AIの推進は
スピードと簡単さがカギに
AI活用を妨げるハードルは多い。煩雑なデータのタグ付け作業、予測モデルのブラックボックス化、大量の学習データの収集、高度なプログラミングテクニックの獲得、そしてデータサイエンティストの養成など。
あらゆる業界でAIの活用が広がるなか、自社に最適なAIソリューションを実現するには、「スピードと簡単さ」がカギになると、日本IBMの間々田隆介部長(システム事業本部 事業開発 AI推進部)は次のように指摘する。

「AIはよく、『使ったもん勝ち』と言われます。とにかくまず使ってみて、どのようなデータが有効か、どう使うのが適切かを理解し、先に進むことが重要です。それには開発サイクルを短くし、職人のような開発者が丁寧に時間をかけて1つ1つ作り上げるのではなく、誰もが簡単に作れてAIを量産できる環境が必要です。それに向けて現在のAIツールは、自動化・効率化の仕組みを多数搭載しています」
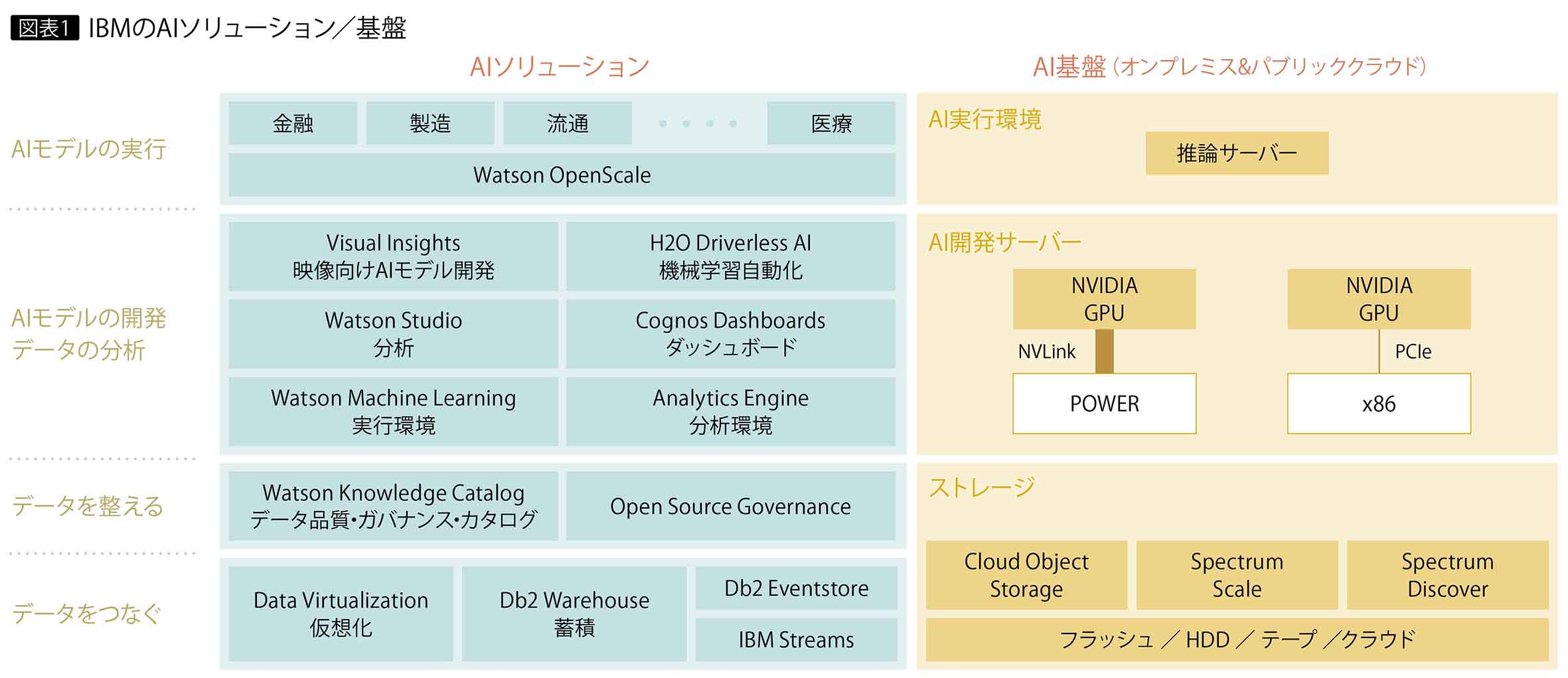
IBMは「デジタル変革 第二章」を掲げ、AIによるデジタル変革(DX)の推進を提唱している。クラウドかオンプレミスかを問わず、インフラから各レイヤのAIソリューションまでを幅広くラインナップして提供する(図表1)。
今回はこのなかから、AIソリューション開発のスピードアップとデータサイエンティスト不要の簡便さに着目し、「IBM Visual Insights」と「H2O Driverless AI」、そしてAI統合開発環境であるWatson Studioで提供されている「AutoAI」の3つを見てみよう。
Visual Insights
画像系AI作成のタスクを効率化
「IBM Visual Insights」(以下、Visual Insights)は2020年3月、PowerAI Visionから製品名を変更した。ディープラーニングを使って、映像・画像認識のAIソリューションを開発するツールで、現在はIBMの画像系AI全般をカバーする位置づけにある。
ディープラーニングの専門知識がなくても、画像分類や物体検出、セグメンテーション、動作検出のためのAIモデルを容易に開発できるのが特徴だ。今まではPower Systemsでのみ稼働していたが、現在はx86系のGPUサーバーにも対応し、オンプレミスからクラウドまでを幅広くサポートしている。
