デジタルサービスプラットフォーム(DSP)とは
IBMは2020年6月16日、金融サービス向けの「オープン・ソーシング戦略フレームワーク」の中核ソリューションとして、デジタルサービスプラットフォーム(以下、DSP)を発表しました。
DSPは、以下の3つから成り立っています。
(1) 金融業務サービスをマイクロサービスとして提供するABA
(2)金融機関ごとに異なる勘定系へのインターフェース仕様・粒度の違いを吸収するバックエンドアダプター(BA)
(3)これらのアプリケーションおよびフロントサービスの稼働環境であるDSP基盤
本稿では、(3)の狙いについて解説します。
DSP基盤を活用する効果とは
DSP基盤はIBMが大手金融機関でシステムを構築した際の要件とアーキテクチャを基本に、共同化プラットフォームとして運用を効率的に実施するための仕組みを組み込んでいます。
また、Distributed systems are never“up” と言われるように、多数のコンポーネントが複雑に絡み合って構築されるDSP基盤のようなシステムでは、「部分的な障害を絶対に起こさない」というのは現実的ではないので、部分的な障害が全体に影響を及ばさないように回復するよう設計しています。
これらを踏まえて、DSP基盤のアーキテクチャ・オーバービューは、図表1のような形になっています。
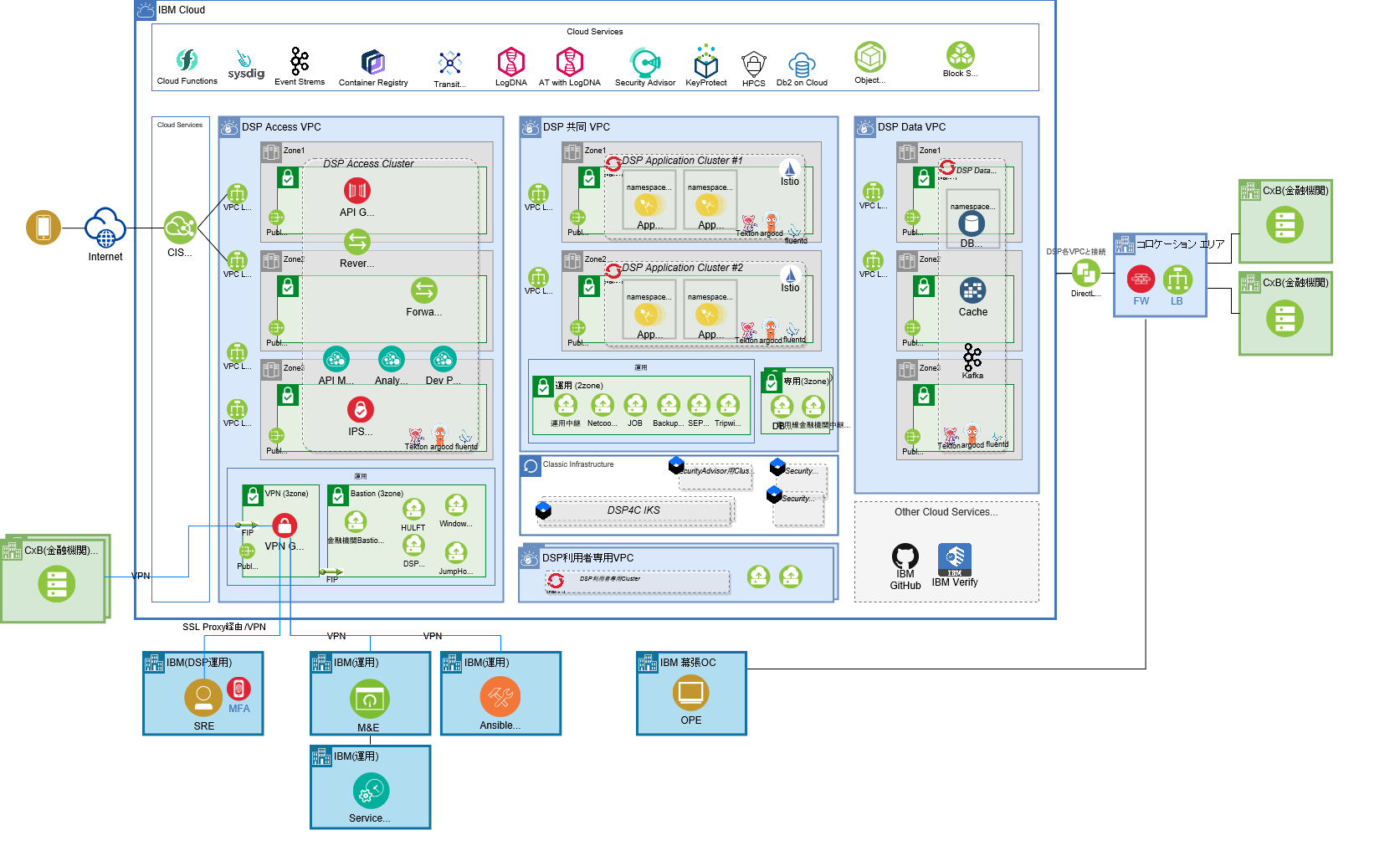
利用する主なプロダクトとサービスをアイコンで示していますが、おそらく従来のエンタープライズ向け開発では利用しないサービスが多いので、アイコンが見慣れないのではないでしょうか。
DSP基盤のプロジェクトチームにとっても、これらのサービスは慣れ親しんだものではありませんでしたが、各サービスに関するPoCを含めた調査を徹底的に実施し、サービスのメリットと制約を把握したうえでシステム設計に落としています。
これにより、高可用性・高セキュリティな基盤を迅速に利用可能とする効果をユーザーに提供できます。
図表1の主なコンポーネントの用途を、以下に簡単に記載します。
1. Sysdig(IBM Cloud Monitoring with Sysdig):監視(メトリクス収集)の実施
各種リソースの使用状況、コンテナの想定しない状況を把握するため、イベント、トランザクションのレイテンシー、トラフィック、エラーを集約。アラートを発生し、オートコールや自動メールなどに連携。
2. Cloud Functions:外形監視用トランザクションの実行
擬似トランザクションを定期的に発行し、レイテンシー、トラフィック、エラーをSysdigに連携。
3. logDNA(IBM Log Analysis with LogDNA): ログ集約
複数のマイクロサービス、コンポーネントが分割して出力するログを集約。検索を容易にする。
4. AT with logDNA(Activity Tracker with LogDNA):Cloudの操作をロギング
Cloudに対する変更を集約。
5. Security Advisor:不正操作の監視
