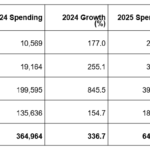
画像認識技術にはさまざまな手法があるが、本稿では昨今注目されている深層学習を用いたソリューションに着目して解説する。まず画像認識の概要と深層学習による画像認識の手法について簡単に触れ、実際のIBMソリューションを紹介する。
画像認識の課題
画像認識にはさまざまな定義があるが、本稿では「画像処理の技術を用いて、画像を理解・認識し、有意な情報を取り出すこと」とする。画像の理解・認識の代表例として、物体認識と物体検出がある。
物体認識
物体認識とは、画像中に写っている物体が何であるかを識別・分類することである。識別の粒度には、一般的なカテゴリ(人、犬、猫)での認識や、具体的な個体名や製品名での認識がある。
物体検出
物体検出とは、前述した物体認識による物体の識別に加えて、物体が画像のどこに写っているかを特定することである。
以下に画像に写っている犬の識別を例に、物体認識と物体検出による画像認識の難しさについて説明しよう。
画像から犬を物体認識により識別する際の難点として、図表1のように、同じ「犬」であっても多種多様な犬種が存在すること、色や犬のポーズによっても多くのパターンが存在することが挙げられる。

また識別する物体以外に、画像の環境にも注意が必要となる。画像を認識する場合、認識したい物体、つまり犬だけが大きく鮮明に写っているとは限らない。たとえば、犬が写っている角度や大きさ、画像の背景や犬の飼い主の写りこみなど、認識を困難とさせる要素は多々あり、それらを考慮する必要がある。
