市民データサイエンスとは
昨今のIT技術の進歩と普及は凄まじく、機器の処理能力向上やデータ保存容量の増加により、これまで廃棄されていた多種多様で膨大な業務データを保持できるようになった。
また多くの企業がIoTを使ってさまざまなデバイスからデータを吸い上げ、クラウドにデータを保管するなど新たな試みに着手し、より多くのデータが蓄積している。
それらのデータは、蓄積することが目的ではない。分析することで価値を見出し、意思決定や新たなビジネスの創出に役立てることが本来の目的である。
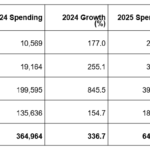
図表1からわかるように、データを蓄積できるようなっても、そこから価値を見出すような高い分析スキルを備える「データサイエンティスト」が世の中には不足している(日本経済新聞 2020年4月28日 )。
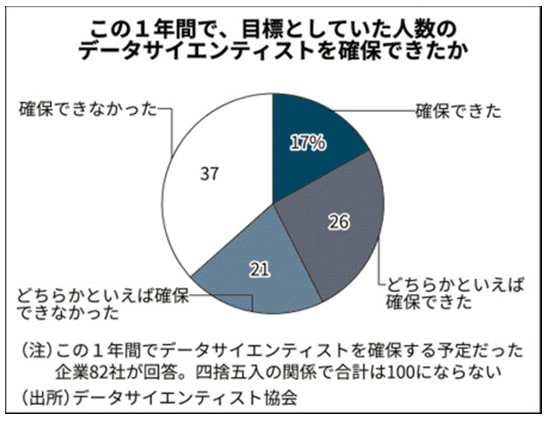
データ分析の需要に対し、データサイエンティスト自体が非常に少ないため、雇用するにもかなりのコストがかかる。しかし高度な分析スキルをもつデータサイエンティストの雇用が容易でないとしても、それを理由にビジネスを止めるわけにはいかない。
この背景を踏まえ、データから得られた知見を業務に反映させていくために、業務ユーザーによる分析活動として、「市民データサイエンス」という新しい概念が生まれた。
市民データサイエンスとは、「統計学や高度な分析手法の知識、専門的なプログラミングのスキルや経験をもたないユーザーであっても、高度なアナリティクスによってデータから洞察を得るための取り組みである」と、ガートナーは定義している。
統計学や分析手法など分析の専門知識をもたない業務ユーザーでも、分析ツールの利用や教育、ユーザー同士の協業など組織的に推進する仕組みがあれば、市民データサイエンティストとしてデータから有益な情報を得ることは可能である。
市民データサイエンティストの強み
市民データサイエンティストが完全にデータサイエンティストの代替になり得るのかというと、そうではない。
データサイエンティストには統計、数学などの学術知識のみならず、機械学習やデータマイニングなどの高いITスキル、問題提起から解決手法の検討・実行までのプロジェクト推進力、コンサルティング能力など、分析業務を計画立案から結果報告まで遂行するための多様な能力が必要である(図表2)。
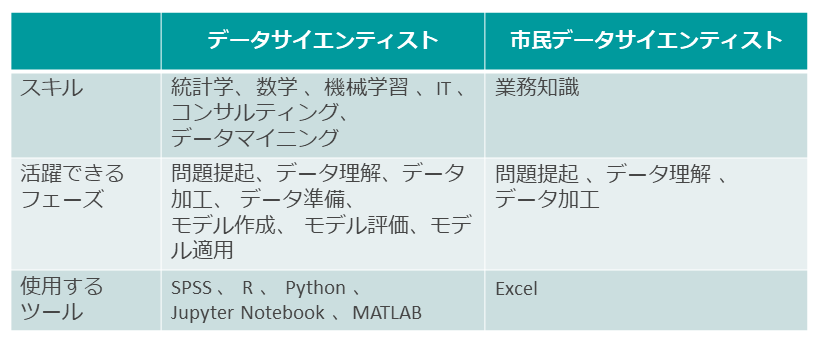
このようにデータサイエンティストになるには、豊富な学術知識と分析知識、スキルが必要になる。市民データサイエンティストとなり得る業務ユーザーは日々、自身の業務を遂行し、それに分析業務が加わる。時間的制約などを考えると、これは容易なことではない。
もちろん分析するには知識やスキルも必要だが、実はそれ以上に業界理解、業務理解、データ理解が重要になってくる。分析対象のデータが何を指し示し、どんな意味をもつのか、データの関係性や利用できそうな関連データがあるか、どのような業務過程で生み出されたのかなど、データの業務的な背景を深く理解する必要がある。
データサイエンティストは分析やプロジェクト遂行の高いスキルをもっていても、膨大で貴重なデータの意味を元から知っているわけではない。
