Text=松本 昇平、徳竹 康成、門野 琢哉 日本アイ・ビー・エム システムズ・エンジニアリング
<前編を読む>
ストリーム処理基盤としてのKafka
後編では、アプリケーションやKafka ConnectでKafkaに集約したレコードを活用するストリーム処理や、ストリーム処理プラットフォームであるKafka Streams/ksqlDBについて詳しく見ていく。
バッチ処理とストリーム処理
ストリーム処理の前に、データの処理形態として馴染み深いバッチ処理について簡単におさらいしてみよう。
バッチ処理は日次や週次、月次など、一定期間のデータの集合を1つの処理単位として、スケジュールされたタイミングで処理する。バッチ処理ではその特性上、処理結果を得るまでにタイムラグがあり、処理が行われていない時間は、リソースを使用しない状態となる。
これに対してストリーム処理は、データを受け取ると同時に処理が行われる。そのため、バッチ処理で起こる結果取得までのタイムラグや、リソースの有効活用という点でメリットがある。
ストリーム処理について、もう少し深く理解していこう。ストリーム処理には大別して、以下の2つの処理形態がある。
ステートレス処理
ステートレス処理では、1つのイベントだけを参照して処理を実行する。たとえば、サニタイズやマスキング処理といった比較的簡単なデータ加工が挙げられる。
またシステムログを収集しているイベントでは、ログにwarningやerrorといった文字列を含むことが往々にしてあるが、そういった特定の文字列を含むイベントだけを抽出するようなフィルタリング処理も、ステートレス処理の1つである。
ステートフル処理
ステートフル処理は、関連する複数のイベントを参照して処理を行う処理形態を指す。たとえば数分間、数時間といった決まった時間内で、イベントの持つ数値の平均や最大/最小値を集計するようなデータの集計処理である。
またレコードそのものに意味を持つイベントでの処理として、一定の時間に発生したイベント件数を集計する処理がある。これは特定のIPアドレスからのDDos攻撃や、不正なログイン処理を検知するために活用できる。
ステートフル処理では複数のイベントを扱うので、それらの集計結果などを保持するための何らかのデータストアが必要になる。一般的にはメモリ上や、何らかのKey-Value Store (KVS)に保持・参照する。
ストリーム処理のプラットフォームとしてKafkaを利用することで、アプリケーションやConnectorを通じて集約したデータは、そのまま別のサービスに連携することも、ストリーム処理を挟んだ上で連携することも可能である。
Kafkaを介してデータを連携する強みは、ソースとなるデータを利用先ごとに用意する必要がなく、同一ソースを複数の利用先が利用できる点にある。
ストリーム処理の実装には、Apache Spark、Apache Storm、Apache Flinkに代表されるようなOSSのストリーム処理エンジンや、Amazon Kinesis、Google Cloud Dataflowといった、各クラウドベンダーが提供するSaaSなど、さまざまな選択肢がある。
Kafkaのコミュニティではストリーム処理のためのコンポーネントとしてKafka Streamsを、Confluent社からはksqlDBを提供している。
Kafka Streams