このように1枚の画像として見た場合でも、画像のもつ情報量は多い。さらに画像認識を目的に機械学習を利用する場合、画像認識の精度を上げるには多くの画像が必要となり、結果として膨大なデータ量を扱わねばならない。
深層学習を利用した
画像認識のメリット
近年、画像認識の分野で深層学習を使った手法が注目されている。深層学習について説明する前に、まず機械学習について簡単に触れておこう。
機械学習にはさまざまなアルゴリズムがあり、その1つがニューラルネットワークである。ニューラルネットワークは、図表2のように人間の脳神経の仕組みを模した機械学習アルゴリズムであり、ニューロンと呼ばれる脳の回路に似たユニットで構成される。ニューラルネットワークの予測モデルは、複数のニューロンを組み合わせた入力層、中間層、出力層で構成される。この中間層を増やし、層を深くしたのが深層学習である。層を増やすことで、従来のニューラルネットワークに比べて表現力と精度が大きく向上している。深層学習は、機械学習の1分野であるニューラルネットワークを発展させたものである。
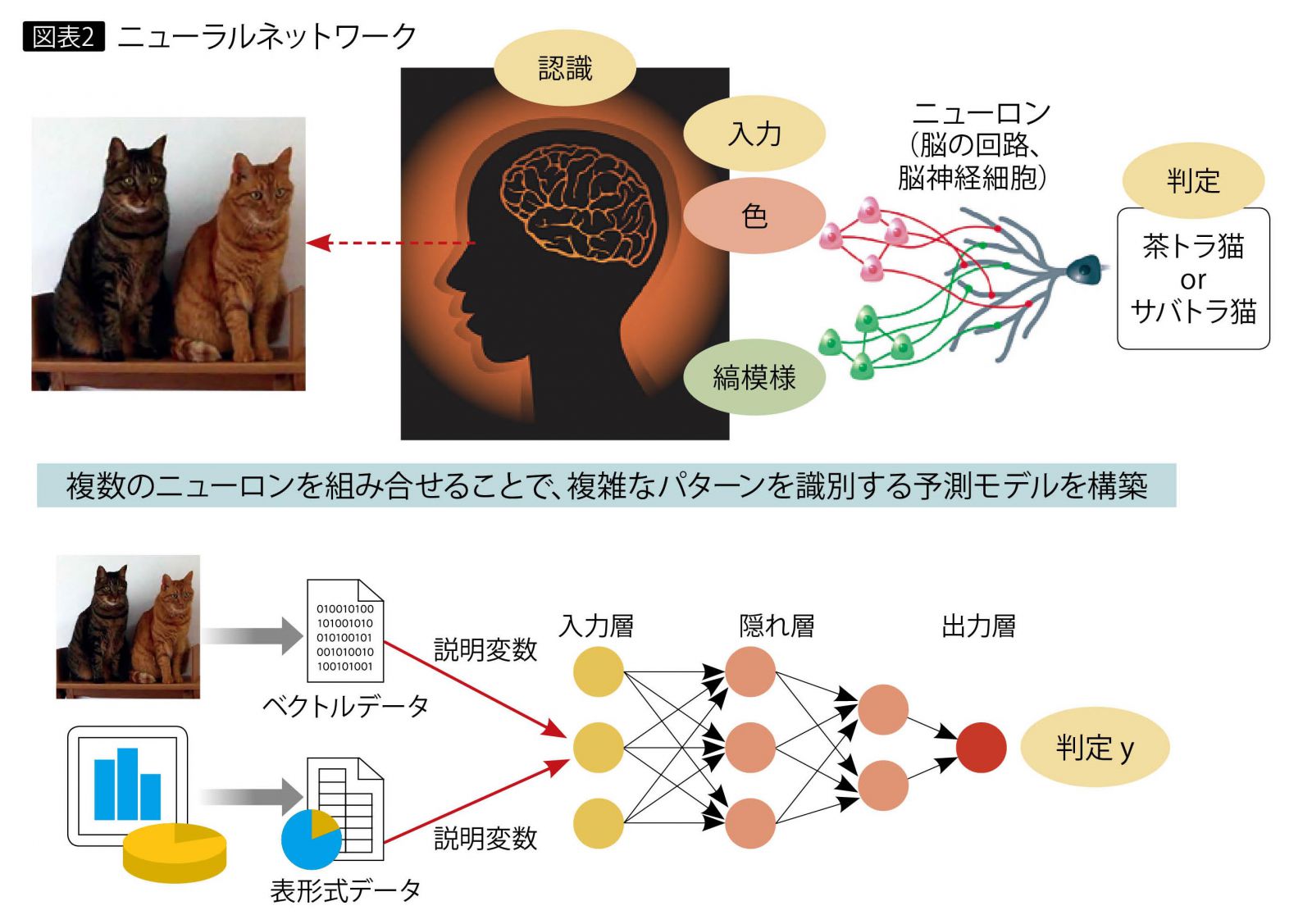
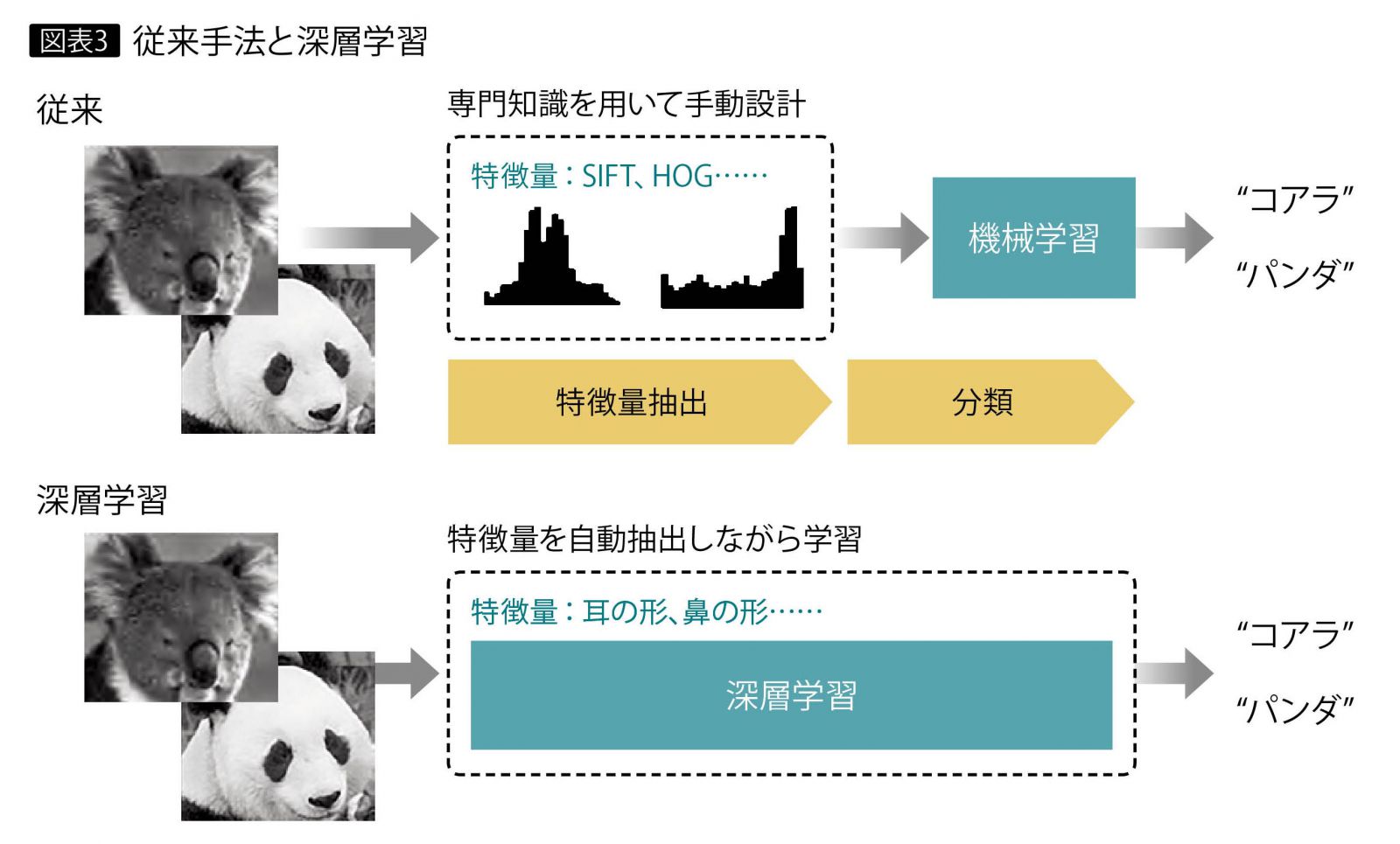
従来手法と深層学習の違い
