Text=横山 夏実氏 日本アイ・ビー・エム システムズ・エンジニアリング
ここ数年、マイクロサービス・アーキテクチャ、Kubernetesプラットフォーム、コンテナと言った技術が注目され、これらの技術を採用する案件が増えている。
実際にシステム構築に取り組む中では、「運用はどう考えたらよいのか」「SREというキーワードは知っているが、具体的に既存の運用をどのように変えていくべきか」「SREの本などに書かれているようなGoogleでの実践例を自分たちの組織でも実践できるのか」といった悩みを耳にする機会も多い。
本稿では、そういった悩みに対して、筆者自身が経験した中で参考にした情報を共有したい。初心者が取り組む際のヒントになれば幸いである。
クラウドネイティブな運用とは
まず、本稿で前提とする「クラウドネイティブな運用」の定義について確認したい。
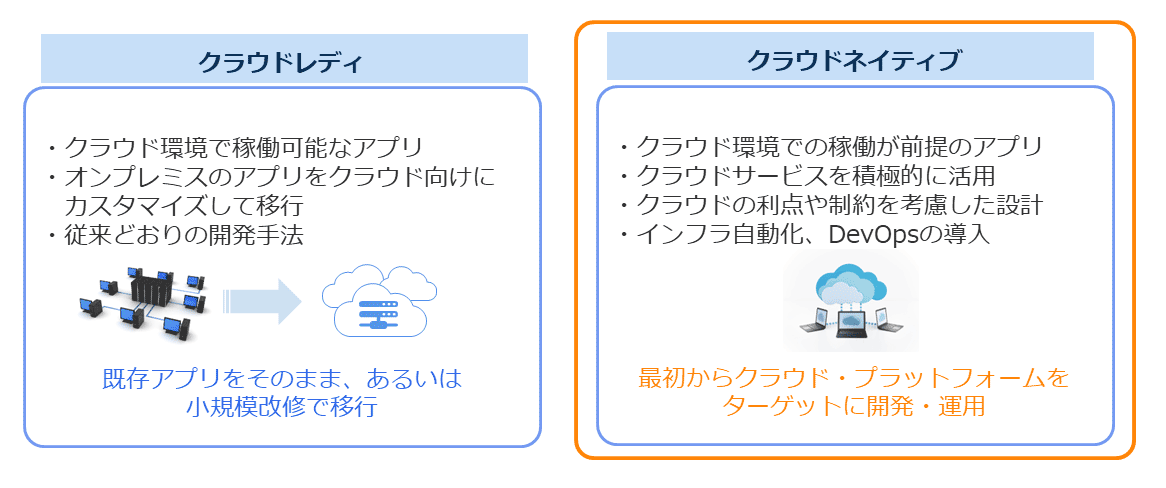
クラウド・プラットフォーム向けのアプリケーション開発には、大きく2つの考え方がある。
◎クラウドレディ
◎クラウドネイティブ
クラウドネイティブとは、「クラウドに最適化された」テクノロジーやプラクティスといった手法そのもの、もしくはこれらの手法を使って開発・運用されるアプリケーションやシステムと言い換えられる。
では、この「クラウドに最適化された手法」は、どのような背景から生まれてきたのだろうか。
先ほど挙げたようなテクノロジーの多くは、Cloud Native Computing Foundation(以下、CNCF)が立ち上げたプロジェクトから生まれている。
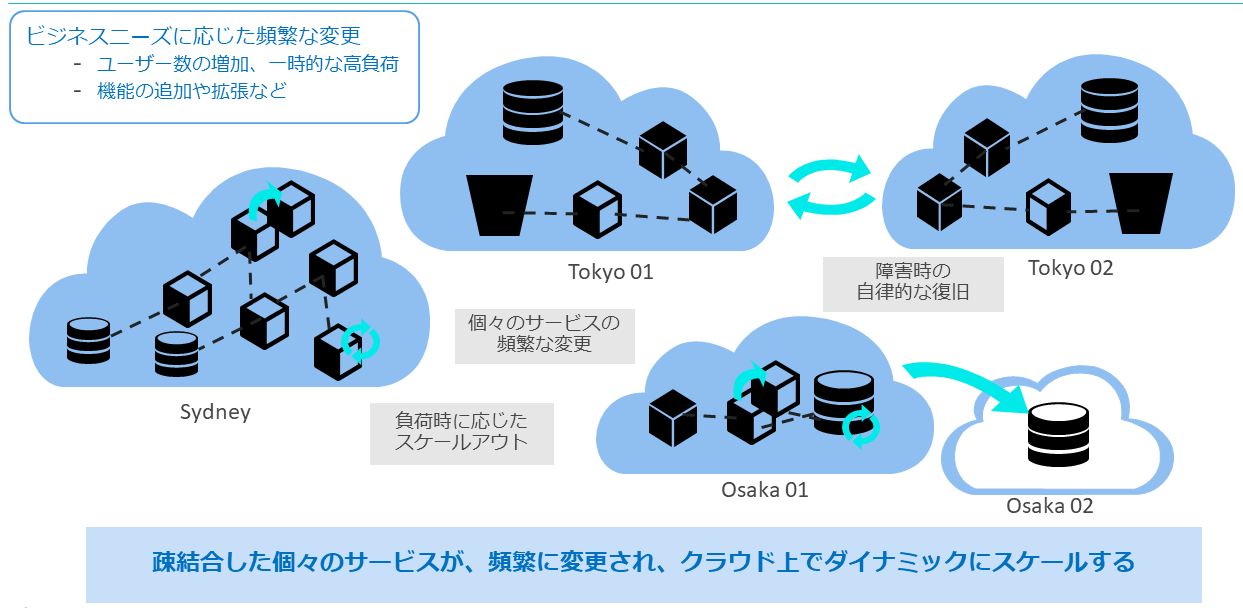
このCNCFが提唱するクラウドネイティブの定義には、「クラウドのようなスケーラブルでダイナミックな環境において」「クラウド・ネイティブ・テクノロジーはインパクトのある変更を最小限の労力で頻繁かつ予測どおりに行うことを可能にする」という記述がある。

これらの記述から、クラウドネイティブなテクノロジーが実現したい状況を以下のように解釈できる。