Kafka Streamsは、ストリーム処理のためのライブラリである。KafkaのProducer/Consumerのクライアントアプリケーションを実装するのと同様に、このライブラリを用いてストリーム処理を実装、ビルド、デプロイすればよいので、ストリーム処理を実現するまでの敷居は低い。
またストリーム処理では、扱うイベントの量が膨大になるため、並列分散処理を行うことが多い。Kafka Streamsを使ったアプリケーションの分散処理で必要な機能は、Kafkaクライアント・ライブラリのレベルで実現しており、Consume時のPartitionのアサインや障害時の再アサインは、通常のKafkaクライアントと同様、Consumer Group内のGroup Leaderによって行われる(図表15)。
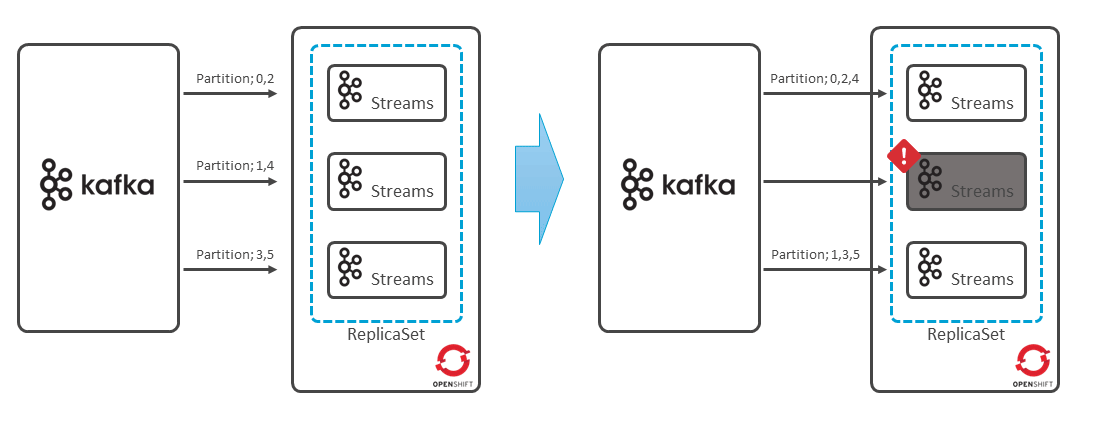
各Partitionのどのレコードまでの処理を終えたかは、レコードのOffset Commitの仕組みで管理されるため、再アサインが行われても続きから処理を行える。
前述のとおり、ストリーム処理におけるステートフル処理では、処理結果を保持するためのデータストアが必要になる。KafkaではrocksDBと呼ばれるインメモリKVSで管理する。
rocksDBのチェンジログそのものもKafkaのレコードとして保持するため、アプリケーションの再起動を挟んでも、そのログを読み込むことでKVSのリストアを実行することが可能である。
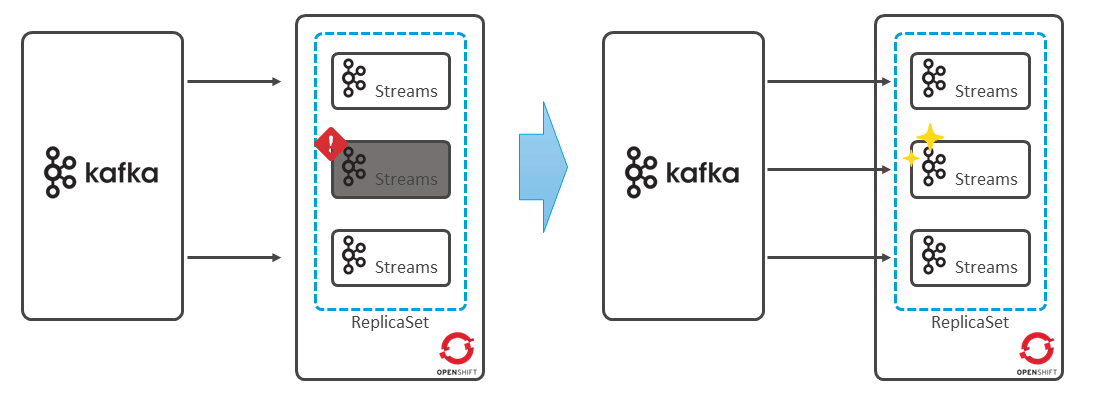
Kafka Streamsで実装されるアプリケーションは、単なるJavaアプリケーションである。つまりアプリケーション・インスタンスの障害検知や復旧については、プロセス監視とオペレーションによる対応や、Kubernetes/OpenShiftを利用して、アプリケーションPodのセルフヒーリングによる復旧といった考慮が必要になる(図表16)。
KsqlDB
ksqlDBは、Confluent社が開発したストリーム処理エンジンである。ストリーム処理をSQLライクなクエリー構文で実装できる。
ksqlDBはクエリーを解析し、ストリーム処理アプリケーションに変換・実行する。ストリーム処理アプリケーションはksqlDBサーバー上で実行され、アプリケーションの可用性はksqlDBで担保される。またksqlDBサーバーをクラスタ化することで、ksqlDB自体の耐障害性も確保できる。
ksqlDBとKafka Streamsはいずれも、Kafkaでストリーム処理を実現するためのコンポーネントであるが、これらはまったく異なる技術から生まれたわけではない。
ksqlDBはKafka Streamsを抽象化しており、Kafka Streamsもまた、Producer/ConsumerといったKafkaクライアントを抽象化したものである。
そのため、基本的にどちらを利用しても実現できるストリーム処理に大きな差はない。SQLに馴染みのある開発者が多いケースでは、ksqlDBのほうが使いやすさで優位に働くが、実行したい処理の柔軟性はKafka Streamsのほうが高い。どちらを採用するかの判断基準の1つとして考えるとよいだろう。
データベースとして見るksqlDBとKafka Streams
“ksqlDB is a database that’s purpose-built for stream processing application.”