Visual Insightsはデータアップロード、データ前処理、モデル選択、ハイパーパラメータ・チューニング、学習、判別・識別の一連のプロセスを効率化する。対象業務の知見を豊富に備える専門家、いわゆるその領域の達人や匠が、データサイエンティストの力を借りずとも、自らの手でデータを取り込み、モデルの学習を行い、その知見をAIモデル化するプロセスが、ブラウザのGUI操作だけで可能になるよう設計されている。
図表2は、AI画像認識の開発プロセスである。Visual Insightsがサポートするのはデータアップロードから判別・識別までの各プロセス。通常はこれらを何度も繰り返しながら開発するので、このプロセスを効率化できれば、画像系AIソリューション開発の全体的な生産性向上につながる。
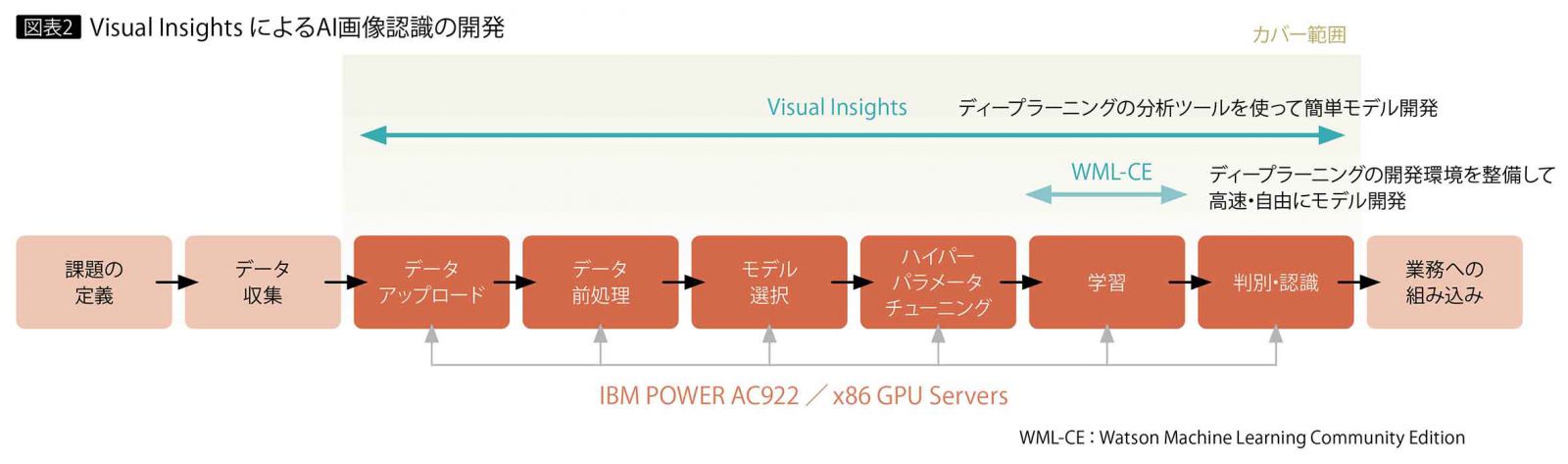
たとえば数回のクリック操作でモデルを学習させ、画像の分類や物体の検出を行う。操作はカテゴリの名前を付けたフォルダに画像をドラッグ&ドロップする、またはタグを付ける物体をマウスで囲むだけ。画像分類では、反応個所をヒートマップで表示するので(図表3)、モデルが特徴量を正しく判断しているかを業務の専門家が一目で確認でき、モデルのブラックボックス化を防いで精度の向上に取り組める。

AI開発で多くの手間と時間を要するのが、学習用データの前準備である。そのためVisual Insightsは少ないデータで学習したAIモデルにより、データセットに自動でラベルを付ける自動ラベル付け機能を備えている。最初の数枚から学習した「弱い学習モデル」に対し、他の学習データで推論した結果をチェックして学習し直せば、残りの大量の画像へさらに精度高く自動タグ付けができるわけだ(図表4)。

一般に作業時間の80%が、学習のためのデータセットのラベル付けを含む事前処理に費やされると言われるので、自動ラベル付け機能はデータ前処理の煩雑さを解消し、大きな工数削減を実現することになる。
またデータ拡張機能を使えば、学習用のデータセットを簡単に増やせる。原画像に対して、ボカシを入れる、色調を変える、回転する、トリミングする、ノイズデータを入れるなどの処理を自動で適用して画像データを増やす。これによりデータ準備の煩雑さを解消する。増幅された画像でもタグの位置は維持されるので、再度タグ付けする必要はない。
