Opsとは何か
NoOpsとは何か
DevOpsという言葉が登場して久しいが、日本の企業システム開発の現場では、いまひとつ導入が芳しくないようである。IDCの調査でも(国内DevOpsに関するユーザー調査結果を発表)、DevOpsを実践している企業の割合は35.7%(組織全体での採用が18.4%、一部での採用が17.3%)に留まっている。
ただし同レポートによると、とくに成長企業ではDevOpsの採用が著しく、DevOpsがビジネスの成功要因の1つになっていることが窺える。
また昨今では、「NoOps」という言葉も耳にする。NoOpsに関しては、「NoOps Japanコミュニティ」が情報交換の場を提供しているので(NoOps Japan Community)、興味があればぜひ参加してほしい。
本稿では、このNoOpsというキーワードに着目し、激変するITシステム運用に関する考え方の一例を示したい。まずはOps、そしてNoOpsとは何かを確認し、どのようにNoOpsを実現すればよいか、そのアプローチや利用可能な技術などを紹介し、最後にNoOpsを推進するための組織・体制について記述する。
DevOpsは現在でも解釈の幅が広いが、ここでの「Ops」とはそもそも何であろうか。運用担当者、オペレーターなどの「役割」、起動・停止・バックアップなどの「運用作業」、システム維持のための活動全般を総称した「タスク」など、さまざまに解釈されている。
Opsとは何かを知るために、NoOpsに関するこれまでの議論を紐解き、OpsとNoOpsの意味合いを探ってみたい。
NoOpsの歴史
DevOpsという言葉が初めて使われたのは、2009年と言われているが、2011年には早くもForrester Research社のレポート(Augment DevOps With NoOps)に「NoOps」という言葉が登場している。
この記事では、DevOpsが「コラボレーションによる効率化」に着目していたのに対して、NoOpsでは「インフラの自動化に着目して手動操作を極力減らし、開発者の成果を最大化する」ことを訴求している。
また同じくForrester Research社のブログ記事には、Opsの介入なしでインフラを利用するIaaSやPaaSをNoOpsの一例として挙げている。さらに2012年にはNetflixのエンジニアのブログで、開発者がOpsの役割もこなす事例が見られる。
一方で、Opsをオペレーターや運用担当者とみなすと、NoOpsという言葉がもつインパクトからOpsエンジニア不要論といった意味合いで曲解され、俗にいう「炎上」するような状況も見られた。
これまでのNoOpsを取り巻く議論から見ると(Opsの捉え方に注意は必要であるが)、おおむねNoOpsは「これまでOpsが行なっていた作業をツールで自動化し、極小化する」という観点では共通しているようである。
NoOps JapanコミュニティがNoOpsの定義を試みているので、以下にその定義を引用したい。
「NoOpsはNo Uncomfortable Ops(システム運用の嬉しくないことをなくす)を目指すための技術、アーキテクチャ、それを実現するための活動を指します。このアプローチの代表例に、コンテナを活用した高回復性設計、DevOpsの活用、モニタリングと構成設定の自動化、SREによるToil削減活動、などがあります」
これは現実的で、非常に納得感のある定義である。
NoOpsへのアプローチ
ここからはNoOps Japanコミュニティによるアプローチの代表例から、注目すべきプラクティスを2つ紹介したい。
1つは、自動化・効率化によるOpsの負荷軽減など、戦略的な対応として実施する「SREによるToil削減活動」である。もう1つは自動化しやすい環境整備、運用が発生しないアーキテクチャを目指し戦術的な対応として実施する「コンテナを活用した高回復性設計」である。
SREによるToil削減活動