・マイクロサービスに代表されるような疎結合された個々のサービスが
・(一時的にユーザーのアクセスが集中するなどの)高負荷の状況に応じてクラウド上でダイナミックにスケールしながら稼働し
・ビジネスの変化に対してアジャイルに対応しながら頻繁に変更や機能拡張されていく中で
・インパクトのある変更を最小限の労力で頻繁かつ予測どおりに行うこと
そこで、本稿では「クラウドネイティブな運用とは、(システムに対してインパクトのある変更を伴う)ビジネスへの柔軟な対応と安定した稼働の両立を目指す活動である」と定義し、こういった運用を実現していくためのヒントについて共有していきたい。
変化と安定を両立させるアプローチとしての
Site Reliability Engineering
「変化」と「安定」を両立させるには、具体的にはどのようなアプローチが考えられるだろうか。先進的な取り組みを行なっている組織では、下記のようなアプローチが実践されているそうだ。
・数値化/文書された基準やルールの整備、手作業の排除と独自プラットフォームを使った大規模な自動化など、個人に依存しない運用の徹底
・継続的な改善活動に費やす時間を確保しやすくするための調整や管理のための枠組み
このようなアプローチは、ソフトウェアエンジニアリングの考え方を活用した運用とも言える。運用にソフトウェアエンジニアリングのアプローチを取り込み、変化の中でシステムの信頼性を維持する取り組みは、「Site Reliability Engineering (SRE)」と呼ばれている。
SREという言葉は、Google社のBen Treynor Sloss氏が作った用語と言われている。役割であり、一連のプラクティスであり、それらのプラクティスを生み出す信念、とされている。
どこから、何から始めたらよいのか
3つのヒントとアイテム
クラウドネイティブ、SREといった言葉はあちこちで聞かれるようになり、日本でもSRE NextといったイベントやSREをテーマにしたさまざまなMeetupも開催されるようになってきた。こういったイベントに参加すると、国内のさまざまな企業でSREに関する取り組みが徐々に広まっていると実感する。