一方で、市民データサイエンティストとなる業務ユーザーは、外部から雇用したデータサイエンティストよりも遥かに深い業務知識をもっている。市民データサイエンティストの強みである業務理解の深さを活かし、データサイエンティストなしで分析業務を成功させることは可能である。
データサイエンティストが分析する際にも、まずはデータの理解から始めるが、実はこの部分は分析を行う上で重要なフェーズであり、とくに時間がかかる。
分析対象と分析目的、なぜ知りたいのか、どのデータが役に立ちそうか、結果によく影響する部分は何か、どのような業務から生成され、それがどんな環境だったかなどを聞き出し、分析結果が出力されてからもなお、より高い精度を追求するためにデータの相関性や結果の信頼性を都度、業務ユーザーに確認する。
これに対して市民データサイエンティストが分析する場合、明確な目的意識や業務の前提知識があるため、データの加工、関連データの収集、特徴量生成やモデル評価、新たな説明変数の追加など、データ理解以外のフェーズに時間を費やせる。そのサイクルを繰り返すことが、より精度の高い結果を導き出すことにつながる。
業務知識だけで分析は可能か
データサイエンティストは効率的に、かつ効果的に分析するために、ある程度決まった分析プロセスに則って進める。
これに対して市民データサイエンティストは、分析に必要な全体のプロセスと、それらの各工程でどのような処理を行うか、つまり各過程で行う処理はどういった意味があるのか、出力結果に対してどのように評価できるのかなどを理解しておく必要がある。
また何を導き出したいか、何を見出したいかなど、目的によって異なるアプローチや分析手法を取る必要があるので、統計知識などの学術的な知識や方法論などは最低限身につけねばならない。
分析プロセスの中には、より精度の高い分析結果を導き出すために何度も繰り返しデータを加工・整形する重要なフェーズがある。
データサイエンティストはSPSSやJupyter Notebook、MATLABといった分析に特化したツールを使用したり、 PythonやRといったプログラミング言語などを用いて分析工程を自動化することで、データ加工・整形の時間を削り、試行錯誤の回数を増やせる。
自由度が高く、分析に特化したツールの習熟を目指すのもよいが、市民データサイエンティストがこの部分を独力で補うのは、時間や経験値を考えると不可能に近い。
そこで経験やスキルが必要なデータ加工から結果出力までを自動化、サポートするツールとして自動AIがある。自動AIは分析対象とするデータを読み込ませることで、特徴量生成やモデル評価まで分析のプロセスを自動化する。
CRISP-DMにおける自動AIの有用度
データ分析は、CRISP-DM(CRoss-Industry Standard Process for Data Mining)という手法に基づいて行われることが多い。CRISP-DMは、以下の6つのフェーズから成り立っている(図表3)。
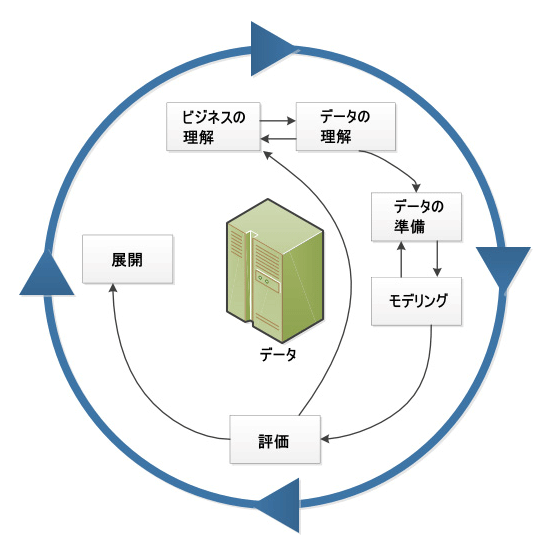
① ビジネス理解
データマイニングのための目標設定を行う。
② データ理解
データ項目、量、品質などの側面からデータマイニングに利用できるデータを調査する。
③ データ準備
分析モデル作成が可能になるように、データの整形作業(クレンジング)を行う。
④ モデル作成
統計的手法、マシンラーニング手法を用いて分析モデルを作成する。