こうしたデータセットの作成や推論機能は静止画像だけでなく、動画でも同様にサポートされる。またVisual Insightsにより事前に定義したモデルだけでなく、TensorFlowやPyTorch、Kerasなどのカスタムモデルをインポートすることも可能である。学習済みモデルはREST APIにより他のプログラムと連携し、さらにiOSアプリやエッジデバイスなどにもデプロイして利用できる。
「Visual Insightsでは専門スキルを備えたデータサイエンティストが不在でも運用が可能ですが、AI利用のハードルをさらに下げるため、当社では『ディープラーニング構築支援サービス』により、AI開発プロジェクトをご支援しています」(間々田氏)
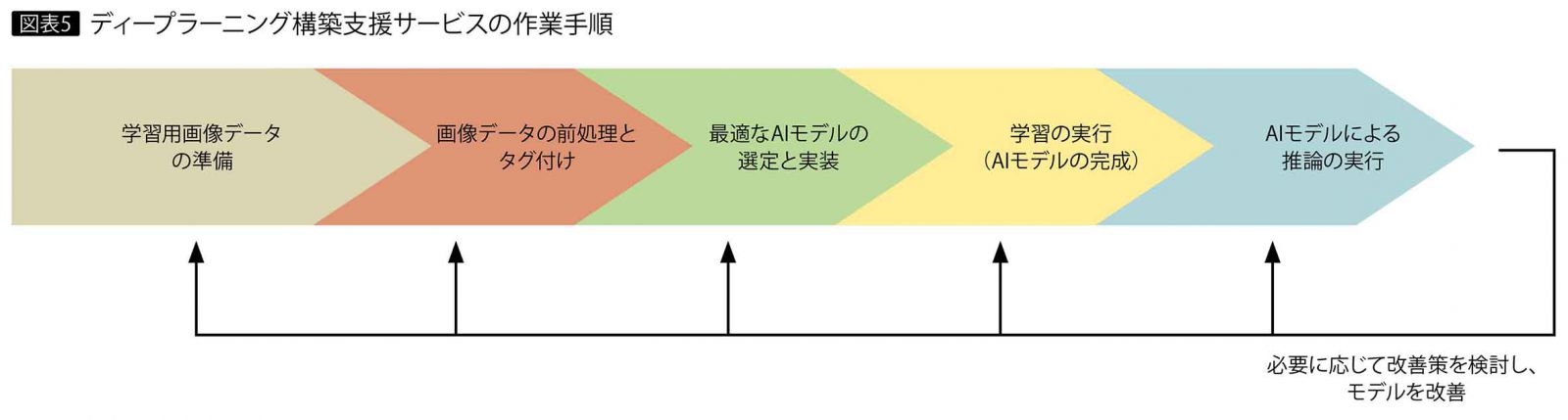
ディープラーニング構築支援サービスは、システム事業本部に所属する、多様なスキルを備えたAIエキスパートが画像や動画を用いたAI検証プロジェクトを支援するサービス(図表5)。すでに40以上の画像認識プロジェクトで実績を上げている。
H2O Driverless AI
文字・数値系の機械学習モデルを自動作成
次に紹介するのが、文字・数値データを学習してマシンラーニング(機械学習)による自動化を図る「H2O Driverless AI」(以下、Driverless AI)である。データサイエンティストが行う機械学習モデルの作成を自動化・高速化する。画像系のVisual Insightsと文字・数値系のDriverless AIは、Power Systems上のAI活用の両輪を担ってきた。
開発元である米H2O.ai(エイチツーオー・ドットエーアイ)社は、2012年にシリコンバレーで誕生した新興企業であり、オープンソースおよび商用のAIプラットフォームを提供している。同社が展開する機械学習ソフトウェアは、世界で約2万の組織・企業・政府・大学などで利用され、フォーチュン500社のうち222社が採用している。なかでも金融系での実績が高く、世界の金融機関トップ10行のうち8行、世界の保険会社トップ10社のうち7社が導入している。
そしてオープンソースの活発なコミュニティからもたらされる、機械学習に関する膨大なフィードバックと高度なナレッジをベースに製品化されたのが、Driverless AIである。
同社は2018年6月に米IBMと業務提携し、IBMはPower Systems上で稼働する機械学習支援ツールとしてDriverless AIの販売を開始した。国内では、2019年10月に日本語版がリリースされている。