その一方で、実際に、新たにマイクロサービスやKubernetes等の技術を使ったアプリケーションの開発に取り組み始めたユーザーやプロジェクトの現場では、こんな声を聴くことがある。

特にこれらは、PoC(Proof of Concept)として開発を始めて、いざ「Production対応を進めよう」となった際に聞く言葉でもあると感じる。
そんな疑問をもつ人たちに、本稿では筆者自身が実際に参考にした、以下の3つのヒントとアイテムを紹介したい。
ヒント1 SRE Onboarding Process+Scrumのプラクティス
ヒント2 Cloud Service Management & Operations(通称、CSMO)
ヒント3 Production Readiness Checklist

ヒント1 SRE Onboarding Process+Scrumのプラクティス
Onboardingという言葉自体は、「新たに雇用したメンバーが組織やサービス/製品に慣れるようにするためのプロセス」と定義されており、「新メンバーが組織で効果的に動けるようにするためのEnablement」と言った意図で使われることも多いが、ここでは「組織やサービス/製品にSREを適用していくためのプロセス」をSRE Onboarding Processと呼ぶ。
Google社の場合は、既存のサービスを評価してSRE チームによる運用を開始するまでのプロセスが定義されており、以下の2つのフェーズで構成されている。
◎Entrance Review(SRE による事前レビュー)
◎SRE Onboarding/Takeover(SRE への担当引き継ぎ)
Entrance Reviewは、「SREチームが既存のサービスをサポートするべきか、どのような前提条件で引き継ぐか、などを事前評価する」プロセスであり、SRE Onboarding/Takeoverは、「開発チームと SRE チームが、SRE チームがサービスの主要な運用責任を負うことに合意し、SRE がどのようにサービスを引き継ぐかを交渉する」と定義されている(「SRE へのサポート移行で失敗しないために : CRE が現場で学んだこと」)。