物体認識を例に、従来手法と深層学習の違いを説明しよう。物体認識を従来の手法で行う場合、最初に画像データから特徴量と呼ばれる数値データを抽出し、その特徴量を機械学習によって分類する。
ここで問題となるのが、特徴量を抽出するための設計、すなわち「どのような特徴を抽出するか」を決める作業に膨大な工数の手作業を伴う点である。しかし深層学習では、特徴量の抽出に教師データ(画像)を与えることで、どのような特徴で分類すればよいかを学習していく。多様な特徴を使って分類を判断する場合でも、人手を介する必要はなく、ただ学習データを与え続ければよい(図表3)。
IBMでは、このような深層学習を利用した3つの画像認識ソリューションを提供しているので、以下に紹介していこう。
Watson Visual Recognition
Watson Visual Recognition(以下、VR)は、IBM Cloud上で利用可能な画像認識ソリューションである。大きく2つの機能が提供されている。
(1)事前学習することなく、画像に含まれる情報を取り出す
(2)事前に画像データを学習し、独自に画像分類の仕組みを作る
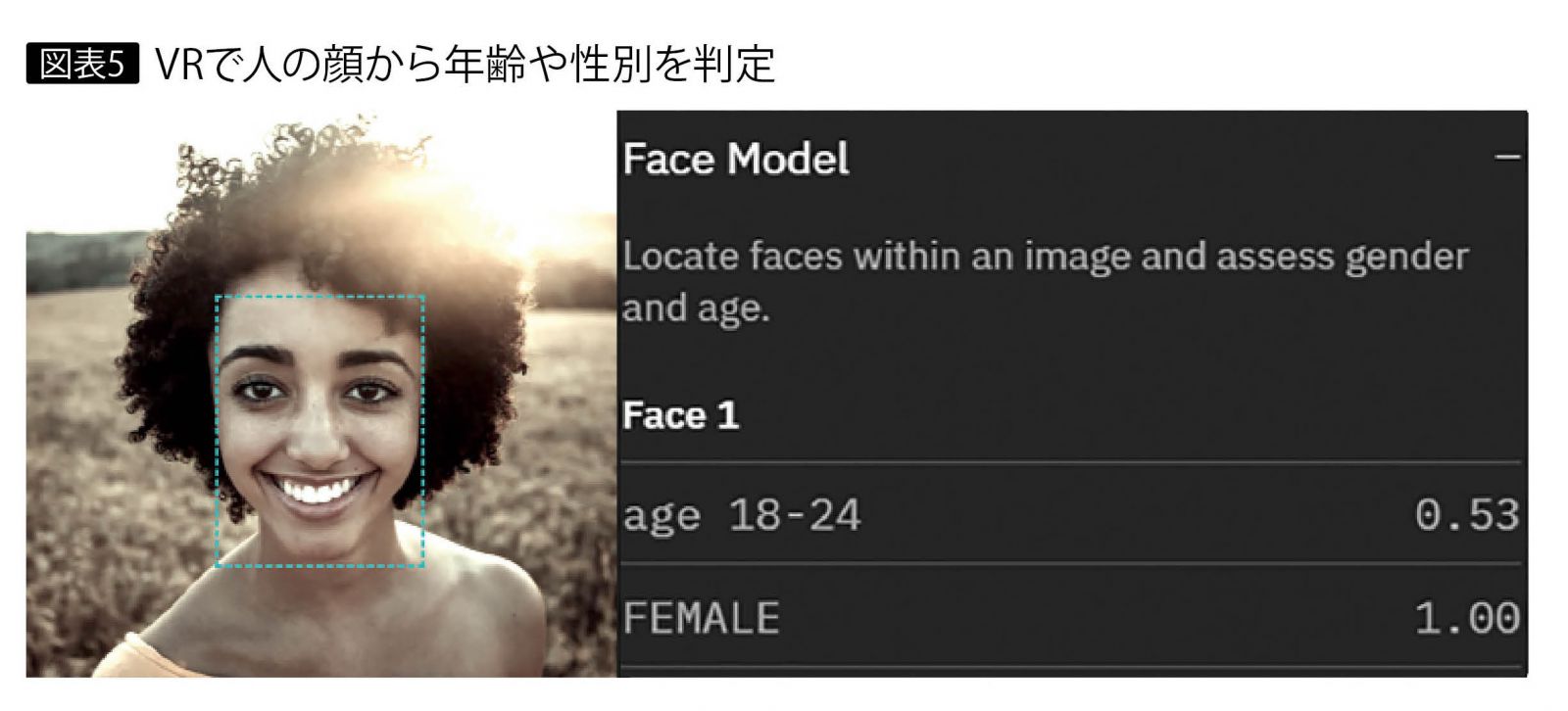
VRでは画像に含まれる物や色を抽出できる。図表4は衣服の画像なので、Fabric(布)が上位に出力されている。ただしこの機能で抽出できるのは、一般名称として存在する物である。さらに、その画像の風景を判別したり、人の顔を認識して年齢と性別を判定したり(図表5)、OCRで英語の文字を読み取る。これらはVRの汎用的な機能であり、デモサイトでも利用できるので、ぜひ試してほしい。

