すると、見事に表形式で結果を返してくれた(図表1)。オブジェクト指向プログラミングの説明は、「ILE RPG自体は直接的なサポートはありませんが」と、その前で訂正された情報が加味されて回答されている。Chatのやり取りを基に、GPTからの回答がより洗練されていることがおわかりだろう。

ChatGPTにアクセスする際、会話のキャッチボールの中で条件を徐々に狭めていく方法が大事であるとはよく言われるが、事前に前提条件をまとめて与え、それに基づいて文章を生成してもらうという方法もある。前提条件の与え方については、プロンプト・エンジニアリング・スキルが必要になってくるが、より具体的な質問方法はネットで公開されているので、それらを参考にしながら、RPG開発にどこまでChatGPTが使用できるのかを試してみたいと思う。
なお、GPTの学習データは2021年9月までの情報なので、これ以降の出来事などについては基本的に持っていないことを理解したうえで利用する必要がある点には注意しておきたい。
データベースの作成
では、簡単な部品展開ロジックのサンプル・コードをFF RPGで作成するという課題に取り組んでみたい。順番として、最初にサンプルで使用するデータベースの作成を行い、次に実際のロジック・コードの作成をChatGPTと一緒に進めていくことにする。
IBM iのデータベース作成方法といえばDDS + CRTPFを思い浮かべる方が多いと思うが、今回は作成もデータ追加もSQLを利用することにする。まずは条件を指定して、部品マスター・テーブルBOMを作成するDDLを提案してくれるようChatGPTと会話してみよう。
指定する条件は次の3つとする。
- 2つのフィールド(ParentCodeとChildCode)を定義
- キーは2つのフィールドの複合キー