「Entrance Reviewでサービスが SRE のサポートに適していると判断された場合、開発者と SRE チームはOnboardingフェーズに移行し、SRE がサービスをサポートできるように準備する」(「Making the most of an SRE service takeover? CRE life lessons」)とされている。
IBMでも、SRE Onboarding のプロセスが定義されている。学習や現状の評価および計画といったいくつかのフェーズに分かれて、段階的にSREによる運用体制の構築を進めていくプロセスとなっており、最終フェーズが「実践し、振り返り、改善する」フェーズとされている。
「反復的に継続して実践できる状態」をSRE Onboardingのゴールとして考えている点に、注目したい。
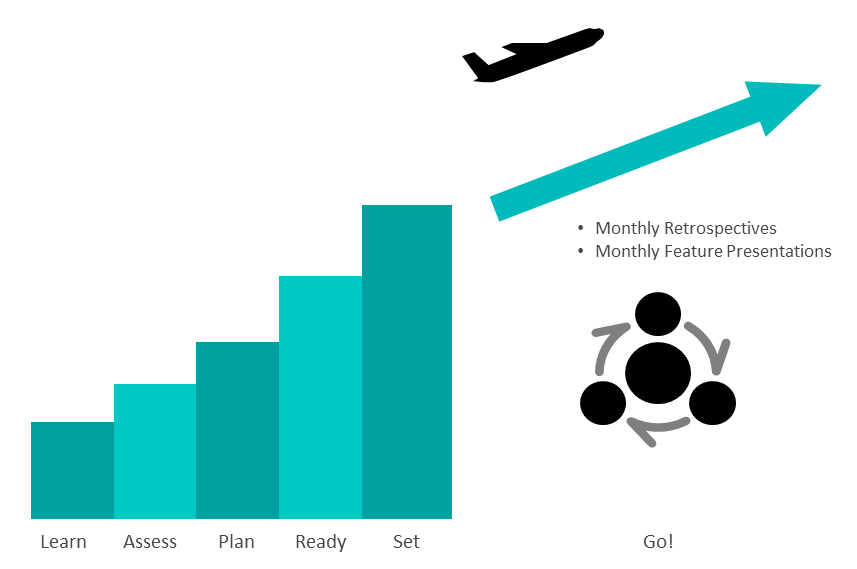
本稿の冒頭に、「運用にソフトウェアエンジニアリングのアプローチを取り込み、変化の中でもシステムの信頼性を維持する活動を行うこと」がSREの活動であると記した。
そのためには、機能の拡張と信頼性を改善するための活動を「反復的(Iterative)」に実践する必要がある(「Site Reliability Engineering, the cloud approach to operations」)。
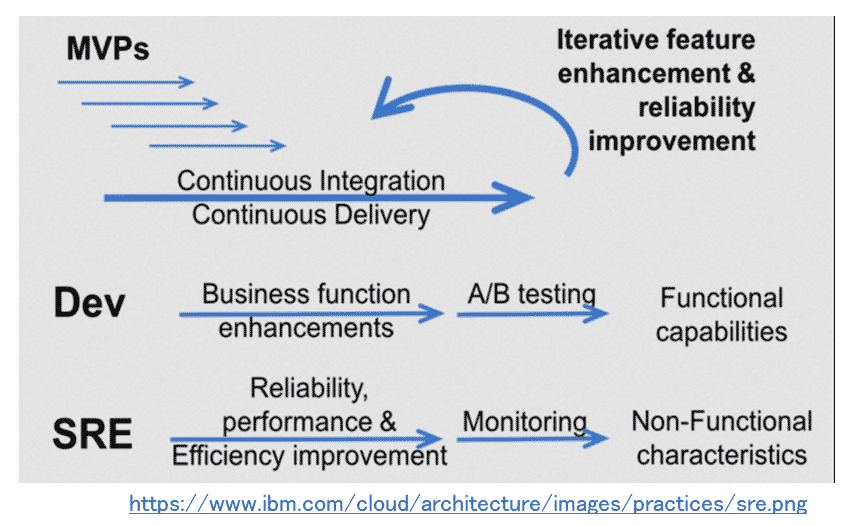
SREチームが行うタスクや編成パターンは、どのようなサービスを提供しているかや、メンバーの成熟度などにより異なってくる。同様に、SREの活動を反復的に継続して実践できる状態を目指すためのアプローチも、それぞれの組織や提供対象のサービスにより異なってくるものと言える。
ちなみにIBMでは、SREを適用するパターンの定義などが社内のSRE Communityで公開されている。Google社でもSREの実装パターン(6つ)の説明に補足して、これ以外のパターンもあるだろうと言及されている(「How SRE teams are organized, and how to get started」)。