数値データや文字データを使って、機械学習で需要予測をモデル化するには、経験のあるデータサイエンティストの存在が不可欠だが、専門的な知識を備えるデータサイエンティストの不足は深刻で、社内での育成にも限界がある。
そこでDriverless AIは、トップクラスのデータサイエンティストだけがもつノウハウをソフトウェア化し、機械学習に必要なモデル作成業務を自動化・高速化している点に特徴がある。
製品名にあるDriverlessは、「データサイエンティスト不要」を意味する。つまりデータサイエンティストと呼ばれるAIの運転者(ドライバー)が不在でも、機械学習による予測分析を自動的に実行するソフトウェアなのである。
トップクラスのデータサイエンティストだけがもつノウハウを反映できる強みの源泉には、世界中のデータサイエンティストが最適モデルを投稿して競い合う、「Kaggle」の存在がある。これは200万人以上のメンバーを擁する世界最大のデータサイエンスコミュニティであり、最も著名なAIのコンペサイトとしても知られる。
優秀なAI人材の宝庫として注目されるKaggleの最上位入賞者であるグランドマスターは、世界全体で180名ほどしかいないが、そのうちの約10%がH2O.ai社に在籍している。そのほかにも220名を超えるAIエキスパートが同社に所属しており、彼らの高度なノウハウをDriverless AIにパッケージ化することで、高速・高精度な機械学習フローの自動化に成功した。
データサイエンティストのノウハウで
特徴量を自動設計
Driverless AIの最大の特徴は、特徴量の自動設計にある。通常、機械学習では図表6のようなライフサイクルに沿って、各種のノウハウが必要となる。たとえば特徴量エンジニアリングでは、機械学習モデルの性能を向上させるため、新しい特徴量の追加、既存の特徴量の変更、不要な特徴量の削除など特徴量を設計する人的作業が発生する。あるいは目的に最適なアルゴリズムの選定、複数のモデルを融合させて1つの学習モデルを生成するアンサンブル学習の手法なども必要だ。
与えられたデータセットから、多種多様なテクニックを駆使して新たな特徴量を設計する作業は、データサイエンティストのスキルや経験、アイデアに依存する部分が大きい。通常は試行錯誤を繰り返しながら、数週間から数カ月の工数を要する。
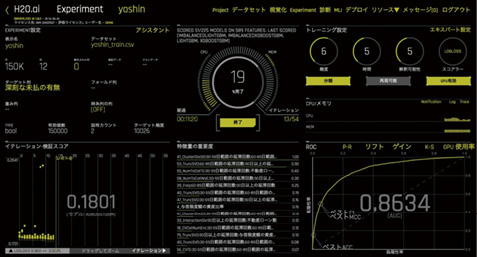