AT with logDNA上のログからルール違反を検知し、アラートを出力。
6. Keyprotect、HPCS:鍵管理
各種PaaSと連携する秘密鍵を管理。
7. Tekton:CI/CDの実現
CI/CDのパイプラインを実行。
8. ArgoCD:GitOpsの実現
OpenShiftの構成ファイル(マニフェスト)をGitHub上で管理し、常に一致させて運用管理(GitOps)するために利用。GitHub上の変更をOpenShiftに動的に反映。
9. Prisma Cloud:侵入検知・防御
コンテナ間の通信を監視。不正な振る舞いを検知し、SOCに連携。
10. IBM Verify: MFAの実現
各種サーバーにログインする際のOTPを発行。
11. Ansible Tower: オペレーション自動化
タイマー起動やエラーメッセージ等に基づき、自動処理を実施
12. Service Now: チケット管理
障害および定常オペレーションをチケットで管理。前述のAnsible Towerと連携。
プラットフォームに対するSLOの計測
次に代表的なユースケースとして、監視をどのように実現しているかを解説します。
DSP基盤は前述のように、コンポーネントがダウンした際の影響を最小限にするために、SREの考え方に基づいて運用設計を実施しています。
具体的にはゴールデンシグナルと呼ばれる、サチュレーション (リソースの使用率とキューイング)、レイテンシー (リクエストの処理時間)、トラフィック (リクエストの要求数)、エラー (レスポンスのエラー割合)の4つをメトリクスとして、SLI(Service Level Indicator)を定義し、満たすべき基準をSLO(Service Level Objectives)として管理しています。
障害発生時の重大度(Severity)もSLOに対する影響をもとに決定するなど、多くの運用がSLOをベースに考えられており、SLIを適切に把握することが極めて重要だと考えています。
3.1. サチュレーションの監視方法
サチュレーションを取得するためのアーキテクチャは、図表2のとおりです。

DSP基盤はコンテナを中心にしたインフラではありますが、仮想サーバーも用途に合わせて存在し、利用している金融機関との接続のために従来型のネットワーク機器も存在しています。
これらの情報も集中的に管理するために、すべての情報をSysdigに集約しています。ネットワークやWindowsサーバーはSysdigのAgentを導入できないため、PrometheusやSNMPのexporterを利用して情報を収集しています。
収集したメトリクスは蓄積して分析実施し、障害を検知した場合にはアラートを発行します。監視項目としては、NodeのCPU使用率やディスク使用率の閾値超過、iowaitの閾値超過といった従来から実施していた項目に加え、CrashLoopBackOff(コンテナの再起動失敗)、Deployment Stuck(稼働しているコンテナが設定より少ない)、Failed to pull image(コンテナイメージの呼び出しを失敗)といったコンテナ環境に特化したイベントを検知しています。