つまりSRE Onboardingのアプローチとは、他の組織での例をそのまま自組織で再利用できるといった類のものではなく、自分たちの組織として自分たちなりに、目指すビジョンやそこに至るための中間目標を定義し、目標達成のアクションをとる必要がある。SREの職務定義自体が、それぞれの組織や提供するサービスに応じて変わると考えたほうがよいだろう。
このような、「自分たちなりのゴールを定めて計画する」アプローチについては、Scrumのプラクティスが非常に有用であった。
一般的に、Scrumに代表されるアジャイルな方法論は、スピード重視で方向性を試行錯誤し、最終的なプロジェクトがどうなるのか、開始前には判然としないようなチームに適していると言われる(「Agile Vs. Waterfall: Which Project Management Methodology Is Best For You?」) 。
この点はまさに、試行錯誤しながらSREに取り組む初めてのケースなどにフィットしやすいと考えられる。複数のユーザーと取り組んだ筆者自身の経験からも、そう実感している。ただし、実際のSREの業務では、ScrumよりKanbanが適しているケースもあると考えられる(「Can scrum be used effectively by SRE teams?」)。
筆者の経験では、SRE Onboarding Processを参考に、Scrumのプラクティスを活用する形で以下のようなアプローチをとった。
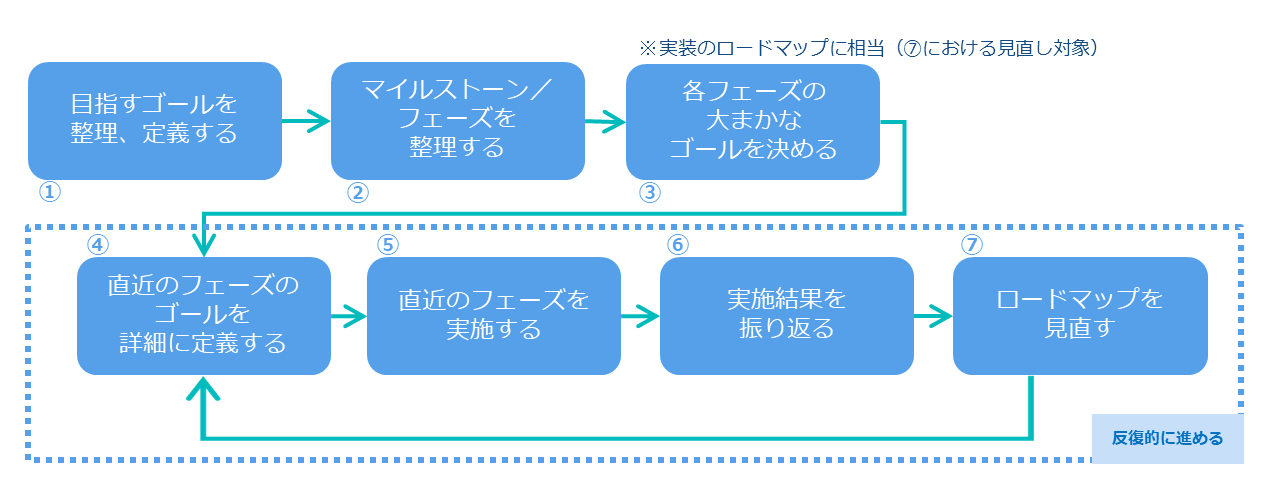
「自分たちなりに考えていく必要がある」とは言え、実際のところ、ロードマップやマイルストーンごとの目標はどのように定義したらよいのだろうか。全体像を意識しながら自分たちの開始点(小さな一歩)を踏み出すには、何らかのリファレンスが必要になるだろう。
また「SREのプラクティスはすべて実践しないと意味がないのか」「既存の運用はすべて変える必要があるのか」も、気になる点である。