- レコード様式名はBOMR
以下のSQL文は、フィールド’ParentCode’と’ChildCode’を持つテーブル’BOM’を作成し、これらのフィールドを複合キーとして設定します。Db2 for iでは、テーブルを作成する際に、’FOR SYSTEM NAME’句を使用してシステム名(レコード様式名)を設定します。
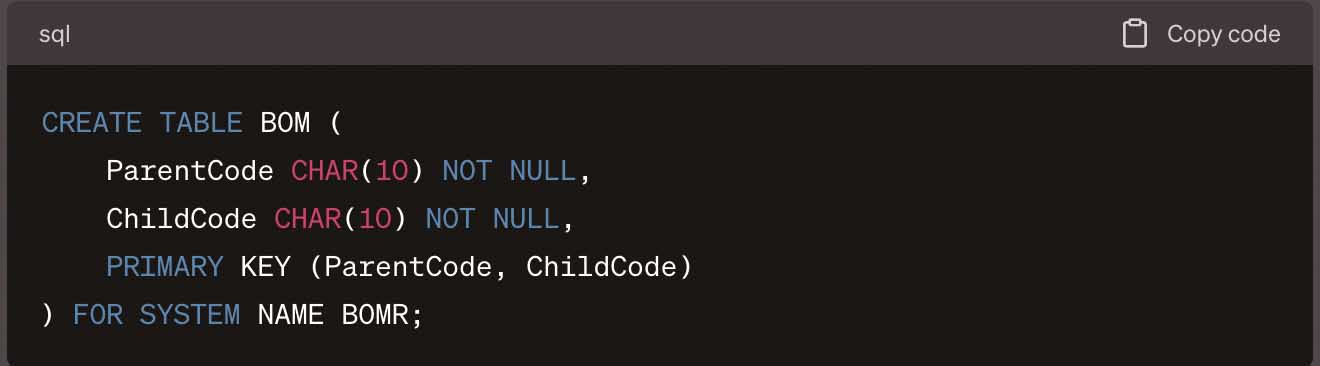
上記のスクリプトは、’ParentCode’と’ChildCode’フィールドがともに10桁の文字列であり、その組み合わせが一意であることを保証します。また、テーブルのレコード様式名(システム名)として’BOMR’を設定しています。
ただし、Db2 for iのバージョンや具体的な設定によっては、このSQL文が正確に動作するどうかは異なる場合があります。具体的な状況に応じて、SQL文の調整が必要かもしれません。
すみません。Db2 for iのシステム名(レコード様式名)の指定方法に誤りがありました。システム名はテーブル名として指定するのではなくテーブル作成後に’RENAME TABLE’コマンドを使用して設定します。
以下がDb2 for iでのテーブル作成とシステム名の設定を行うSQL文の例です;
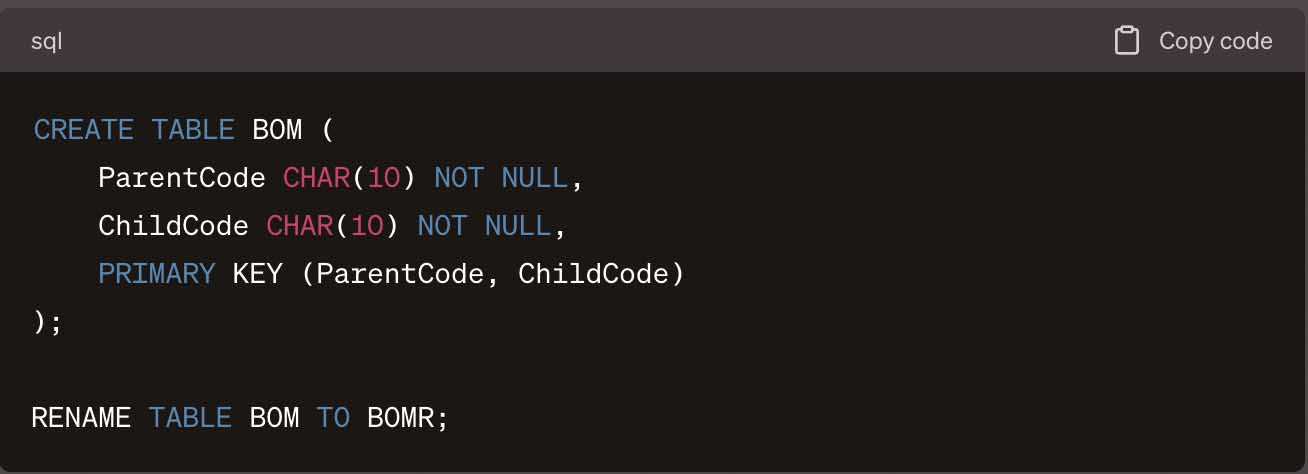
ただし、注意点として’RENAME TABLE’コマンドは元のテーブル名を新しい名前に変更します。つまり、この操作後、テーブルに対する参照は新しい名前(ここではBOMR)を使用する必要があります。
なお、テーブル作成と名前の変更を一連の操作として行う場合は、各SQL文をそれぞれ実行するか、またはDb2 for iが複数のSQL文の一括実行を許可するように設定されている場合は一緒に実行することが可能です。具体的な実行方法はDb2 for iの設定や使用しているインターフェースによります。
