ミドルウェアやデータ形式の違いを吸収する
あらゆるモノで発生する多種多様な情報をつなぎ合わせ、分析・活用し、次の経営資源へと変えていく。今、モノのインターネット(Internet of Things: 以下、IoT)の潮流に乗り、多くのユーザーが取り組みに着手している。
その反面、どのように情報同士をつなげればよいか、どうすれば経営資源の源泉となり得るか、その未来を誰も見通せてはいない。筆者がIoT基盤ライブラリの提案によりプロジェクトを支援しているユーザーでも、試行錯誤を繰り返しながら、データの中継拠点となるIoT基盤を構築している。
本稿ではその経験を踏まえ、IoT基盤ライブラリを紹介するとともに、アジャイル開発やライブラリ化する意義を解説する。
なおここでは、IoTデバイスからデータを収集・変換・格納する機能を集約した環境を「IoT基盤」、IoT基盤を構築するためのライブラリを「IoT基盤ライブラリ」と呼ぶことにする。
なおここでは、IoTデバイスからデータを収集・変換・格納する機能を集約した環境を「IoT基盤」、IoT基盤を構築するためのライブラリを「IoT基盤ライブラリ」と呼ぶことにする。
なぜIoTにアジャイル開発が必要なのか
IoTの潮流により家電や自動車、ドローン、工場設備など、今までインターネットにつながっていなかったモノが、次々とつながり始めている。IoTデータを分析したり、分類したりする新しいサービスも続々と登場している。
ただし、この目覚ましい発展もIoT基盤の開発者から見れば、今までつなぎ方も、存在さえも知らなかったモノからIoT基盤へ、ある日突然、大量のデータが流れ込み、先日公開されたばかりの新サービスへデータの中継が求められる事態を意味する。とくにIoTデバイスとサービスは「たすき掛け」に連携が求められる場合もあり、システムの維持に多大な労力を要することになる。
筆者が支援するユーザーは、IoT基盤を新規に構築している。同じようにIoT基盤の新規構築を検討している読者も多いことだろう。
旧来の開発は、「あらかじめ要件をすべて洗い出し、その要件は変わることがない」「決められた範囲については、すべて理解が行き届いている」ことを前提にしている。筆者を含む多くのエンジニアが数十年にわたり、それを前提にシステム化を続けてきた。
別の見方をするとそれは、すでにわかっている前提で作成するのであれば、すでに誰かが作成済みであることを意味する。とくにソフトウェアは一度作成すれば、コピーで済むため、新規開発は不要となる。