しかしDriverless AIではこれらのプロセスをすべて自動化しており、ユーザーは高度なスキルを必要としない(図表7)。実際には「データのアップロード」「ターゲットの選択」「モデルの作成・実行」という3ステップ(3クリック)だけで完了できる。
またアップロードしたデータセットについて、データの関係性などを自動的に視覚化できる点も大きな特徴である。これにより、外れ値、ヒストグラム、相関グラフ、ヒートマップなどでデータを視覚的・直感的に理解し、モデル作成前にデータの概要を把握できる。
予測結果に影響を与えたパラメータを視覚的に解釈することで、特徴量の重要度や使用された特徴量設計のテクニックなど、モデルがどのように決定・判定するかに至った理由を説明し、レポートを自動作成できる点も見逃せない。
「これによりAIのブラックボックス化を防ぎます。監査レポートなどでAIの判定理由を開示できる点は、Driverless AIが金融系で多く採用されている理由の1つと考えられます」と指摘するのは、日本IBMの岸代憲一部長(IBM Cloud事業本部 IBM Data and AI テクニカルセールス Data Science and AI)である。

さらにバージョン1.7.0からは目玉機能として、「BYOR」(Bring Your Own Recipe)がサポートされた。BYORを利用すると、使用された特徴量エンジニアリング手法や機械学習アルゴリズムを反映したモジュールを、ユーザーがPythonで独自に開発して自由に組み込めるようになる。これらのモジュールは、「カスタムレシピ」と呼ばれている(2020年5月時点の最新バージョンは1.8.6である)。
BYODの機能により、データの加工・分析に関する自社のノウハウや、地域に特化した特徴量生成処理を組み込むなど、ユーザー独自のニーズに沿った柔軟なカスタマイズが可能になる。ちなみにH2O.ai社では、150を超えるカスタムレシピやレシピの書き方、テンプレートなどを無料公開しており、ユーザーは自由に利用できる。
このほか、外部環境でモデルを実行するためのモジュールの取得や、Web API形式でデプロイする機能も提供しており、社内の既存システムや新規システムに機械学習モデルを実装できる。
Driverless AIは回帰分析と分類(すなわち需要予測や不正検知などの予測分析)に特化しており、ワールドワイドでのユーザー事例としては、金融業での不正検知、クレジットカード顧客のリストと購買行動の予測、患者と医者のマッチング向上、不動産市場でのマーケティングの最適化、製造業での需給予測や予知保全などがある。