ただし実際の運用は、これほど単純ではない。目的の画像を判定するのに分類器を利用することになる。分類器に必要な画像はユーザーが個別に用意する。
また1つの分類器には、複数のクラスを用意する必要がある。たとえば動物の種類を分類したい場合には、猫の画像を集めたクラス、犬の画像を集めたクラスといったように、分類したいクラスごとに複数枚の画像を用意する。
用意する画像枚数の目安としては、1クラスで100〜200枚程度を目安とすることが推奨されている。枚数よりも、人間が特徴を見分けられ、はっきりと分類できるような画像を集めることが重要である。
VRには、ブラウザからアクセスできる専用GUIとREST APIが提供されている。管理目的では専用GUIを利用し、実際のアプリケーションに組み込む場合にはREST APIを利用する。
さらにVRで作成したカスタムモデルは、iOS上でスコアリングする際に利用できる。これによりクラウドとの通信や、ネットワークが外部に接続していない環境でも、VRの恩恵に与れる。
IBM PowerAI Vision
IBM PowerAI Vision(以下、PowerAI Vision)は、PowerAI上で稼働するオンプレミスの画像認識特化ソリューションである。PowerAIは、IBM Power Systems上でGPUを使って深層学習を実行するフレームワークや、開発用のGUIを提供する。PowerAI Visionは、そのなかでも画像認識に特化した機能を提供しており、VRと同様にプログラミング不要で、モデルの作成からデプロイまでの一連の作業をGUI上で実行できる(図表6)。
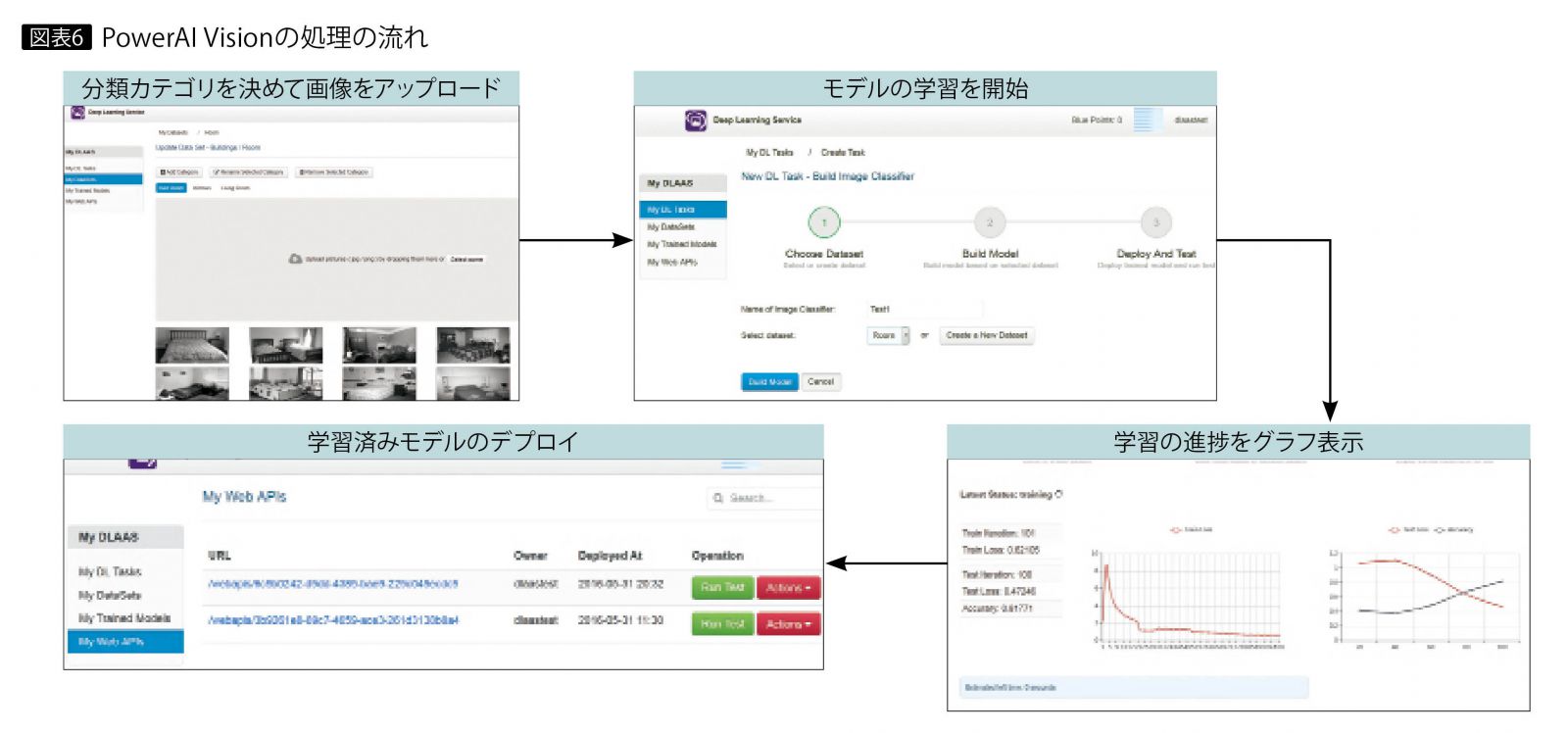
PowerAIの大きな特徴は、学習処理を高速化することである。オンプレミスであるのに加え、NVLinkと呼ばれるCPUとGPU間の通信が、x86サーバーと比べて2.5倍高速である。そのため学習に要する処理を高速化できるので、多くのモデルを作成して、より最適なモデルを用意できる。
PowerAI Visionでは次のような特徴があり、深層学習に関するスキルレベルを問わず、幅広いユーザーが利用可能である。
(1)学習する画像データの整形が不要。物体検出用の画像データについては、GUIを使ってラベル付けする機能が提供されている。つまり画像さえ用意すれば、画像をアップロードするだけで、必要な処理はすべてGUIで作業できる。
(2)PowerAI Visionが、用意した画像に適した判別モデルを学習させるためのニューラルネットワークの構造を自動的に選択するので、深層学習に関する詳しい知識がなくても、精度の高いモデルを作れる。
(3)モデルの学習時に必要なパラメータの推奨値を自動的に設定できるほか、ユーザー自身による設定も可能である。