つまり、ビジネス課題の解決に向けて今まさに開発しようとしているソフトウェアは、現時点ではほかに存在しないために、仕方なく新規開発しているわけだ。開発対象のソフトウェアは、正解を知っている前提ではこの世に生み出されなかった以上、誰も正解を知らない。
ユヴァル・ノア・ハラリ氏は、その著書『サピエンス全史 上・下 文明の構造と人類の幸福』(ユヴァル・ノア・ハラリ著、河出書房新社)のなかで、「二次のカオス系は、それについての予想に反応するので、 正確に予想することは決してできない」と述べている。
私たちはIoTを使って、ビジネス課題を解決しようとしているが、その状況を他のプレイヤー(競合他社やビジネスパートナー、新規参入者など)と常に注視し合っているので、このビジネス課題自体が二次のカオス系である。
これからの新規ソフトウェア開発では、長期にわたる完全な予測はできず、正解を誰も知らず、失敗の可能性が常に付きまとうことを受け入れねばならない。
アジャイル開発では、開発したシステムがビジネス課題を解決するうえで、役に立ったかどうかを短期間で評価し、「これは役に立った」「これは役に立たなかった」と実績を計り、次のアクションの有効性を高めるように継続して実施する。
これにより想定と違うことを見つけ、当初見えていなかった課題を早期に解決しようとする。これこそ、私たちがアジャイル開発を志向する意義であり、旧来に比べてより投資戦略に沿った開発と言える。
IoT基盤ライブラリのコンセプト
アジャイル開発では有効性に基づいて開発の内容を変えていくので、プロジェクトの進行とともにソフトウェア開発の前提も変化する。以下にその例を紹介しよう。
たとえば筆者の担当するIoT基盤プロジェクトでは、プロジェクト初期に、IoTデバイスからデータの受け口となるMQTTブローカーをオンプレミス環境に導入した。このMQTTブローカーからデータをデータレイク(PostgreSQL)へ転送するために、IoT基盤ライブラリを使用していた。
その後、Kafkaの有用性に着目し、Kafkaとの接続を検証した。さらにCassandraをデータレイクとして利用しようと試み、開発・検証環境としてパブリッククラウド(IaaS)環境を使用し、バーチャルマシン上でdockerを利用し始め、ついにはマネージドなKubernetes環境でコンテナのオーケストレーションを管理するに至っている。
IoT基盤ライブラリは機能追加やリファクタリングを伴いつつも、このすべての状況で動作し続けている。