これは、ksqlDBの公式ドキュメントに記載されている一文である。以下に、ストリーム処理専用のデータベースとは何を意味するのについて、深堀りしていく。
ksqlDB(Kafka Streams)では、Topic上の同一のレコードをStream(Kstream)とTable(Ktable)という2つの形で表現できる。
Streamは、レコードをそのままイベント・ストリームとして扱うのでイメージしやすい。
一方、Tableでは、Topic上の各レコードをTableに対する変更ログとして捉える。レコードを読み込み、Tableに対して変更を適用することで、最新の状態に保つ。レコードのKeyをデータベースの主キーのように扱うことで、それぞれのレコードの変更対象の行を識別する。
ksqlDBやKafka Streamsでは、イベントの特性や表現したいデータによって、StreamとTableを使い分けてストリーム処理を実現する。
ここでは1つの例を挙げて、StreamとTableを使ったストリーム処理を行ってみる(図表17)。
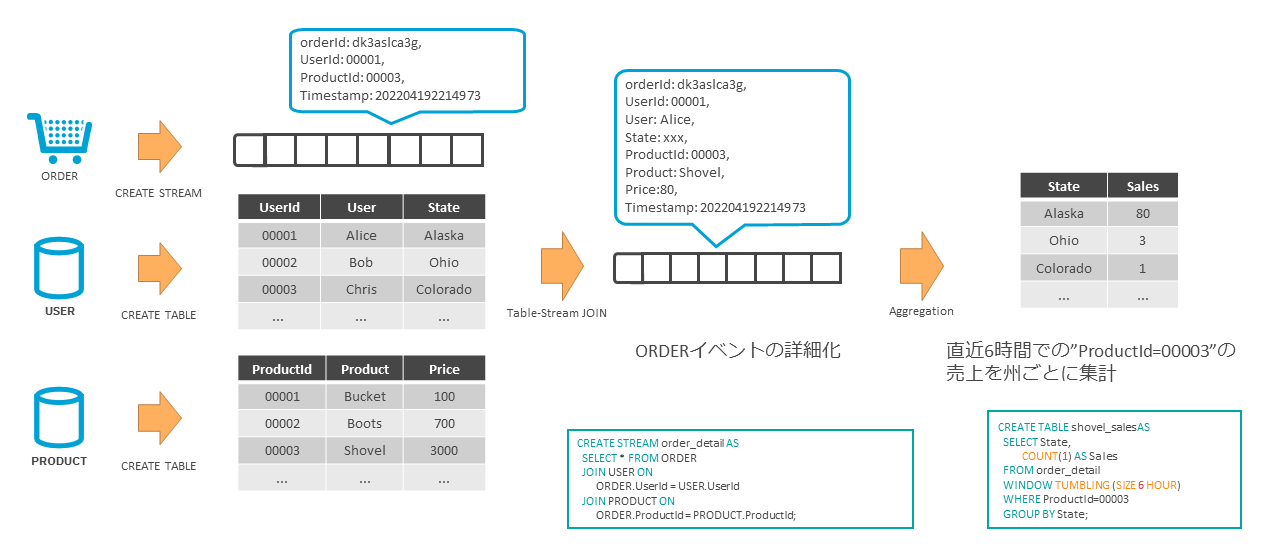
あるECサイトの注文サービス(ORDER)は、注文情報をイベントとしてKafkaに送信している。また、ユーザー情報(USER)と商品情報(PRODUCT)を持つデータベースを、Kafka Connectを使ってKafkaにレプリケーションしている。
ここで、それぞれの注文イベントを詳細化するksqlDBを用いてストリーム処理を行う。注文イベントはそれぞれ個々のイベントとして扱うため、Streamとして扱う。
ユーザー情報や商品情報は、それぞれの最新の状態だけを保持していればよいので、Tableとして扱うことにする。
StreamとTableはJOINできる。元々の注文イベントが持つユーザーIDや商品IDをキーにして、それぞれのTableとJOINする。このような処理も、SQLライクな構文で容易に実行できる。
さらに、この詳細化された注文情報を使って集計処理を行う。6時間のウインドウを設け、各製品の売上数を注文者の住所ごとに集計する。外部のサービスから天候情報を入手したり、Twitterのトレンドを活用するなど、多種多様な情報を組み合わせることで、企業活動での新たな知見を得られる。