IBM Visual Insights
IBM Visual Insights(以下、VI)は、製造ラインでの検査工程を画像認識技術で支援することを目的にしたソリューションである。VIは図表7のように、画像認識の運用面全体をカバーできる。
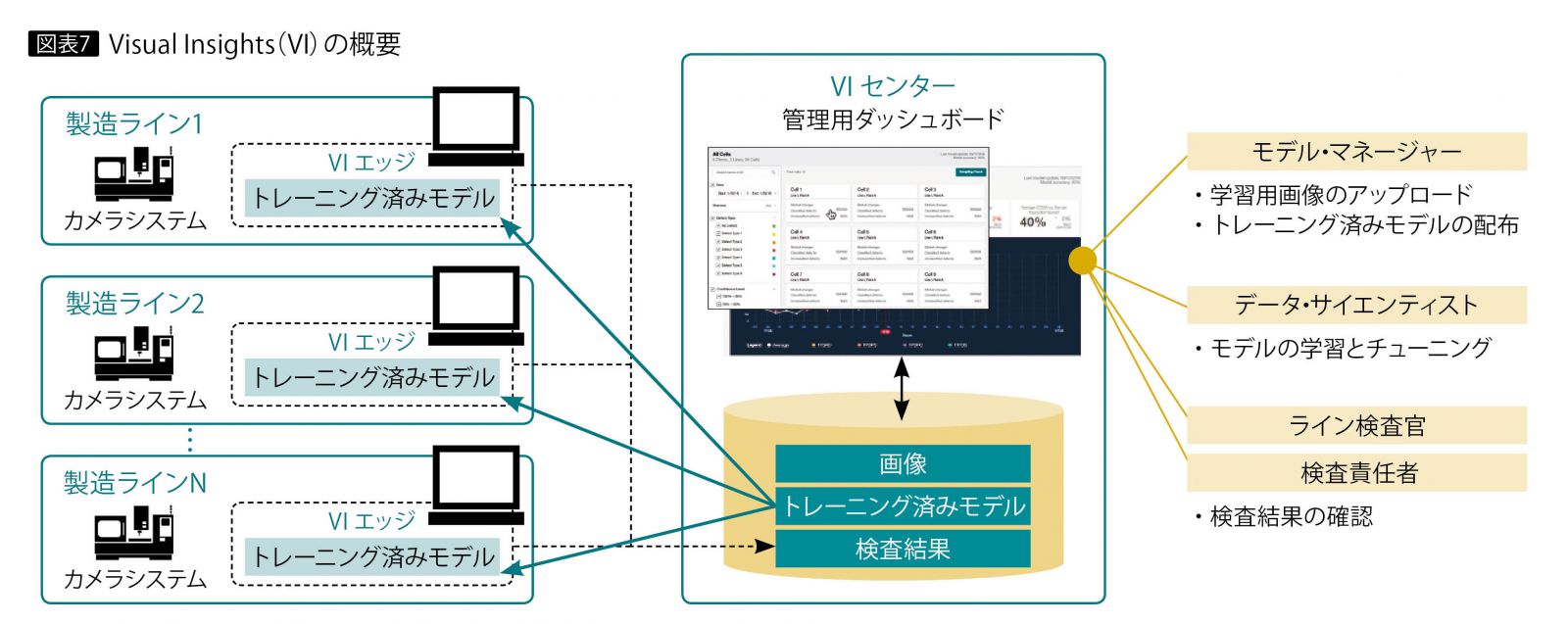
検査工程では検査対象となる物体の検出と、その状態を分類する必要がある。そこでVIでは、物体検出と画像分類のモデルを作成する。検査工程は1つの工場内で複数存在し、それぞれに検査すべき画像の内容が異なる。そのため、検査内容に沿った画像を使ってモデルを作成する必要がある。
さらに製造工場は国内外を問わず複数拠点に設置される場合も多く、どの工場の、どの製造ラインで、どのモデルを使用するか、いつモデルを更新するかといった管理も必要になる。VIは、こういった作業を1つのUIを通して運用する全般的な仕組みを提供する。
実際には「VIセンター」と呼ばれる中央管理サーバーを設置し、それを通じて画像データの登録やラベル付け、モデルの学習や配布など管理する。画像やモデルは、どの工場の、どの製造ラインであるかをメタデータとして管理する。
作成されたモデルを使った判定では、エッジと呼ばれる製造ライン付近のカメラシステムに接続されたマシンで即時実行される。判定された画像とその結果は、VIセンターに送付される。検査員はVIが提供するUI上で、判定結果から問題がありそうな画像だけを絞り込んで確認できる。
