SQLインターフェースを通して、いかに有効にIBM iの情報へアクセスするか、どうすればIBM iの資産を有効に活用できるか。本特集ではこれをテーマに、IBM iに必要なSQL情報をお届けする。第2回はIBM iでSQLを使いこなすための基本情報として「UDTF」と「ストアード・プロシージャー」の2つを紹介する。
UDTF
table関数で呼び出す機能を作成する
データ取得のロジックのみを
UDTFで実装する
前述したIBM iサービスで、table関数内に記述して実行されるサービスを紹介した。このサービスが提供される以前は、その情報にアクセスするにはIBM iのコマンドを経由するか、プログラムからAPIにアクセスするしか方法がなかったので、SQLのSELECT文でその情報にアクセス可能になったメリットは大きい。
しかもSELECT文で利用するので、実行結果は表形式で取得できるため、2次利用もしやすい。一方、IBM i サービスで提供されていない場合は、従来どおりのAPIを必要に応じて呼び出すしか手はないのだろうか。
実は、table関数で呼び出される機能はユーザーでも作成できる。これを UDTF(User Defined Table Function)という。つまりSQLのSELECT文を使用して取得する情報をデータベースやIBM i サービスに限定するのではなく、必要に応じてユーザーもその機能を作成できる。
いくつか例を紹介しよう。
① 複数テーブルに分散している顧客の基本情報を表形式にまとめて取得したい
② 顧客の月単位の売上を年度ごとに集計して取得したい
③ 顧客の昨日の注文情報を取得したい
当たり前だが、これらの機能はすでに基幹システム内で実装されており、ユーザーは自由にアクセスできる。その情報を知りたいユーザーは、情報がどのテーブルに入っているか、その名前は何か、必要なフィールド名は何かを知る必要はない。単に顧客情報照会プログラムや伝票照会プログラムなどを、メニューから選択すればよい。
仮にプログラムがなかったとしても、①のケースのように、複数テーブルの名称がわかればJOINすればよいので、わざわざUDTFにする必要もないだろう。
ただしこれらのプログラムは、照会したデータが画面に表示されるか、もしくは印刷されるかがほとんどで、2次利用できないケースが多い。
たとえば、ユーザーが画面に照会した一定期間の注文情報の商品ごとの合計金額が必要であるだけなのに、その情報が画面や印刷結果にない場合、プログラムにその項目を追加するよう依頼するか、照会した情報をその都度 Excelに入力して集計するしかない。
JOINも既存フィールドのみで構成するのであれば問題ないが、複雑な計算により、新たなフィールドを追加せねばならない場合、複雑なSQLを作成することで保守の難しいプログラムになる可能性がある。
さらに基幹システムのプログラムは、データを表示したり、印刷するためのロジックも入っているので、その意味でも2次利用は難しいだろう。
では、これらの既存プログラムから純粋にデータを取得するロジックのみを切り出して、UDTFで実装するのはどうだろうか。わかりやすいように、上記③の注文情報取得ロジックで説明したい。
注文明細ファイルから顧客A00001 の昨日の注文データを取り出したのが、図表1である。
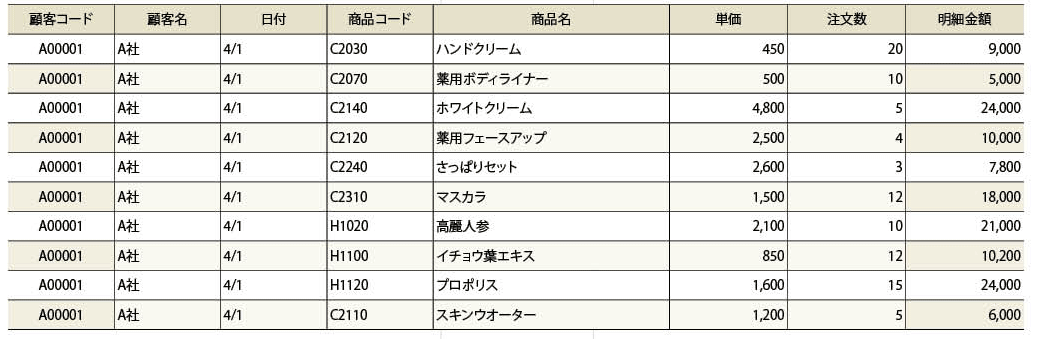
注文明細ファイルには顧客名と商品名はないので、それぞれ顧客マスターと商品マスターから名称を取得し、明細金額も計算したものをセットしている(通常、得意先コードは明細ではなく注文ファイルにもつが、ここではわかりやいように注文明細にもたせている)。
この情報をGet_Order_Dataという名前のUDTFで実装すると、以下のようなSELECT文でこの表を取得できるようになる。

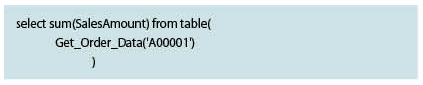
さて、上記データの明細金額(SalesAmount)の合計が知りたいとしよう。その場合は、次の SQL を実行すればよい。
注文件数を知りたい場合は、以下になる。