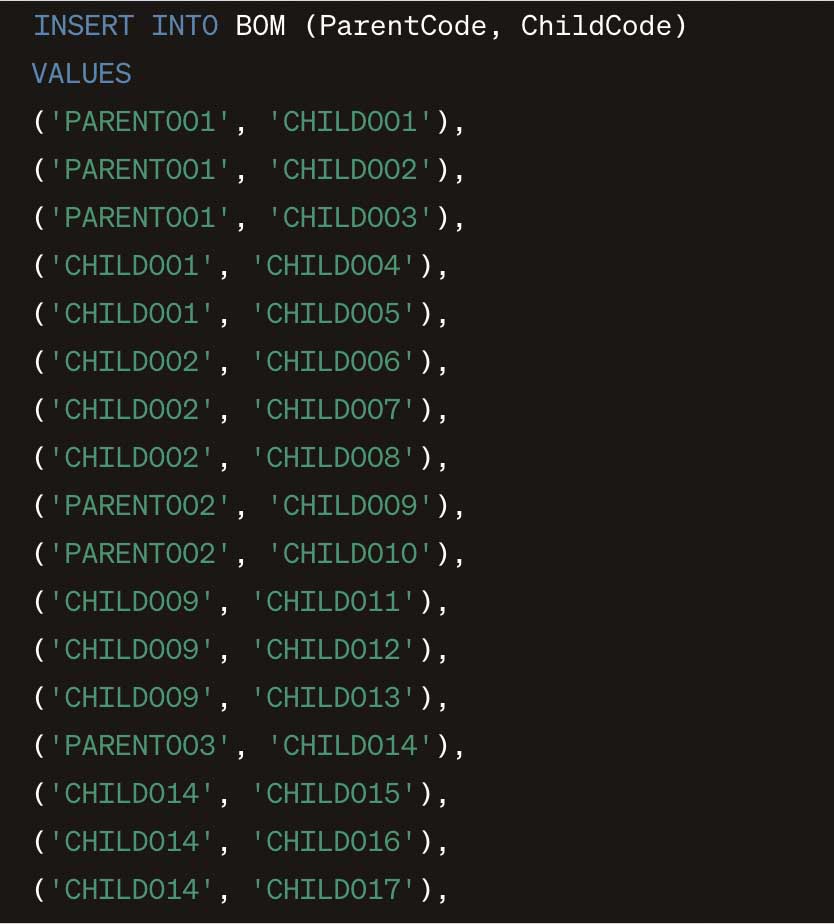
ご指定に基づいて、一部のChildCodeが他のレコードのParentCodeとなる1対多の関係を持つサンプルデータを作成しました。以下にそのようなデータを登録するSQL文を示します;
ILE RPGを使用して部品展開ロジックを作成するには、次のように実装することが可能です。この例では、部品の情報をDBから取得し、展開レベルは変数によって制御されます。以下にRPGの基本的なコードスニペットを示します。
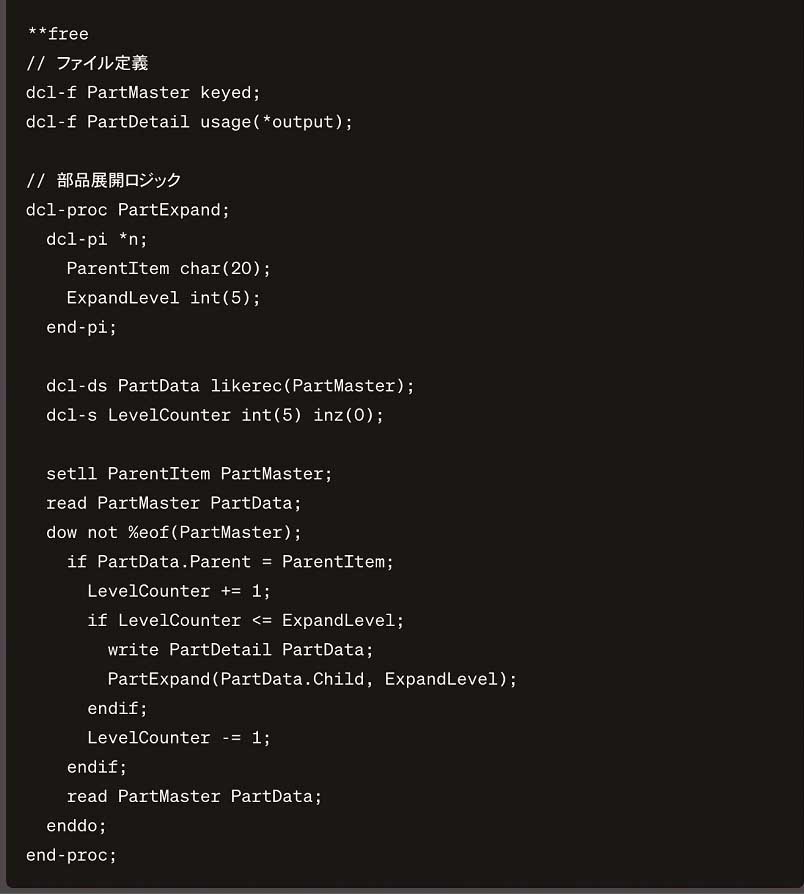
このコードはRPGのプロシージャコードの一部であり、フリーフォームRPGで書かれています。
・ファイル’PartMaster’は部品マスターを参照し、部品情報を取得します。
・ファイル’PartDetail’は展開された部品情報を出力します。
この’PartExpand’プロシージャは親部品と展開レベルをパラメータとして受け取り、展開レベルに達するまで、または全ての部品が展開されるまで部品情報を読み込み、子部品に対して再帰的にこのプロシージャを呼び出します。
部品マスター(’PartMaster’)には親部品(’Parent’)
と子部品(’Child’)の情報が存在し、部品間の関係性を管理していることを想定しています。
注意:上記のコードは、部品マスター(’PartMaster’)と部品詳細(’PartDetail’)のレコードフォーマット、そして部品マスターのキーが適切に定義されていることを前提としています。このコードは一例であり、実際のシステムや要件によって調整が必要となる場合があります。