ここでは、SREとToilについて順に説明し、「SREによるToil削減活動」とはどういうことかを説明する。
NoOpsを目指して自動化を推進していく手法の1つとして、SRE(Site Relia bility Engineering)という考え方がある。もともとはGoogleが提唱・実践しているシステム管理とサービス運用の方法論であり、GoogleではSREを 「class SRE imp lements DevOps」と表現している。
DevOps、SREをJavaでのコード開発に見立て、DevOpsをインターフェースと見るならば、SREはより具体的な振る舞いが定義されたクラスであり、DevOps実践の具体的な一手法と捉えられる。
SREは、Googleのもつ圧倒的な規模のシステムに対するOpsを最適化するノウハウをまとめており、SREを実践するエンジニアはSRE(Site Reliability Engineer)と呼ばれる。
一方、Toilとはサービスを稼働させることに直結する作業で、反復的であり手動で実行されるものを指す。またToilは、「サービスのサイズやアクセス量など、サービスやシステムが拡張するにつれて増加するようなタスクを含む」という特性も備える。よってシステムのスケールを考えた場合、できるだけToilは少ないほうがよい。
従来のシステム運用では、システムの安定稼働を命題と考え、できるだけシステムへの変更を加えないという考え方があった。これに対してSREでは、稼働中のシステムであってもToilに分類される作業が特定されたならば、自動化によってできるだけ排除しようとするスタンスをとる。これらの作業を行うのが、SREにおける「エンジニアリング」である。
SREの業務は、以下に大別される。
①ソフトウェア・エンジニアリング:コードの作成・修正など(設計・ドキュメンテーション含む)
②システムズ・エンジニアリング:本番システムの設定・変更など(モニタリングのセットアップ、ロードバランシングの設定)
③Toil
④オーバーヘッド:事務作業、ミーティング、トレーニングなど
②システムズ・エンジニアリング:本番システムの設定・変更など(モニタリングのセットアップ、ロードバランシングの設定)
③Toil
④オーバーヘッド:事務作業、ミーティング、トレーニングなど
Googleでは、ある期間を通して平均した場合、「全体の作業のうち最低でも50%をエンジニアリングの作業に充てる必要がある」としている。つまりシステム運用の効率・品質をエンジニアリングで改善することでToilを最低限に抑え、全体の労力を将来的な発展のためのエンジニアリングに費やそうという作業が、「SREによるToilの削減」の本質である。
コンテナを活用した高回復性設計
次に「高回復性設計」といった設計思想からの視点と、「コンテナ」を軸とする周辺技術の発展を捉え、両者がNoOpsにどのように結びつくのかを説明する。
「コンテナを活用した高回復性設計」はそもそも、「運用が発生しないアーキテクチャ」を目指した対応であると記述した。この「運用が発生しないアーキテクチャ」とはどういうことか、NoOpsの定義を参照しながら読み解いていきたい。
従来のシステムは、専用化された比較的高価なサーバーで構成されており、いかにシステムを落とさずに安定稼働させるか、という堅牢性を重視した設計に主眼が置かれていた。
しかし、システムが停止した場合は初期対応時から、問題の切り分けや復旧作業など人手を介す必要があり、対応に比較的時間がかかっていた。
一方、近年は機器の性能向上と低価格化、あるいはクラウドへのシフトにより分散処理が加速し、システムの構成要素が増えたことで機器の故障や不具合の確率も上がり、システムの故障を前提として設計を行うように変遷している。
つまり障害の発生を前提として、それに対処可能な設計が求められているのである。