⑤ 評価
作成したモデルが、ビジネス理解で定めたビジネス目標に合致するかどうかを評価する。
⑥ 展開・共有
データマイニングで得られた結果を実際のビジネスに適用する。
ここで、自動AIの機能をWatson AutoAIを例にして挙げてみよう。Watson AutoAIが実現可能な処理には、上記の中の「データ準備」「モデル作成」「評価」がある。
流れとしては、分析に用いるCSVファイルをアップロードしたうえで予測したい列を指定すると、特徴量エンジニアリング手法で自動的に特徴量を生成し、複数のアルゴリズムからモデルを作成する。
その際にはハイパー・パラメータのチューニングも自動的に実行する。作成されたモデルの評価までを自動的に行い、適切と思われるモデルを推奨する。作成されたモデルはWatson Machine Learningにデプロイできる。
一般的にはこれをもって、自動AIにより分析の知識をもたない市民データサイエンティストでも分析が可能になるとされている。ただしCRISP-DMに当てはめると、自動AIでは補いきれない点が存在する。
ここからは、CRISP-DMでの作業をより詳細に掘り下げたうえで、各作業で自動AIがどの程度有用であるかを解説する。自動AIの機能としては、Watson AutoAI(以下、AutoAI)を例に挙げて述べる。
図表4に、CRISP-DMの各フェーズでの作業を詳細に記載した。青色はAutoAIが有用である作業、黄色は条件付きで有用である作業、赤色はAutoAIでは対応できない作業である。
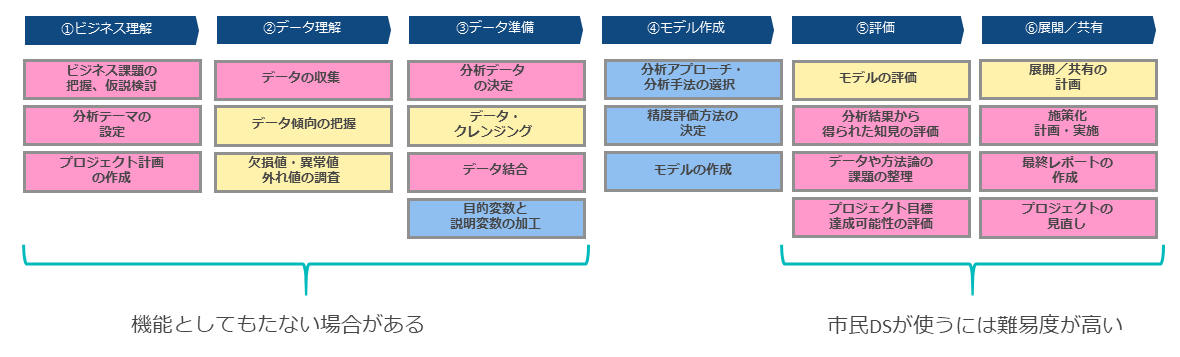
① ビジネス理解
ビジネス理解は業務観点での検討が必要であり、AutoAIでは確認できない。
② データ理解
データはあらかじめCSVで用意する必要があるため、データの収集は別の仕組みが必要になる。一方で、データ傾向の把握や欠損値・異常値・外れ値の調査はAutoAIが自動で行う。
③ データ準備
CSVファイルが複数に分かれるといった場合でも、ユーザー側で結合して1ファイルにまとめる必要がある。一方でデータクレンジングは、AutoAIである程度、自動的に実施する機能を備えている。ただし業務観点から、そのクレンジングが適切かどうかを確認する必要があり、可能であればユーザー側で事前に実施しておくことが求められる。
④ モデル作成
モデル作成では、目的変数列から自動的に適切なアルゴリズムを選定したうえで、ハイパー・パラメータのチューニングも実施しながら、モデル作成まで自動的に行う。ここが、AutoAIの最も有用なフェーズとなる。
⑤ 評価
自動的に作成されたモデルで評価指標を選択したうえで、その指標で最も精度の高いモデルを選択することは可能である。ただし、評価指標の選択はユーザー側で実施する必要がある。たとえば二項分類の場合、再現率を重視するか適合率を重視するかなど、重視する評価指数は業務観点で必ず確認する必要がある。
⑥ 展開/共有
AutoAIでは作成したモデルを自動デプロイすることが可能である。一方で、作成したモデルをどう活用するかといった検討や今後の施策化等は別途検討する必要がある。
このようにAutoAIを用いることで、CRISP-DMの一部フェーズを自動化し、効率的に分析業務を行うことが可能になる。