AutoAI 、Watson Studioの機能として提供
前述した2つの製品と同じく、データサイエンティストの確保が難しい企業でのAI開発に向けて、あるいはデータサイエンティストの業務軽減を目的に開発されたのが、「AutoAI」である。2019年6月に、「Watson Studio」の機能としてリリースされた。
Watson Studioは、さまざまなAIツールを利用できるAI開発プラットフォームであり、事前構築済みモデルの利用を狙いにしたWatson APIに対し、AIのカスタムモデル開発を前提にしている(図表8)。データ基盤である「Watson Knowledge Catalog」、モデル実行環境である「Watson Machine Learning」、モデル運用環境である「Watson OpenScale」などと連携しながら、AI基盤を構成する。

プロセスに応じて個々のツールを使い分けると、連携や管理に手間がかかるのに対し、Watson Studioであれば1つのツールで、共通したGUIにより、データ加工から分析までの全プロセスを一気通貫で実行できる。
また従来のデータ分析では分析者により利用するツールが異なり、チームメンバー間でのコラボレーションが難しいという課題があった。これに対してWatson Studioでは、SPSS Modeler、Jupyter Notebook、R Studioなどデータ分析の標準ツールを一通り揃えているので、どの分析者に対してもそれぞれが使い慣れた環境をクラウド上に用意できるメリットがある。
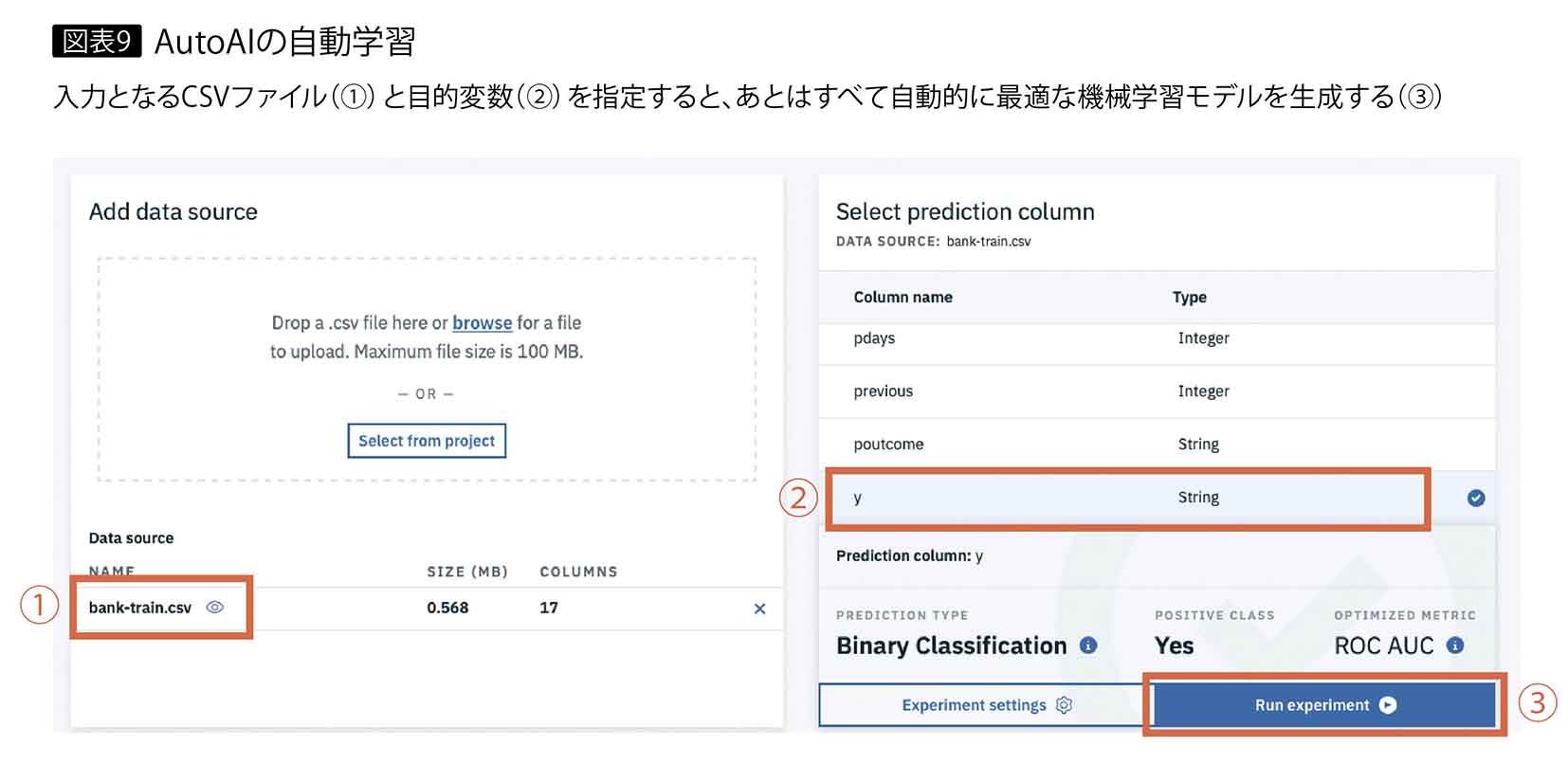
新たにサポートされたAutoAIでは、学習データをCSV形式でアップロードし、マウスクリックで目的変数など数個の指示を与えるだけで、あとは実用に耐え得る精度の機械学習モデルを自動的に構築できる(図表9)。
具体的には海外のIBM基礎研究所に所属するトップレベルのデータサイエンティストたちのノウハウを反映し、従来型の機械学習モデルを対象にデータの前処理、モデルの選定、ハイパーパラメータの最適化、および特徴量の最適化を自動化している。
たとえばデータの前処理では、効率のよいモデル作成に必須の処理となる欠損値の補完、データのエンコードなどを最適な形で自動実行する。