VIは目的に合致すれば、製造ラインの検査工程以外でも汎用的に使えるソリューションである。
今回紹介した3つの画像認識ソリューションを使えば、誰でもすぐに深層学習による画像認識を利用できるようになる。どのソリューションも、専門的なデータサイエンティストでなくても、直感的な操作で深層学習モデルを作成できる。要件や目的、環境の条件などに応じて、最適なソリューションを選択することが重要である。
・・・・・・・・
著者|白石 歩氏
日本アイ・ビー・エム システムズエンジニアリング株式会社
IoTソリューション
アドバイザリーIT スペシャリスト

2009年に日本アイ・ビー・エム システムズエンジニアリングへ入社後、Db2の技術支援を担当。近年ではデータ分析基盤の設計構築やディープラーニングでの画像認識技術に携わっている。量子コンピュータの普及活動を展開中。
・・・・・・・・
著者|曽田 俊明氏
日本アイ・ビー・エム システムズエンジニアリング株式会社
IoTソリューション
IT スペシャリスト

2002年に日本アイ・ビー・エムへ入社後、Db2、Replication、Federationなどデータベース関連の製品を専門とし、プロジェクトの技術支援に従事。近年ではIoT、Watson関連のプロジェクトに携わっている。また画像認識技術のプロジェクトにも参加している。
[IS magazine No.22(2019年1月)掲載]