その一方、AutoAIでは自動化できず、ユーザー側で実施する必要のあるフェーズも存在する。AutoAIをはじめとした自動AIを導入するだけで、即座に市民データサイエンティストが独力で分析できるようになるわけではない。
市民データサイエンティストと自動AI
次に、市民データサイエンティストが自動AIを用いて独力で分析業務を行うための方法を検討する。
まずその前提として、3つの要素が重要であると考える。以下に、各要素とそれらが重要である理由を挙げる。
(1) 市民データサイエンティストが主体となって進めること
データサイエンティストが主体になると、データサイエンティストの代替に留まる。市民データサイエンティストの強みである業務理解を最大限に生かすためにも、市民データサイエンティスト主体で進める。
(2) スモールスタートできること
一般的に市民データサイエンティストは本来の業務タスクもあるので、フルアサインでの参画が難しい。
(3) 市民データサイエンティスト/自動AIの強みを活かすこと
業務知識があり、業務理解に要する時間が少ない市民データサイエンティストが主体となることで、分析プロジェクトをクイックに実施できる。また業務ユーザーが市民データサイエンティストとなることで、データサイエンティストが不足している状況でも分析プロジェクトを立ち上げることができる。
これらの要素を満たしながら、市民データサイエンティストが自動AIにより分析を進めるアプローチとして、以下のように3つのフェーズでの分析が望ましいと考える。ここからは各フェーズについて説明していく(図表5)。
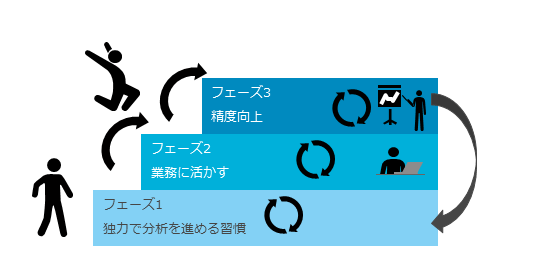
フェーズ1 独力で分析を進める
フェーズ1では市民データサイエンティストが独力で分析を進めることを目指し、精度等を求めず、クイックに分析することを目的とする。
具体的には、CRISP-DMで言うところのビジネス理解では分析テーマの設定のみを行い、業務知識をもつ市民データサイエンティストの強みを活かすために他の作業は実施しない。
データ準備は、CSVとして1ファイルにまとめられたデータから選んで分析対象とする。データ確認は行のズレや文字化け等の最低限の確認に留め、すぐにモデル作成を実施する。評価も自動AIが選択した指標に従って精度が高いものを選び、テスト画面で精度を確認する。
この流れであれば、わずかなワークロードでモデルの作成および確認まで実行できる。
このメリットとしては、自動AIと市民データサイエンティストのみで完結するので、市民データサイエンティストが主体となって分析できる点が挙げられる。市民データサイエンティストが主体となることで、その強みである業務知識を反映していける。またスモールスタートが可能な点もメリットになる。
デメリットは精度が期待できず、モデルを業務に活かすのが難しい点である。これらのデメリットを解消するために、次のフェーズに移る。
フェーズ2 業務に活かす
フェーズ1のデメリットであった精度の低さと業務で活用しにくい点を解消することが、フェーズ2の目的になる。
フェーズ1とフェーズ2の大きな違いは、IT部門などシステム関連の知識をもつ担当者を巻き込む点である。
CRISP-DMの流れに合わせて見ていくと、ビジネス理解とデータ理解を実施しない点は同様である。データ準備については有識者を巻き込むことで、ある程度高度な理解が可能になるため、データクレンジングを実施したり、複数のCSVやDBのテーブル等を結合して、使うデータを増やすようにする。