筆者は2014年ころから、IoT基盤のライブラリ化を実践してきた。業種や業務内容を問わず、開発プロジェクトを技術支援するのが筆者の役割である。
そのため、「WebSocketやMQTT、RDBなど固有のAPIを備えるミドルウェアと親和性を保ちつつ、業務処理の内部ロジック自体はその違いを意識せずに済むよう、ライブラリで吸収する」といったように、外部環境も、取り扱うデータの特性も、適用業務もまったく異なる状況で機能するライブラリには大きな意義があると考えた。
高度に抽象化したIoT基盤ライブラリのコンセプトを説明するため、最初に作成したのがバケツとボールで表現した図表1である。
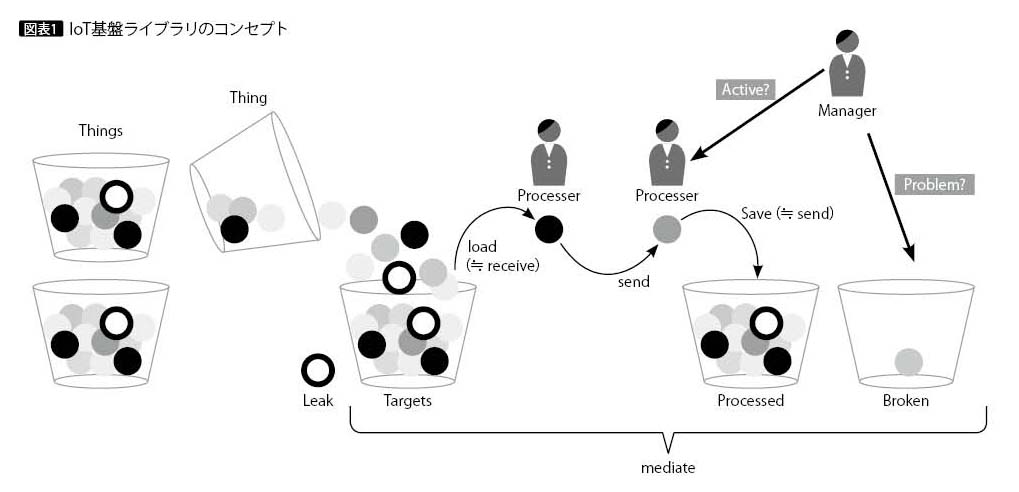
ボールに見立てたデータと、その入れ物であるバケツ。IoTデバイスからは、乱雑にボールがバケツに注がれる。そのボールを1つ1つ取り出して検査したり、加工したりとそれぞれの役割の人が連携し、ボールを別のバケツに注ぐ。ボールを乱雑に扱えば、こぼれたり、壊れたりする。さらに作業している人が倒れたり、バケツが壊れることもあるだろう。
つまりIoT機器の中継リレーでは、データがこぼれることもあれば、壊れることもあるので、そのような状況も監視する必要がある。これらを実現することが、筆者の考えるIoT基盤ライブラリのコンセプトである。
IoT基盤上を行き交うIoTデータの特性は、IoTデバイスによって千差万別であり、データを貯めたり、連携したりするミドルウェアも、それぞれの状況によってインターフェースの形式は多種多様である(図表2)。
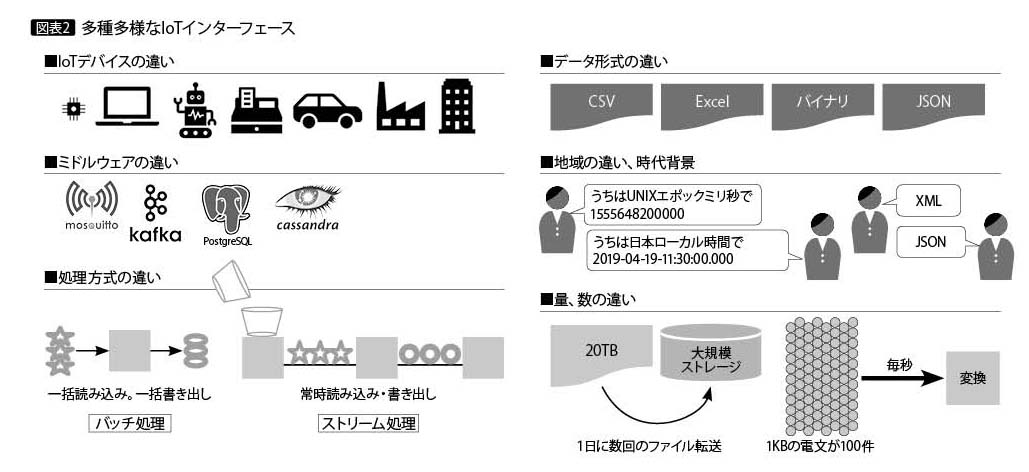
このほかにも、システム規模や業務、時代背景など考慮すべき事項は多岐にわたっている。IoT基盤では、そのような違いをIoT基盤ライブラリが吸収している。以下に、それについて解説する。
ミドルウェアの違いを吸収する
プロジェクトでは時間当たりの件数や容量、保管期間、アトミック性の有無、格納や取り出しやすさなど、多数の評価項目に従ってミドルウェアを決定する。
たとえばMQTTの場合は、多くのIoTデバイスがサポートしており、受け口としての利便性は高い。その反面、揮発性が高く、障害復旧時に後続ジョブの再投入で整合性を担保するような使い方は難しい。これに対してKafkaでは、IoTデバイスによるサポートはあまり期待できないが、データはストレージ上に比較的長期間留まり、レコードIDをもとにジョブを再投入して、データの整合性を担保できる。