このようにストリームだけでなく、Tableとしての表現も併せ持ち、あたかもデータベースのようにレコード間のJOINにより豊かに表現できる。
また、Tableはマテリアライズ化することで、SELECTによるレコードを取得できる。このようにストリーム処理エンジンでありながら、あたかもデータベースであるかのような使い方ができる。
Kafkaでは、Topicに書き込まれたレコードは、ConsumerやKafka Streams/ksqlDBによる読み込み処理によって消えることはない。
しかし、レコードは無尽蔵に保存され続けるわけではなく、基本的には時間経過あるいはレコードの総量によって有効期限が設定されている。
Kafka StreamsやksqlDBでTableの概念を紹介したが、レコードが削除されてしまってはTableを正しく保持できない。最新のテーブルの状態を維持するには、すべてのレコード(≒Tableに対するすべての変更ログ)か、少なくともすべてのキーにおける最新のレコードを保持しておく必要がある。
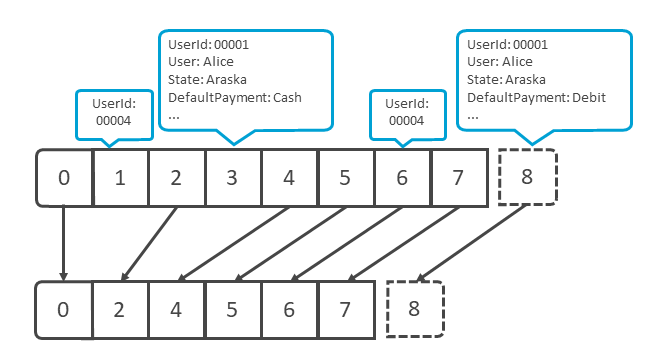
KafkaのLog Compactionを利用することで、レコードの削除のトリガーを時間やストレージの上限ではなく、同一キーを持つレコードの重複で判断する。
Log Compactionでは、同一のキーを持つレコードのうち、最新以外のレコードを削除することで、それぞれのキーを持つレコードの最新の状態を保持しつつ、ストレージの使用量を抑えられる(図表18)。
また最近では、Kafka Tired Storageを利用して、通常はKafkaのローカルディスクに保存されるレコードの中から、古いレコードをAmazon S3などのオブジェクトストレージやHadoop HDFSといった分散ストレージにオフロードすることで、ローカルディスクの使用量を抑えつつ、より長期にレコードを保持する仕組みを提供している。
Kafkaを利用したアーキテクチャ・パターン
多様な機能を兼ね備えたKafkaは、イベントを中心にしたアプリケーション・アーキテクチャにも適用できる。
イベント・ソーシング
イベント・ソーシングとは、アプリケーションが扱う事象(イベント)を中心にした設計パターンであり、ステート・ソーシングの対立概念である。