こういった悩みに関しては、筆者自身が有用だったと考える残り2つのヒントとアイテムを紹介したい。
ヒント2 オペレーションに関する
ロードマップやリリースバックログの定義
まず紹介するアイテムは、CSMOである。正式な名称としては、IBM Cloud Service Management & Operationsと呼ぶ。
CSMO はハイブリッド環境、マルチクラウド環境のためのサービスマネジメント体系であり、IT およびクラウドの運用管理に関する計画、設計、提供、運用、および制御について、「組織」「プロセス」「ツール」「カルチャー」の観点からベスト・プラクティスがまとめられている(「ハイブリッド/マルチクラウド環境におけるITマネジメント」)。
現場では、「オペレーション」として目指すべき全体像を把握し、検討範囲や優先順位を考える際にCSMOを参考にした。
特にサービス管理のプラクティスについて、「コア」「スケール」「サービス指向」の分類があり、ビジネスやプロダクトの想定に合わせて、「どこから整備していくか、取り組むか」を検討する際の指針として有用だった。
また、サービス管理のソリューションを設計するためのReference Architectureが提供されており、これを検討のベースに利用することも可能である。
次に、具体的な進め方について補足する。
まずCSMOをもとに、運用の検討項目を(抽象度の高いEpicレベル)バックログとして洗い出し、優先順位付けを実施した。
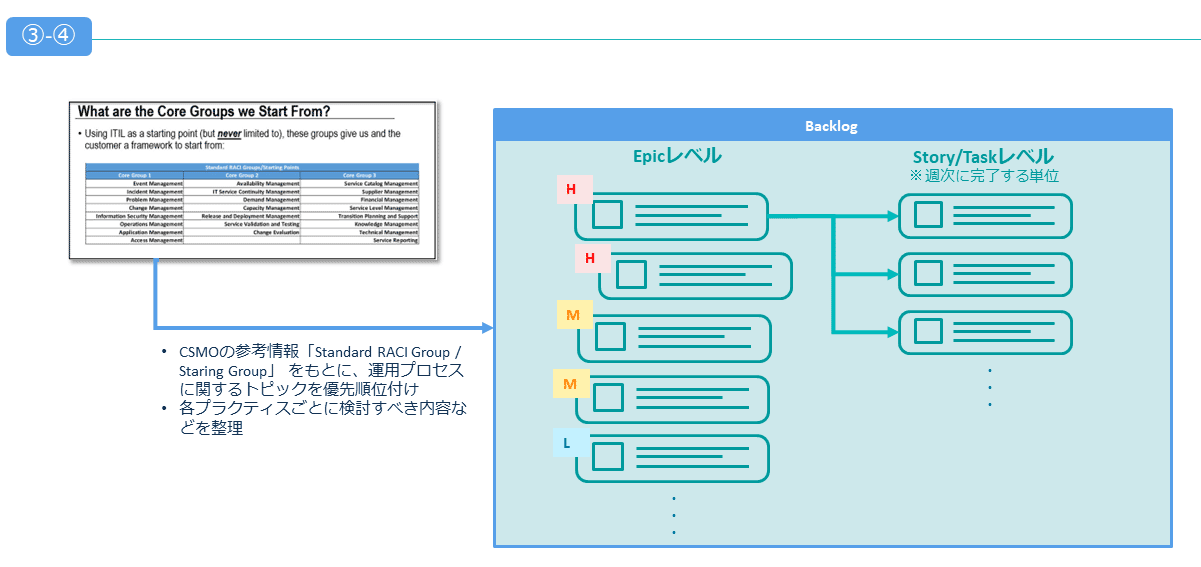
これらのバックログをそれぞれ検討した結果を踏まえ、「運用方針書」の目次として整理し、そこからシステムとして設計や実装上の考慮が必要なもの、もしくは運用手順やルールとして実装していくことにした。
各バックログはScrumのリズムで実装を進め、最終的には運用テストのテストケースとして実装内容を評価する形をとった。
ヒント3 Production Readiness Checklistを活用したロードマップやリリースバックログの定義
最後に紹介するアイテムは、Production Readiness Checklistである。