これに対しては、「以下に、上記サンプル・コードの注意点を表形式でまとめます。」という回答があり、図表2が示された。
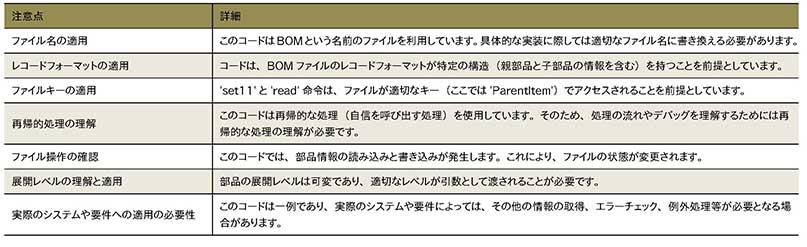
注意点7つをわかりやすくまとめてくれた。データベースのキーに注意すること、再帰的処理を理解すること、エラーチェックなどを必ず実装することなど、重要な指摘があることがわかる。
提示されたコードと注意点を踏まえ、今回は結果をデータベースに出力するのではなく、dsply命令でジョブログに書き出すように修正したプログラムが以下である。
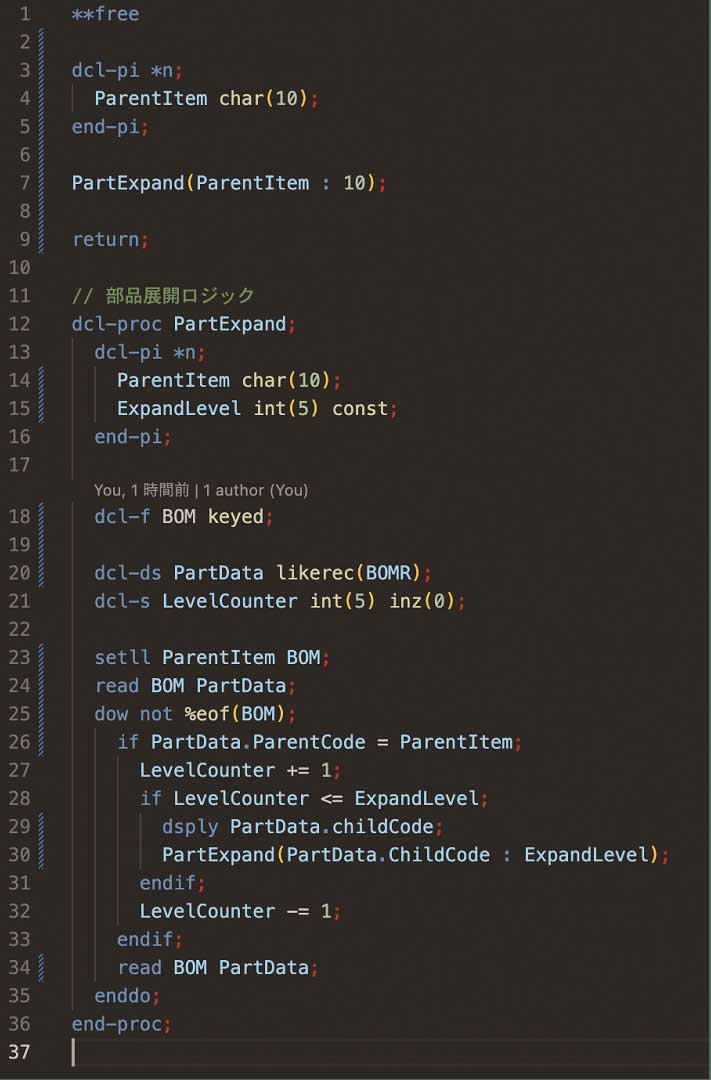
データベースのキー項目の属性に合わせて桁数を変更したり、再帰呼出しロジックを完成させるために、ファイル定義をPartExpandプロシージャ内に移動(ローカル定義)したりという修正は行っているが、基本的な構造はChatGPTが提示したサンプルに沿っていることがおわかりいただけると思う。
上記コードで BOM01という名称のプログラムを作成し、実際に実行した結果は以下の通り。
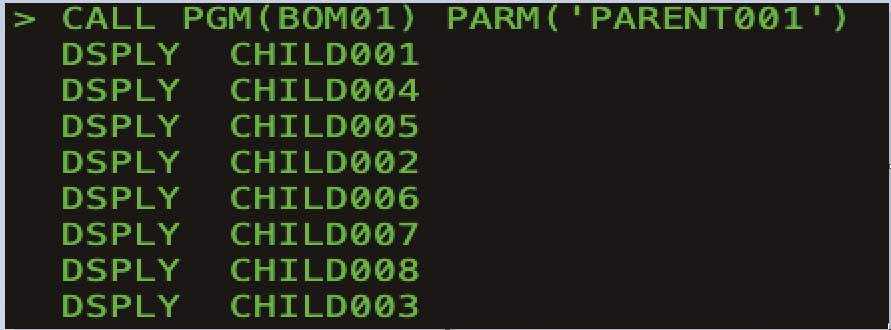
パラメータに親部品コードを指定すると、先程作成したテーブルBOMから親部品PARENT001 を構成する小部品を順番に検索して表示した。
このプログラムはあくまでもサンプルなので、このままのコードを基幹システムに組み込むことはしない。だが、ChatGPTとチャットしながら進めることで、FF RPGのサブ・プロシージャの再帰呼び出しが部品展開の基本的なロジックには有効なこと、テストデータなども工夫しだいで一括作成できることなどが理解できた。工夫しだいでは、RPG開発でもChatGPTを有効活用できることがおわかりいただけたのではないかと思う。