またモデルの選定に関しては、少量のデータから簡易的なモデルを作成し、有力候補のモデルを絞り込む方式を採用している。この方法により、少ない処理時間で効率よく精度の高いモデルを選定できる。候補となるモデルとして、7種類の分類型モデルと8種類の回帰型モデルをサポートしている。
モデルの精度に影響するハイパーパラメータの最適化についても、計算資源を多用しない効率のよい方法で実行している。また特徴量の最適化については、強化学習の仕組みを利用して、精度を最適化する特徴量チューニングを実行する。
AutoAIにより
どこでも学習・予測が可能に
AutoAIの特徴をまとめると、以下のようになる。
まず圧倒的な低価格で、極めて精度の高い機械学習モデルを自動作成できること。
次に、機械学習モデルをどこでも利用できること。AutoAIは製品機能として、Webサービス呼び出しとJupyter Notebook実行の形での予測をサポートしている。
Watson Studioはパブリッククラウドでもオンプレミスでも稼働し、前者の製品名がOpenShiftベースの「IBM Cloud Pak for Data」である。つまりAutoAIで作成したモデルは、OpenShift上で活用できるわけだ。またリポジトリに登録した機械学習モデルを1回のマウスクリックだけでWebサービス化できるので、たとえばPython FlackのWebアプリケーションから、機械学習モデルによる予測をリアルタイムに呼び出すアプリケーションが簡単に作れるようになる。
さらにAutoAIでは、モデルを作るためのコードをJupyter Notebook形式でエクスポートする機能を利用できる(2020年5月時点ではベータ版を提供)。この機能により、Jupyter Notebookの搭載された環境であれば、多様なクラウドサービスを含めて、どこでもモデルを利用できるようになる。つまり「どこでも学習」「どこでも予測」が可能になる。
このほか、AutoAIはWatson Studioの基盤上で提供されているので、他のWatsonツールと容易に連携できる点も大きなメリットであろう。たとえばWatson Open Scaleと連携すれば、自動作成したモデルが「なぜ、どのような判断をしたのか」について、トランザクション単位で分析したレポートを出力できる(AutoAIとWatson OpenScaleの連携は2020年5月時点では、IBM Cloud Pak for Dataでのみ対応)。