モデル作成と評価はフェーズ1と同様に、自動AIの判断に従うが、展開/共有ではたとえばWebアプリケーションを開発してユーザーが随時分析結果を確認したり、CSV等でレポーティングされる仕組みを検討して、実業務に活かしていく。
フェーズ2のメリットとしては分析結果を業務に活かせるようになり、かつデータ準備によって精度の向上を見込める点が挙げられる。
また組織の観点からも、IT部門などを巻き込むことで、業務観点で重要な情報は何かをIT部門が認識できる。データ準備をIT部門がある程度主体的に行うことで、ガバナンスを効かせることも可能である。
デメリットとしては、フェーズ1よりは精度が向上するものの、それでもさほど高い精度を期待できない点が挙げられる。
フェーズ3 精度向上
フェーズ2のデメリットとして、フェーズ1ほどではないが、あまり精度を期待できない点がある。フェーズ3ではデータサイエンティストを巻き込むことで、精度向上を目指す。
ビジネス理解およびデータ理解では、業務知識をもつ市民データサイエンティストからデータサイエンティストにスキルトランスファーを実施し、データサイエンティストの業務理解を深めるよう補助する。
その上で、データ準備ではデータサイエンティストの知見を活かした作業を実施する。具体的には説明変数の追加、あるいは外部データを含めたデータ追加を検討する。
また自動AIによって作成された特徴量の妥当性を検証し、場合によっては追加で特徴量を作成する。その上で自動AIによりモデル作成を自動化し、評価についてはデータサイエンティストが業務観点から指標を検討し、適切なモデルを選択する。
作成されたモデルは、フェーズ2で作成した仕組みで展開する。これによって精度のさらなる向上が見込める。
このように3つのフェーズに分ける分析アプローチを取ることで終始、市民データサイエンティストが主体になりつつ分析知識を深め、ボトムアップの分析が進む組織形成を推進する(図表6)。
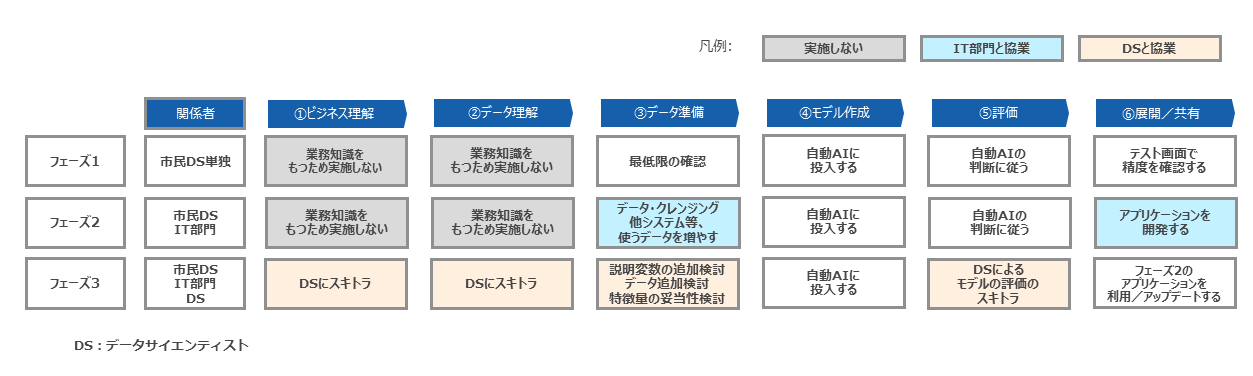
市民データサイエンティストの強みを活かす組織づくり
市民データサイエンティストとして活動する業務ユーザーが、所属する業務部門を軸に分析活動を推進していくことがビジネスの成功につながる。分析活動を進めるための組織体制として、「集中型」「分散型」「ハブ&スポーク型」の3つを例として挙げる(図表7)。
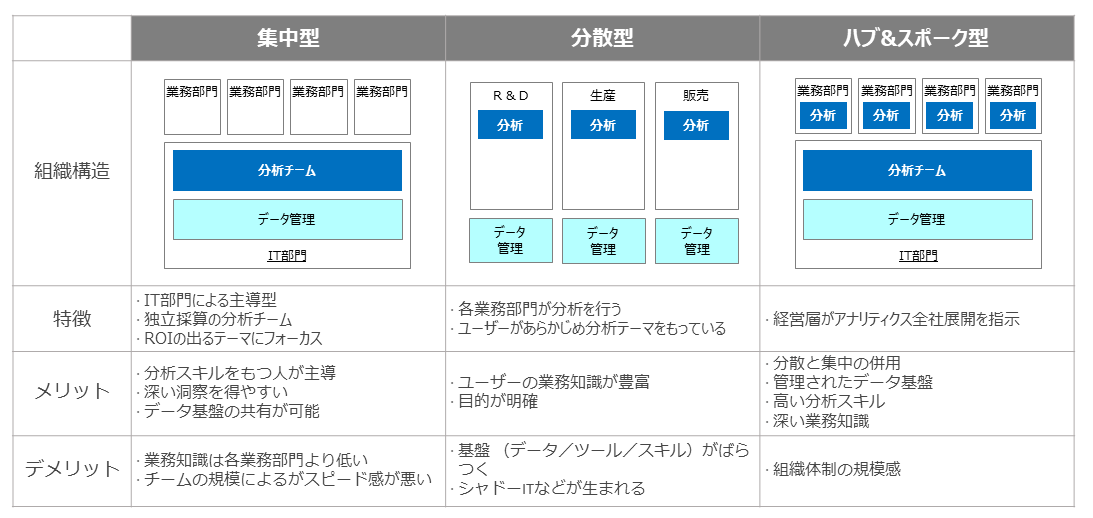
集中型は、ROIが見込めるテーマに対して、IT部門が主導となり分析を進めるトップダウン型の組織体制である。
分析を主導するのは業務部門の担当者ではなく、IT部門やそこに所属するデータサイエンティストであり、業務部門の担当者はあくまで補助的な役割が想定される。
一方で分散型は、各業務部門が主体となって分析することを想定したボトムアップ型の組織体制である。
分析を主導するのは業務部門の担当者であり、前述のような市民データサイエンティストが主体となったボトムアップ型の分析を進めるのに適した組織体制と言える。
ただし分散型のデメリットとして、部門単位で分析を進めることにより、部門間の分析スキルレベルが異なったり、データがサイロ化したり、さまざまなツールの利用によりシャドーITが生まれたりする、すなわち分析基盤のばらつきが挙げられる。