このようにミドルウェアはさまざまな特性をもつので、最適なミドルウェアや組み合わせは状況により変わる。ただし、アプリケーションはそうしたミドルウェアのAPIに合わせた動作が必要である(図表3)。
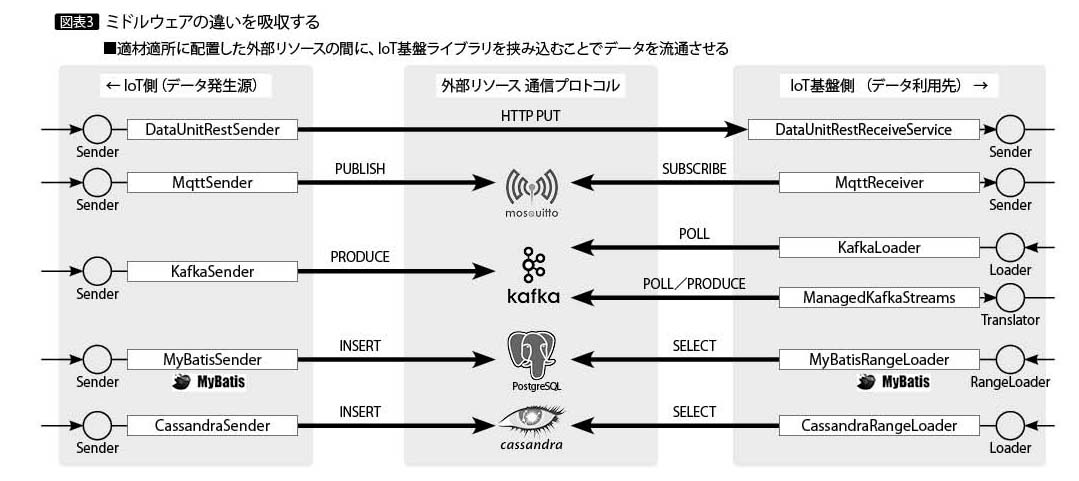
IoT基盤ライブラリは、たとえミドルウェアに変更があっても接続部品の置き換えで済ませ、アプリケーション固有のロジックには変更が生じないようにしている。
さらにRDBなどでクエリを発行してデータを得る場合も、RDBではMyBatisを利用したり、Cassandraのように独自のクエリ言語を持つミドルウェアではクエリを外部ファイル化したりといったように、クエリの変更を単独で行えるようにした。これにより、テーブルへの項目追加やDB設計の見直しがあっても、クエリの置き換えで対応可能である。
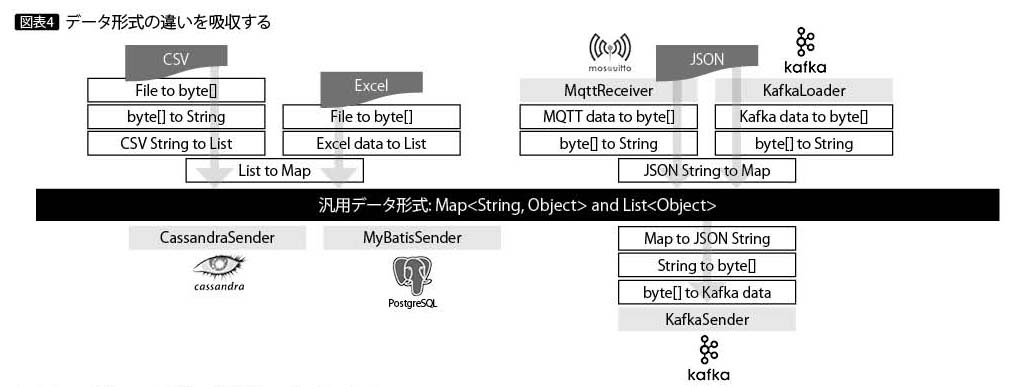
データ形式の違いを吸収する
IoTデバイスやミドルウェアごとに、データ形式は異なる。バイナリでは静止画や動画、車載器のように業界標準のフィールド定義や独自のデータ構造がある。テキストではListやCSV、XML、JSONなどの形式がある。そのほかミドルウェア固有の情報を付加するなど、IoTデータのバリエーションは多彩である。
単一のシステム構築であれば、収集する側のインターフェースと格納する側のインターフェースに合わせて、アプリケーションを開発するのも一策であろう。
しかしミドルウェアもIoTデバイスも、その時々の判断で入れ替える可能性がある。そもそも多種多様なミドルウェアやIoTデバイスを利用する状況で、すべての組み合わせを前提に開発すると、コード量が爆発的に増える。
IoT基盤ライブラリでは、辞書形式のMap型や配列形式のList型を組み合わせ、ツリー構造を汎用的に表現したデータ形式を中核に据えている。そして各種データ形式は単機能の変換部品を数珠つなぎにすることで、元のデータ形式と中核に据えたデータ形式を相互に変換可能にしている。
IoT基盤ライブラリを利用するアプリケーション内で、この中核に据えたデータ形式が、IoTデバイス、各種ミドルウェア、その他の外部サービスとの間でデータの基軸通貨としての役目を担い、コード量の爆発を抑えつつ、新しいIoTデバイスの追加やミドルウェアの交換に対応する(図表4)。これにより、アジャイル開発の推進に寄与している。
IoTデバイスや
アプリケーションの違いを吸収する