さらにNoOps JapanコミュニティによるNoOpsの定義では、「NoOpsを実現するためのシステムが備えるべき代表的な能力には、高い回復性、可観測性、構成可能性、安全性の担保があります。これらNoOpsの能力を活用することで、たとえばSelf-Healing、In-Flight Renewing、Adaptive Scale、Safety Everywhereなどのエクスペリエンスを実現することが可能になります」と続く。
NoOpsの定義が示すように、障害への対応、復旧作業までも自動化することで、システムが高い次元での回復性を備えることが可能となる。
この回復性の実現には、システムが観測可能で異常を検知できること(可観測性)、さらにその状態を分析したうえで正常な状態に再構成できる必要がある。また負荷に応じたリソースを追加・削減し、これらの構成変更をサービスの稼働に影響を与えることなく、無停止で行う必要がある(構成可能性)。
こうした対応を意識することで、最終的には以下のような特性を備えたシステムを構築できる。
・自己回復性(Self-Healing)
・無停止更新(In-Flight Renewing)
・自己最適化(Adaptive Scale)
・無停止更新(In-Flight Renewing)
・自己最適化(Adaptive Scale)
つまり「運用が発生しないアーキテクチャ」とは、「障害への対応、復旧作業までもが自動化された、高い次元での回復性を備えているアーキテクチャ」と捉えられる。この構造を表現したのが、図表1である。
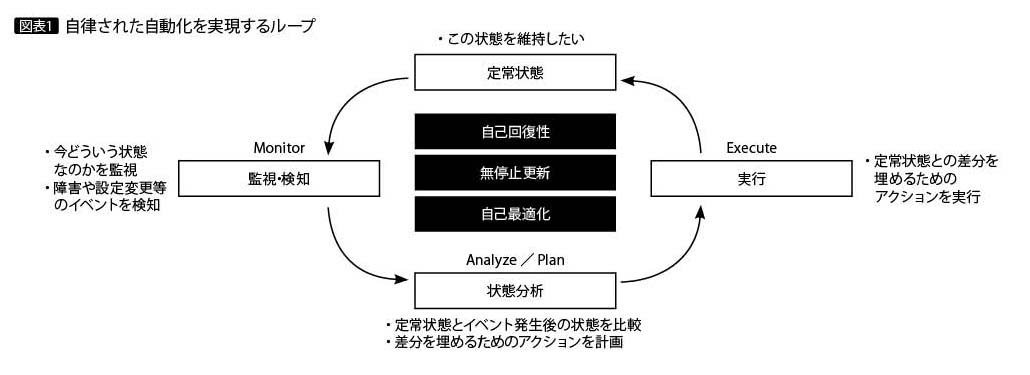
余談であるが、この自律型の回復性については、IBMが2005年に公開した「An architectural blueprint for autonomic computing」というホワイトペーパーに、そのモデルに関する記述がある。
ここでは、4つの視点(self-configur ing、self-healing、self-optimizing、self-protecting)でシステムの自己管理を行うコンセプトを紹介しており、Auto nomic managerと呼ばれるコンポーネントが、MAPE(Monitor/Analyze/Plan-Execute)ループを回すことで自律的な管理を実現する、とある。
これは、NoOpsが目指す回復性を備えたシステムの姿と一致する。発表から14年が経過し、ようやくそのコンセプトを実現できるようになったのである。
「コンテナ」を軸とする
周辺技術の発展
ここからは、NoOpsをテクノロジーの視点で捉えてみる。
NoOpsの定義では、「コンテナを活用した」とあるが、コンテナの枠を広げ、コンテナオーケストレーション、さらにはそれを活用するマイクロサービス・アーキテクチャまで視野を広げたい。
NoOpsには、近年注目されているマイクロサービス・アーキテクチャにも共通する概念が見られる。Martin Fowler氏は、自身のサイトでマイクロサービスの特徴を9つ挙げている。このうちInfrastructure automation、Design for failureなど、インフラの構成に関わる作業の自動化や、障害の迅速な検知と自動復旧などは、正にNoOpsが目指すところと同じである。
マイクロサービスは、システムを一枚岩(モノリシック)ではなく複数のサービス(マイクロサービス)の集合体として構成し、サービス相互をシンプルで軽量な手段で連携する手法である。その狙いは、前述した回復性設計により実現される3つの機能とも合致する。
・ サービス全体を止めずに一部を変更する(無停止更新)
・ 障害やパフォーマンス問題の影響を極小化する(自己回復性)
・ サービス個別の保守やスケールアウトを実施する(自己最適化)
・ 障害やパフォーマンス問題の影響を極小化する(自己回復性)
・ サービス個別の保守やスケールアウトを実施する(自己最適化)