これはサービス/製品を本番環境へリリースする前の、信頼性観点でのチェックリストであり、『プロダクションレディマイクロサービス』(オライリージャパン刊)にも登場する。
SREのプラクティスとしては、「Production Readiness Review」プロセス(「The Evolving SRE Engagement Model」) があり、さまざまな企業では、自分の組織に合わせたチェックリストやレビュー・プロセスが整備されている(GitHubなどに公開されているチェックリストを探して参照するのも勉強になる)。
プロダクトや組織体制にも依存するため、チェックリスト自体はそれぞれのコンテキストに応じて作成されるのが一般的である。
以下に、筆者自身がチェックリストを作成した際の経験について補足する。
当時、Kubernetesを前提としたマイクロサービス・アーキテクチャのシステム案件を、チームで複数担当している状況であった。Kubernetesやマイクロサービス、またそれらが稼働するクラウド・プラットフォームで推奨されるプラクティスを、海外のカンファレンスやワークショップ等の情報も参考に、メンバーと議論しながらチェックリストとしてまとめた。
さらに実際に取り組む際には、「段階的な取り組みが必要なものは何か」「どういう段階に分けて取り組むか」などを整理した。
調査や整理の時間が必要ではあるが、こういった形でチェックリストを整理しておくことで、類似の案件でProduction Readyなシステムを構築する際にも再利用できて有用だった。
参画した案件では、このチェックリストの項目からリリースバックログを抽出し、優先順位付けを行なった。
各リリースの対象となったバックログは、段階的に取り組むとしたものについては、目指すレベルを明確にし、進捗を管理するようにした。主に、Kubernetesおよび関連するサービスが、プラットフォームとして提供する運用機能や可用性の実現に相当する内容をバックログとして抽出した。
実践し、振り返り、改善するサイクル
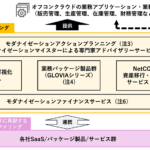