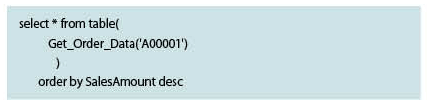
明細金額の降順で並べたい場合は、以下になる。
おわかりだろうか。あたかもGet_Order_Dataという名前のテーブルがあるかのように select 文で利用できる。しかも、検索条件を指定することも可能だ。
UDTFを作成する手順
IBM iでプログラムを作成したことがあるなら、図表6の情報を取得するロジックは簡単に思いつくだろう。さらにそのロジックをUDTFとして作成すれば、生成した表の2次利用は簡単である。
呼び出すのはselect文経由なので、Java、Python、PHPなどの言語から簡単に呼び出せる。組み込みSQLを使用すれば、RPGからも呼び出せる。
この顧客別注文データ検索UDTFがあれば、5250画面にサブファイルで表示させることも、PHPなどを使ってブラウザに表示させることも可能だ。Get_Order_DataというUDTFの名称と、顧客コードをパラメータとして渡すことだけを知っていればよい。
実はこのアプローチは、ビジネスロジックを細かいサービスに分けて実装するマイクロサービスにほかならない。SELECT文から呼ばれるということは、結果が表で戻ってくるということだ。上記のような機能単位でプログラムを設計することで、SQLを実行可能なプラットフォームであればどこからでも呼び出せる。つまり再利用性が高まることになる。
UDTFはさまざまな言語で作成できるので、各言語の特性を最大限に活かしたプログラム設計を行えばよい。利用する側はSELECT発行のみなので、その情報にアクセスするためのビジネスロジックはすべてUDTF内に記述することになり、複数プログラムへのロジックの分散を回避することにも繋がる。
UDTFを利用する手順は、以下のとおりである。
① プログラムの作成(サービス・プログラムの関数としても可能)
② create functionでUDTF の定義を登録(初回のみ)
③ select文に記述するtable関数から呼び出し
プログラムあるいはサービス・プログラムを作成するだけでは、UDTFとして利用することはできない。CREATE FUNCTIONを実行して初めて利用可能なので、上記ステップを忘れないように注意する。
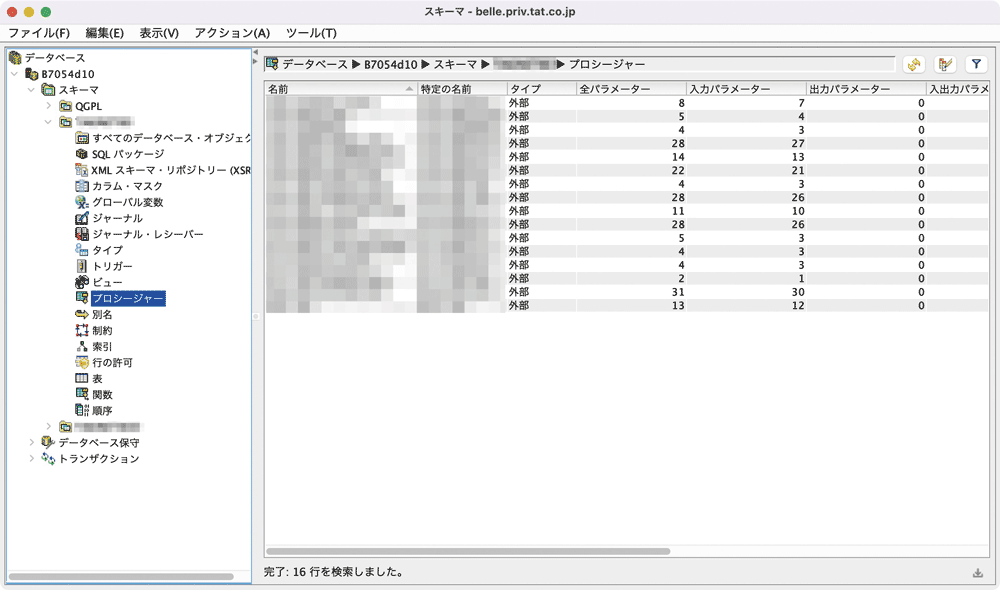
現在登録されているUDTFは、Access Client Solutions(以下、ACS)のスキーマ機能の関数一覧表示で確認できる(図表2)。
ストアード・プロシージャ―
RPGをはじめ多様な言語で記述する
データベースに対する一連のロジックを
まとめてRDBMSに保存
前述したQSYS2.QCMDEXECというIBM iサービスはSQLのcallで呼び出すが、同様にcallで呼び出す機能をユーザーにより作成できる。これを、「ストアード・プロシージャー」という。ストアード・プロシージャーは、データベースに対する一連のロジックをまとめてRDBMSに保存したものだ。
IBM iでは、このストアード・プロシージャーもUDTFと同様にさまざまな言語で記述可能であり、もちろん RPGでも作成できる。
では、ストアード・プロシージャーの利用例を紹介しよう。
① 注文データを受け取り、関連テーブルに追加する
② 顧客情報などの保守(追加、変更、削除)
③ 複数テーブルへの保守時のトランザクションの管理
④ データ保守後の処理
ストアード・プロシージャーに渡すパラメータも、UDTFと同じように引数として定義する。上記②の場合は、顧客情報をそれぞれ引数として定義して渡すことになる。

注文データの登録などは、行ごとにストアード・プロシージャーを呼び出すのではなく、複数行の注文データをJSON形式に変換して渡すなどすればよい。

ここでOrder_Jsonは、注文情報を記述したJSON形式のデータとする。RPGでは、渡されたJSONデータをdata-into命令を使用してデータ構造にインポートして利用する。
またデータベースへの保守のみならず、たとえばデータ待ち行列へのデータ送信とか、基幹システムに存在しているバッチ型プログラムの呼び出しなど、使用している言語で可能なことは基本的に何でも行える。
ストアード・プロシージャーを利用するまでの手順は、以下のとおりである。
① プログラムの作成(サービス・プログラムの関数としても可能)
② create procedureでストアード・プロシージャーの定義を登録(初回のみ)
③ call文で呼び出し
ストアード・プロシージャーもUDTFと同様に、作成するだけでは実行できない。CREATE PROCEDUREを忘れないようにする。
現在登録されているストアード・プロシージャーも、ACSのスキーマ機能のプロシージャー一覧表示で確認できる(図表3)。