さらにこの特性を、コンテナオーケストレーション・プラットフォームであるKuber netesの機能と照らし合わせてみる。Kubernetesは、CNCF(Cloud Native Computing Foundation)が管理するオープンソースのコンテナオーケストレーション・システムであり、多くのクラウドプロバイダーやソフトウェアベンダーがブランド化したサービスやプロダクトを提供している。
Kubernetesが提供する主要な機能と、NoOpsが求める特性は見事に合致している(図表2)。
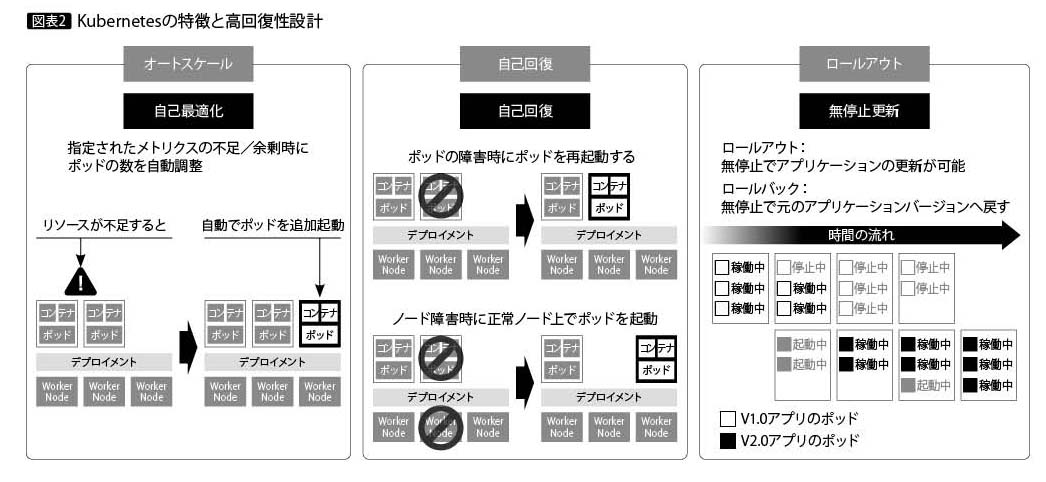
さらにKubernetesの特徴として、あるべき姿を宣言し、その姿に収束させる「宣言的な設定」がある。Kubernetesでは、内部コンポーネントの各コントローラが、それぞれの定義を確認し、現状と把握したうえで、宣言された状態との差分を埋めるように働く。これは、図表1に示される自律的な自動化の実装と言える。
また近年注目を浴びているのが、Kubernetesが提供する「オペレーター」と呼ばれる機能である。オペレーターとはその名が示すとおり、運用担当者が日常的に実施している作業(アプリケーションのバックアップ/リストア、アプリケーションコードの更新と同時に行うデータベーススキーマ、追加の設定修正など)のノウハウをコード化し、Kubernetesのエコシステムに組み込むための仕組みを提供する。
これは、Opsが行うオペレーションをコード化し自動化することでOpsの負担を減らすものであり、有効活用することで、まさに「Toilの撲滅」に直接的に貢献する。
このようにNoOpsのコンセプトは、マイクロサービス・アーキテクチャからコンテナオーケストレーションなどの実装レベルまで、一貫して確認できる。
さらに、近年はServerless computingも普及している。Serverless computingは、サーバーの管理が不要で、コードをデプロイするだけで実行可能な処理形態であり、まさにNoOpsの具現化とも言える。
しかし独特の実装方式や制約から、真に有効活用するにはある程度のノウハウの習得や習熟が必要とされるコンピューティングスタイルと言えよう。
アプリケーションのユースケース、処理形態とServerless computingの特徴が合致するようなケースでは、非常に有効なNoOpsの実現手段となる。
これからのOps
ここまで自動化によるNoOpsの推進を解説してきたが、これらの自動化を推進する体制や文化もまた重要である。
SREによるNoOpsの実践について前述したが、こうした体制の確立は非常に重要である。近年はSRE実践の事例も多く見聞きするが、これらの事例はいずれもITサービス事業会社のように、内製で推進体制を確立しているケースがほとんどである。
その一方、比較的規模が大きい企業では、開発や運用を外注することも多い。こうした体制でのDevOps、NoOpsは、組織が分断されているうえに、それぞれの利害関係の対立が発生しやすく、1つのチーム/組織体としての実践が困難であると思われる。
この体制からDevOps、NoOpsをいかに実践していくか、実践可能な組織体制へとどのように変革していくかは大きなチャレンジになる。このような体制を、SREを参考に変革していくのか、もしくは前提として受け入れ、独自のSRE、NoOpsを追求していくのか。技術的な問題よりも文化・組織の問題こそが、今解くべき課題なのかもしれない。
著者|
太田 智之氏
日本アイ・ビー・エム システムズ・エンジニアリング株式会社
クラウド・アプリケーション
シニアITスペシャリスト
クラウド・アプリケーション
シニアITスペシャリスト
1999年、日本アイ・ビー・エム システムズ エンジニアリングに入社。WebSphere製品テクニカルサポート、Webシステムインフラ構築、Webアプリケーション開発などを経て、近年はクラウド、マイクロサービス関連のソリューション開発に従事。剣道三段。

[IS magazine No.26(2020年1月)掲載]