ハブ&スポーク型は、分散型の進め方である業務部門でのボトムアップ型の分析を維持しつつ、IT部による分析基盤の管理、データの一元管理を可能にする組織体制である。
分析チームの力を借りながら業務部門として深い知識を共有し、スピード感をもちながら高度な分析を展開することが可能である。
この体制は、各業務部門と分析チームが協力して作業する。規模感は大きく、この体制を作るには全社的な業務改革が必要になるが、市民データサイエンティストが自身の業務知識を活かし、主体的に分析を進められる体制として、最終的にはハブ&スポーク型を目指すことが理想である。
自動AIを補完する技術要素 XAI
自動AIを用いた分析を実施する上で検討すべき点として「説明可能AI」、すなわち「XAI(Explainable AI)」がある。
XAIとは、作成されたモデルがどのようなプロセスによってその出力結果を得たか、解釈できるようにする技術を意味する。
一般的にはモデルの解釈性と精度はトレードオフの関係にある。たとえば一般的に統計モデルは、解釈性は高いが精度は低い。機械学習モデルは精度は高く出るが、仕組みとしてモデルの中身はブラックボックスであり、解釈性は低い。
解釈性の高いことによるメリットは以下のとおりである。
(1) モデルの精度向上
モデルがどの特徴量を重視しているかを確認し、重要でない特徴量を除去することで精度を向上させられる可能性がある。
(2) 予測の妥当性確認
予測の根拠を明確にし、モデル利用者が予測の妥当性を確認できる。
市民データサイエンティストおよび自動AIの観点では、とくに予測の妥当性確認という点でメリットがある。業務ユーザー観点ではモデルの精度と同様に、解釈性を重要視する傾向があるからだ。
たとえば医療のサポートとして病名を推察するモデルを作成する場合、単に病名の予測を出力するだけでは不十分であり、その病名を予測する根拠が必要になる。
他の例として、製造業での製品の不良傾向をセンサーデータにより予測する場合、不良傾向が高いレコードを特定するだけでは、業務観点でのアクションにはつなげられない。解釈性があって、どの特徴量が影響を及ぼしているかを明確化することで、初めて業務改善につながる。
このように自動AIを導入することで、市民データサイエンティストの活躍の幅は大きく広がる。ただし自動AIはあくまでツールであり、導入すれば終わりではない。
市民データサイエンティストが活躍して、分析結果を業務に活かすことが本来の目的であり、そのための支援を適宜行うことこそが重要である。
著者
近藤 浩嗣氏
日本アイ・ビー・エムシステムズエンジニアリング株式会社
DXセンター Advanced AI
アドバイザリーITスペシャリスト
2013年に入社。Db2/LUWのスペシャリストとして金融業界を中心にサポート。その後は製造業、流通業、官公庁などの案件でアプリケーション開発、インフラ構築、分析業務などに幅広く従事。

高橋 裕大氏
日本アイ・ビー・エムシステムズエンジニアリング株式会社
DXセンター インダストリーソリューション
シニアITスペシャリスト
2014年に入社。自動車業界、保険業界、製造業界、官公庁の案件などに参画。アプリケーション開発案件、インフラ構築案件、分析案件などに幅広く従事。

[i Magazine・IS magazine]