マイクロサービスおよびプラットフォームの実装と、それを運用するプロセスの整備は密接に関わるので、同じスプリントの中で実装を進めるようにした。CSMOとProduction Readiness Checklistをインプットとして、アウトプットは以下のような構成となった。
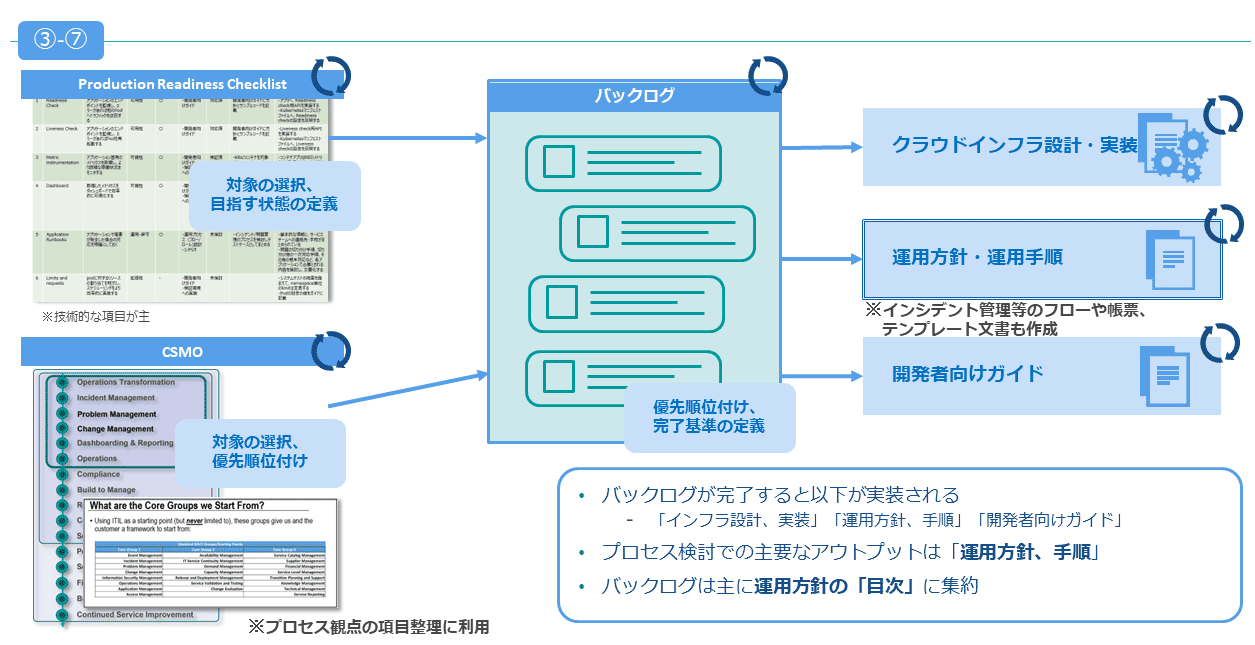
これらのアウトプット作成の流れを、ヒント1で紹介したScrumの流れでどのように利用したかを、次の図表で補足する。
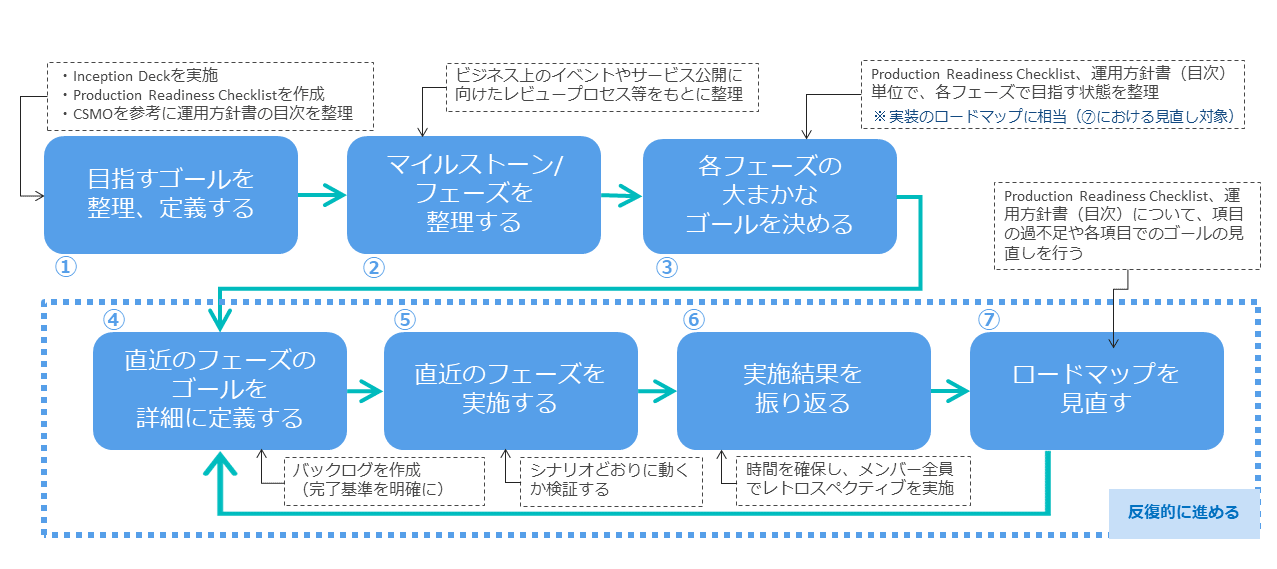
この図表の⑦のステップ「ロードマップの見直し」については、主に、Production Readiness Checklistと(CSMOを参考に定義した)運用方針書の見直し、各反復での振り返り結果をもとに実施した。

クラウドネイティブな運用への取り組みは
自分たち主体で考え、試行することが重要
『Effective DevOps ―4本柱による持続可能な組織文化の育て方』(オライリージャパン刊)には、下記のような記述がある。
・DevOpsの成功事例等から学ぶ際には、「ストーリー」(何が機能し、何が機能しなかったか、それに加えて、意思決定を生み出した試行プロセス)を理解することが大切
・成功事例の「猿真似」では意味がなく、ストーリーを読み、現時点での自分の経験や将来を考え得る姿と照らし合わせて考えることが大切
・共有されたストーリーを学ぶだけでなく、新しいプロセス、ツール、テクニック、アイデアを試そう
・試した結果も踏まえ、自分(の組織)にとって機能するもの/しないものを判別できるようになるために、「自分にとっての理由」を理解することが大切
クラウドネイティブな運用への取り組みについては、「自分たちで継続して機能の拡張や信頼性の向上に取り組める状態」を目指す必要があり、そのゴール設定やアプローチは、それぞれの組織や提供するサービスに応じて、自分たち主体で考え試行することが重要だと思える。
今回紹介した3つのヒントとアイテムが、現場で取り組んでいる人たちに少しでも参考になれば幸いである。