「AutoAIは、精度の高いモデルを自動生成するので、データサイエンティストが不在である企業のお客様にお使いいただけますし、データサイエンティストの業務支援やレベルアップにも役立つツールだと思います。機械学習を手軽に試してみたいと考えるユーザーにも最適でしょう。さらにSPSS Modeler Flowと組み合わせて利用することで、データサイエンティストの人材育成にも役立てていただけると考えています」と指摘するのは、日本IBMの赤石雅典氏(ワトソン・テクニカル・セールス エグゼクティブITS)である。

Watson Studioでは機能の1つとして、SPSSの簡易版である「SPSS Modeler Flow」がサポートされている。SPSS Modeler Flowを使用すれば、データの取り込みからデータの変換、モデルの作成、評価までの処理に対応する機械学習パイプラインを、コードを作成せずに、フローチャートを使ってグラフィカルに作成できる。
AIセンター始動
部門水平型組織でAI活用を本格化
日本IBMは2020年2月、ユーザー企業のAI活用の本格化に向けて、AI導入サポートに特化した「IBM AIセンター」(以下、AIセンター)を公開した。
同センターは日本独自の施策であり、2019年12月に発足。2020年1月に社内で準備を整えたうえで、2月に本格稼働を開始した。「Journey to AI」を掲げ、ユーザー企業のAIソリューション活用を目的に全体構想から実装、社内AI人材育成までの各プロセス別に、上記で紹介したツールを含むサービスや製品など約150種類の提案メニューを準備している。それらをユーザーニーズに適した形に組み合わせ、日本IBMの営業部門や各事業部と連携しながら技術やサービスを提供する(図表10)。
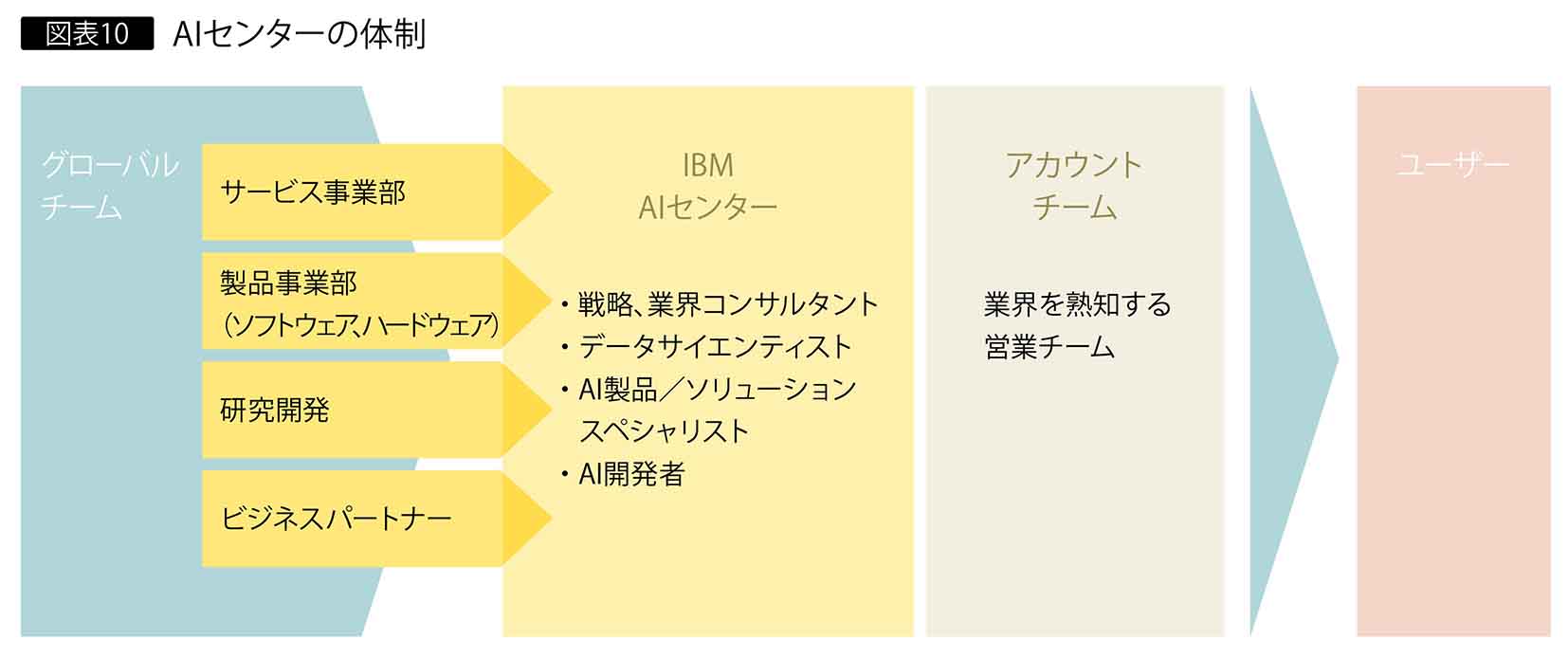
同センターは戦略・業界コンサルタントやデータサイエンティスト、ソリューションスペシャリスト、AI開発者など、部門横断的な組織として各部門の人材が集まっている。日本IBMのすべてのAIソリューションと技術を集結して推進する体制である。
AIに特化した部門横断型の組織体制とAI開発のタスクを自動化するツールは、Journey to AIへの大きな推進力となりそうだ。
[IS magazine No.27(2020年5月)掲載]