受注した商品の配送状況を管理するアプリケーションを例に、ステート・ソーシングとイベント・ソーシングという2つの設計パターンを比較してみよう。
まずステート・ソーシングでは、アプリケーションは配送状況のステータスを管理(永続化)する。注文ごとに配送状況を保管するレコードを用意し、配送状況が変わるたびに、そのレコードを更新していく。一般的な方法ではあるが、この方法では更新された古い情報は残らず、履歴は失われる。
一方、イベント・ソーシングでは、ステータスは管理せず、配送状況が変化したというイベントだけを管理(永続化)する。配送状況が変化するたびに、その情報を記したレコードをテーブルにInsertしていく。ステータスは管理しないが、一連のイベントを再生すれば、任意の時点でのステータスを導出できる。
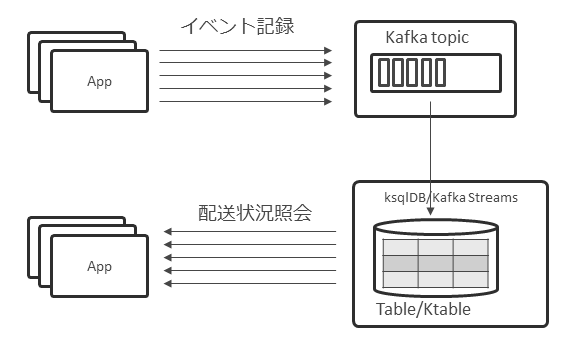
このイベント・ソーシングは、Kafkaとの相性がよい。KafkaのTopicは追記型であり、永続化もできるため、イベントの保管先として利用できる。さらにそのTopicに対してKsqlDB /Kafka StreamsのTable/Ktableを利用することで、常にステータスを最新に保つこともできる。イベントはTopicに格納しつつ、ステータスの問い合わせはTable/Ktableを参照させられる(図表19)。
CQRS
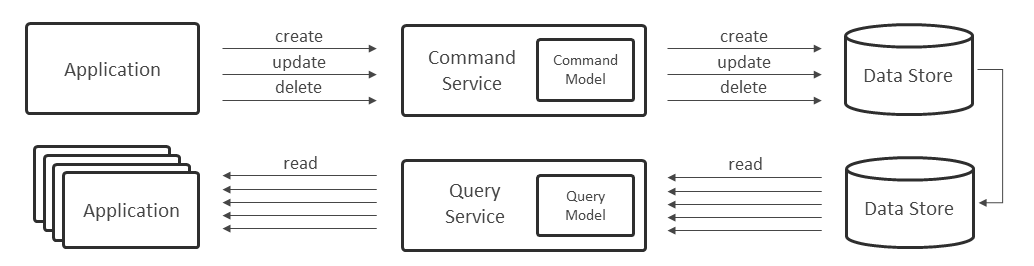
CQRS(Command Query Responsibility Segregation:コマンド・クエリー責務分離)とは、CommandとQueryで異なるモデルを使用し、更新処理と参照処理を分離する設計パターンである。
一般的なCRUD操作を行うアプリケーションでは、1つのデータモデル、1つのデータストアを利用して実装する(図表20)。

一方、CQRSでは更新処理と参照処理で異なるデータモデルを利用する。さらに、データストアやサービスも分離することで、それぞれの処理に最適化したシステムを実装できる(図表21)。
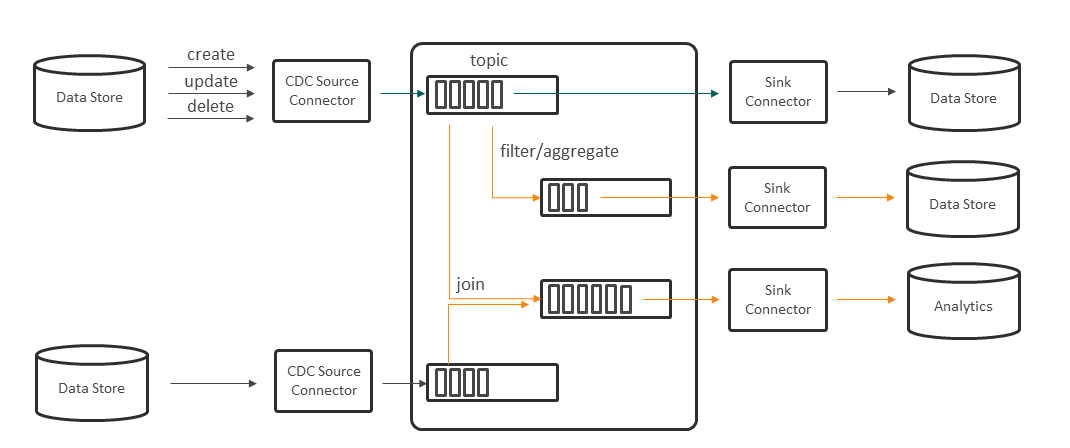
ここで更新用データストアから参照用データストアを用意する場合に、Kafkaを適用できる(図表22)。

KafkaおよびConnectorを利用することで、SourceのデータストアからTargetのデータストアへ、リアルタイムにデータ連携できる。