工場内の設備から製品の計測データを収集する場合、その計測データが表現している内容は設備固有である。そのため計測データから、後続に控えている分析処理などのサービスへデータを連携するには、固有のデータ形式(たとえば単位を揃える、など)へさらに変換が必要になる。
ここでもやはり対応関係は複雑である。従来は、1種類のIoTデバイスと1種類の後続サービスに対応した1つの変換システムを開発することが多かった。しかし工場の生産規模に応じて設備の種類は増え、新旧の設備が混在し、需要によって設備を組み替える。後続のサービスもインターフェースは日々改良され、業務改善のためにサービスを追加する。従来方式を踏襲したままでは、IoT基盤は爆発的に大規模化していくだろう。
それに対してIoT基盤ライブラリが取ったアプローチは、テンプレート・エンジンの採用である。テンプレート・エンジンは、メール広告などで広く使われており、たとえばメールのテンプレートと顧客情報から顧客固有のメールを作成している。
IoT基盤ライブラリでは、データ形式変換にテンプレート・エンジンを利用している(図表5)。
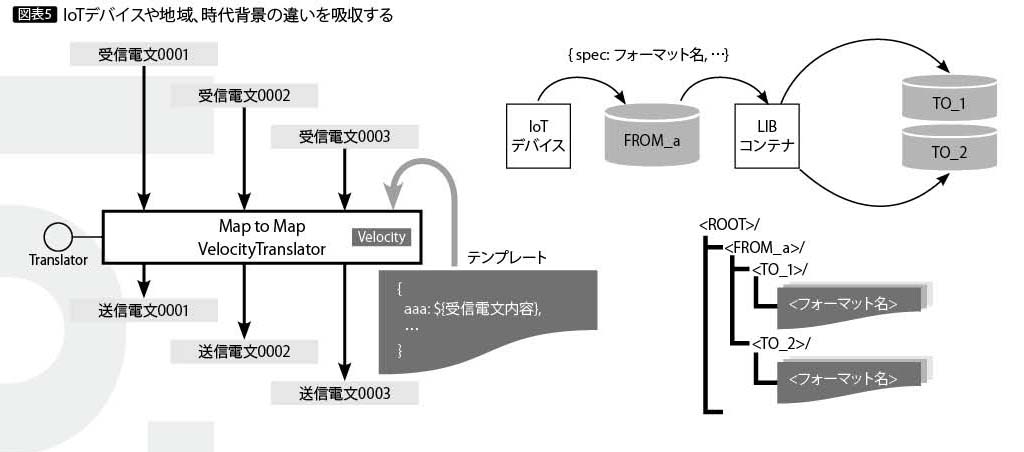
とくに電文をダイナミックに変換する仕組みにより、テンプレートファイルを「入り口」「出口」「デバイスのデータ仕様とそのバージョン番号」としてディレクトリに配置した。
これにより設備の追加はテンプレートの追加で、デバイス仕様の変更は新バージョンのテンプレートの追加で済んでいる。
従来のアプローチではシステムの大規模化を避けるのは難しいが、このアプローチであれば、1台のPC上で1万5000種類のIoTデバイスの電文仕様を、2000件/秒で2つのサービスに振り分けられるほど、コンパクトになった(もちろん耐障害性やスケーラビリティを考え、システムの冗長化や監視、復旧手順の作り込みなどは必要である)。
従来のアプローチではシステムの大規模化を避けるのは難しいが、このアプローチであれば、1台のPC上で1万5000種類のIoTデバイスの電文仕様を、2000件/秒で2つのサービスに振り分けられるほど、コンパクトになった(もちろん耐障害性やスケーラビリティを考え、システムの冗長化や監視、復旧手順の作り込みなどは必要である)。
また修正作業1つをとっても、何人月分もの工数・工期をかけて発注し修正していた作業が、場合によっては自社の従業員による人日単位に短縮できる。コストの大幅な削減と工数の短縮により、ビジネス全体の生産性向上に寄与する。