まとめ
IBM iのRPG開発において、具体的にChatGPTにどのように指示をし、どのような結果が返ってきたかを、実際のイメージを使って解説してきた。皆さんが記事タイトルの「ChatGPTはRPG開発にどこまで使えるか」から想像した内容にどこまで近づけたかは心もとない部分もあるが、少なからずRPG開発にChatGPTを利用するヒントは提示できたのではないかと思う。
繰り返しになるが、GPTは生成AIなので、何か質問するたびに「計算」が行われその結果を返す。そのため、記事に記載したのと同じ質問をChatGPTに与えても、同じ答えは返ってこないことに注意していただきたいと思う。
RPG開発者が現時点でChatGPTを利用する利点は、プログラマーの仕事を「サポートする」という点にあると思う。何も知らなくても正解を教えてくれる魔法のツールではなく、プログラミングをしていく過程でのアイデア出しや、ヒントをくれるツールという位置づけだ。
仕事のできる同僚や先輩に対して、「この仕様をフリーフォームRPGで作ってください。しかもバグなく。」なんて聞くプログラマーはいない。「このロジックはこう書こうと思っているんですけど、方向性はあっていますかね?」とか、「こういうことってRPGでできると思います?」という質問をすることで、「大丈夫だと思うよ」とか、「詳しくはわからないけれど、こういうことは可能かも」と回答をしてくれる。そんなバーチャルな同僚や先輩というのがChatGPTの現時点での私の印象だ。
最後に、ChatGPTを利用するにあたって気をつけておくべきことをお伝えする。それは、GPTの学習元のデータと、そのデータのプライバシーや著作権の問題だ。ChatGPTに使用上の規約を聞いてみると、以下の答えが返ってきた。