さらにステート管理のデータストアからCDC(Change Data Capture) Connectorを利用してイベントを捕捉することで、Kafka上にはイベントデータのリアルタイムなパイプラインが構成される。そのパイプラインを分析基盤に連携して新たな洞察を得たり、ストリーム処理を施して他システムに連携することも可能になる(図表23)。
イベント駆動型アーキテクチャ
イベント駆動型アーキテクチャとは、ビジネスイベントをベースにサービスを連携するマイクロサービスのアーキテクチャであり、リクエスト駆動型アーキテクチャの対立概念である。
リクエスト駆動型アーキテクチャでは、要求元からサービスプロバイダーに対してリクエストを投げることで業務処理が実行される。当然、要求元はサービスプロバイダーを認識する必要があり、リクエストに対するレスポンスを待って、次の処理に移る必要がある(図表24)。
一方、イベント駆動型アーキテクチャでは、要求元は自身の処理が完了後、イベントをパイプラインに流すだけでよい。後段のサービスプロバイダーが、イベントをトリガーに業務処理を実行する。サービス間が疎結合となり、マイクロサービスのコンセプトとの相性もよい。
もちろん疎結合になることでトランザクションも分離されるため、処理取り消しのためのコンペンセーション処理も組み込んでおくなど、考慮すべき点もある(図表25)。
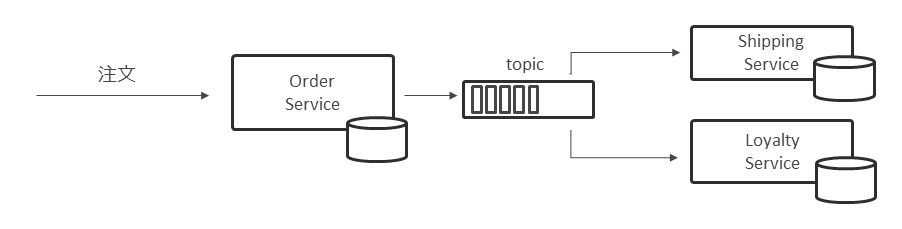
ビジネスフローのパイプラインをKafkaに集約することで、CQRSでも言及したようにさまざまなパイプラインを結合したり、ストリーム処理を加えて新たなパイプラインを派生させたりと、データ活用の幅が広がり、柔軟性と拡張性を備えた基盤を実現できる。
以上、Kafkaが紡ぐイベント・ストリーミングの世界と題して、イベント駆動型アーキテクチャやCQRSといった、イベント中心のアプリケーションやアーキテクチャ、それを支える企業データの集約・配信のバックボーンとしてのKafka Connect、Kafka上の膨大なイベントの活用としてのKafka Streams/ksqlDBを利用したストリーム処理について紹介した。
本稿が、Kafkaを活用したデータ連携基盤やイベント駆動型アーキテクチャ実現の参考になれば幸いである。