新たなアプリケーションを試行する場合も、別ディレクトリにテンプレートを追加すれば済むので、アジャイル開発での試行錯誤を短時間で実施できる。
経験を積み重ねる
ここまで述べてきたように、IoT基盤ライブラリは環境変化への追随に主眼を置いている。しかし実は、IoT基盤のライブラリ化のずっと以前から、筆者はこのようなコンセプトとスタイルによりライブラリを作成し続けてきた。Webアプリケーション全盛のころもWebアプリケーションに特化せず、実行環境や外部リソースの違いに振り回されないように注意しながら、バッチ処理でもライブラリを利用してきた。
これまで作ってきた部品群の上に、IoT基盤ライブラリとして必要な部品を載せている。つまりIoT基盤ライブラリは、IoTという言葉が生まれる前から作成してきた部品を再利用しているわけだ(図表6)。
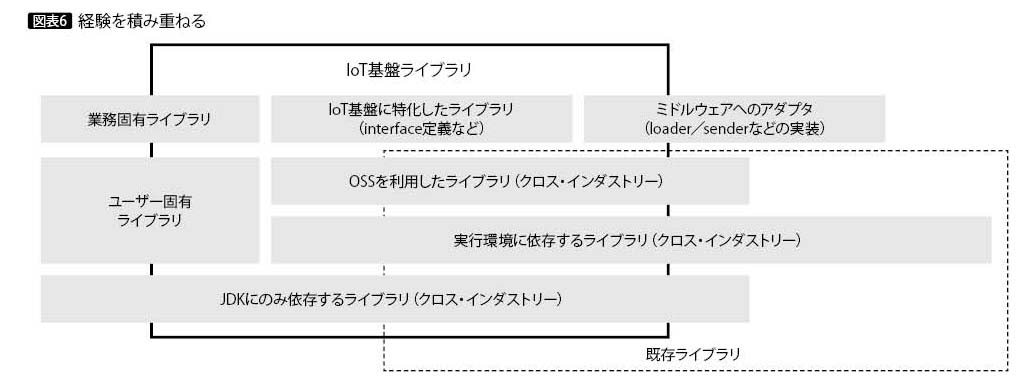
大半の部品は長期間にわたり、技術や業務処理の変化に耐え続けているので、今までよりも変化の早いアジャイル開発であっても、同じように耐えられると筆者は考えている。
アジャイル開発を推進するうえでも、基本的な機能は依存関係の少ない部品群に分けることが重要だとあらためて感じている。ソフトウェアは一度開発すれば、コピーして利用可能であり、今後、それらの部品群の開発は不要となる。今、アジャイル開発しているソフトウェアもライブラリ化できれば、将来の資産となり得るだろう。
IoT基盤を構築・運用・保守していくには、増え続け、変わり続けるIoTデバイスやサービスへの対応が求められる。それに応えるために、アジャイル開発の重要性が増している。
変化に耐えるにはデータを抽象的に捉え、テンプレート・エンジンなどで柔軟に変更追加できるのが望ましい。アジャイル開発でも汎用的な部品化を進めることで、将来的に恩恵を享受できるだろう。
著者|
津田 嘉孝氏
日本アイ・ビー・エム システムズ・エンジニアリング株式会社
第2ワトソン・ソリューション
アドバイザリーITスペシャリスト
第2ワトソン・ソリューション
アドバイザリーITスペシャリスト
1997年、日本アイ・ビー・エム システムズ・エンジニアリングに入社。Javaアプリケーション開発プロジェクト参画などを通じて、フレームワーク開発やDevOpsの先駆け的なリリース管理を実施。プロジェクト全体へ技術支援することで開発者の生産性向上を目指している。近年はIoTに関わる技術支援において、サンプルコードも提供している。

[IS magazine No.27(2020年5月)掲載]