検知されたアラートはNetcoolやM&Eと呼ばれる監視ツールを介し、オートコールやメールを通じてシステム担当者(SRE)に連携されます。一部の重大度(Severity)の低いメトリクスに関しては、Slackを通じて連携しています。
3.2. レイテンシー、トラフィック、エラーの監視方法
DSP基盤ではレイテンシー、トラフィック、エラーは外形監視(Synthetic Monitoring)を実施するために、疑似トランザクションを発生させ、該当トランザクションに対するメトリクスを収集しています。
これを実現するアーキテクチャが、図表3です。

外部からの疑似トランザクションの発生は、IBM CloudのなかでServerlessに該当するサービスメニューであるCloud Functionsを利用しています。外部からアクセスできないネットワーク機器等に対するトランザクションは、Blackbox Exporterの機能を利用し、メトリクスを収集しています。
DSP基盤上で稼働しているアプリケーションが正常に稼働していることを早期に検知するために、Cloud Functionsを用いた外形監視を利用者のアプリケーションに対しても実行し、メトリクスの収集とアラートの発行を実施します。
DSP基盤の今後の展望
OpenShiftに代表される分散システムを取り巻く技術は変化が速く、アプリケーションの生産性やシステムの安定性に寄与する機能が継続的にリリースされています。
DSP基盤はこれらの機能を柔軟に取り入れ、ABAに代表されるDSP基盤上で稼働するアプリケーションの変化に追従するとともに、コストの削減や運用品質の向上を図っていく予定です。
そのための作業の一貫として、TEC-Jのワーキンググループでは検討結果や課題を共有し、他のプロジェクトに参加しているメンバーからのフィードバックを知見として活用しながら、DSP基盤の展開計画に活かしています。
著者
菱沼 章太朗 氏
日本アイ・ビー・エム株式会社
金融第一事業部
シニアアーキテクト
TEC-J Steering Comitteeのメンバー
大手金融機関様を担当するSEとして、お客様のビジネス変革を実現するプロジェクトをアーキテクチャ面でリード。近年はトークンサービスプロバイダーやデジタル通貨の発行などを実現するためにCloudやOpenShiftの技術を活用したプロジェクトに従事している。
このサイトの掲載内容は私自身の見解であり、必ずしもIBMの立場、戦略、意見を代表するものではありません。

・・・・・・・・
菱沼 章太朗 氏は、日本IBMのテクニカル・コミュニティ「TEC-J(Technical Experts Council of Japan)」のメンバーです。
当サイトでは、TEC-Jメンバーによる技術解説・コラムを継続的に掲載していきます。ご期待ください!
TEC-J技術記事:https://www.imagazine.co.jp/tec-j/
![]()
[i Magazine・IS magazine ]