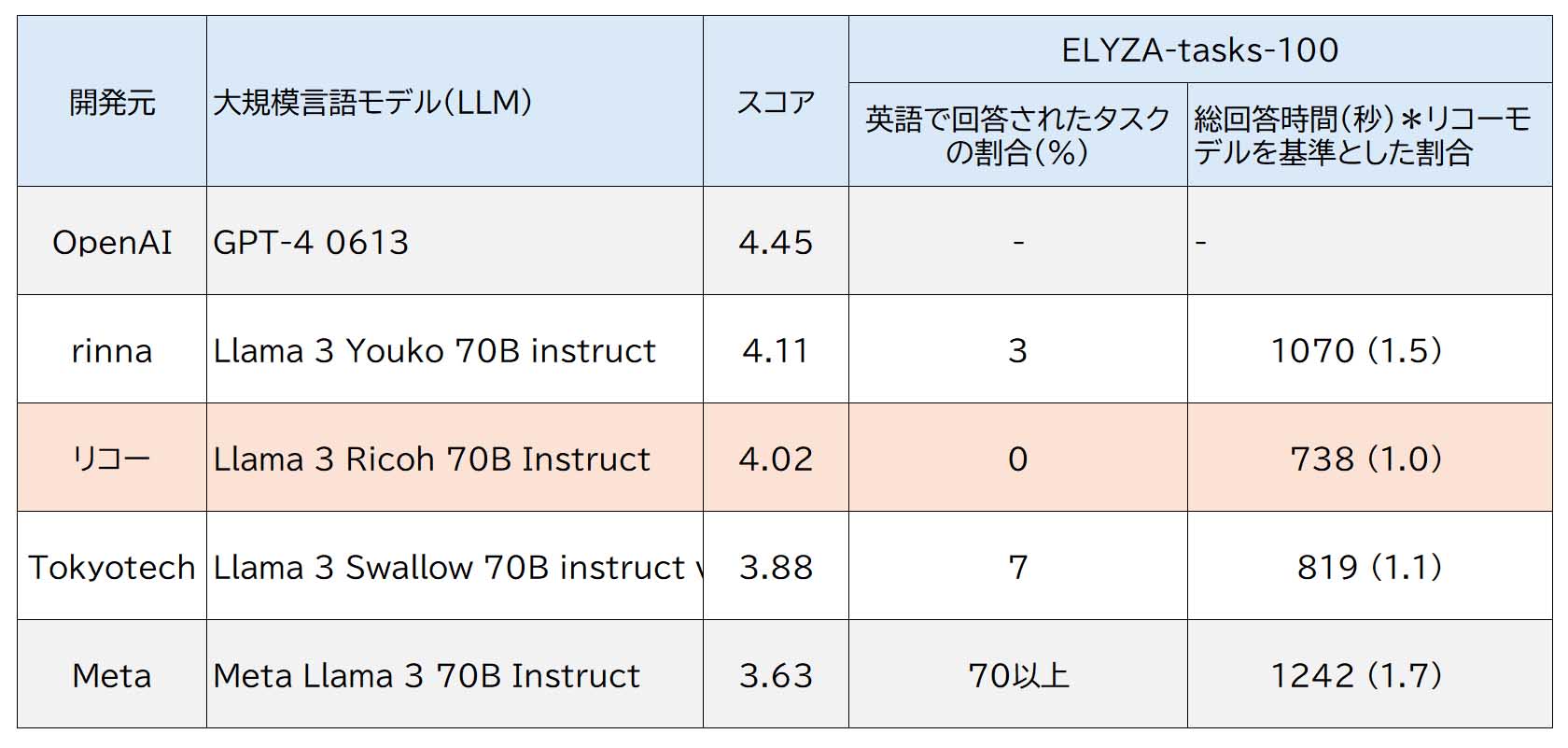
LLMを評価する日本語ベンチマーク「ELYZA-tasks-100」による評価結果は以下のとおり。リコーが開発した「Llama 3 Ricoh 70B Instruct」は平均スコアで4を超え、すべてのタスクに対して日本語で回答し高い安定性を示した。
リコーでは今回開発したLLMのユースケースとして以下を挙げている。
●社内でも厳しいアクセス制御が求められる機密情報を取り扱う業務
・金融業:融資審査業務等
・自治体:行政サービス等
・流通・小売業:顧客情報分析やマーケティング等
・教育・医療:長時間労働が課題となっている教員や医師の文章作成等の周辺業務等
● 日本語・英語・中国語で日々更新される社内文書のデータを利活用する業務
・製造業:RAGを活用した社内情報の検索や要約等
リコーは2024年に入ってから、生成AIを活用した自社業務の高度化(機器の保守・サポート、社内SFA/CRMシステムの刷新)やナレッジ活用サービスの提供(RICOH デジタルバディ、RICOH Chatbot Serviceデジタルバディなど)を活発に推進している。
[i Magazine・IS magazine]