現在、自動運転、スマートフォン、新薬開発など、さまざまな領域で人工知能、コグニティブの応用が進められているが、それとともに「ディープラーニング」(深層学習)と呼ばれる技術が注目を浴びている。ディープラーニングは、ある意味で「人間のように考える」ことができ、昨今の人工知能・コグニティブ・ブームを作り出した1つの要因ともなった技術である。本連載では、このディープラーニングの技術的な概略と代表的な手法およびその実装方法を取り上げる。第1回は、ディープラーニングの基礎であるニューラルネットワークを中心に解説を進める。
思考するアルゴリズム
280手目、黒の投了。全5局で行われたチャンピオン イ・セドルvs人工知能の囲碁対決は、最終戦も人工知能の勝利で幕を閉じた。最終戦績は、人工知能側の4勝1敗で、完全勝利と言えるものだ。勝利した人工知能は、Google傘下のDeepMind社が開発した「アルファ碁」と名づけられた碁の対戦プログラムである。
アルファ碁は、大量の対戦データの学習により、碁の局面とその時に取り得る指し手を評価してスコア化し、シミュレーションによって次の最適な指し手を選択する。アルファ碁の強さの一因は、局面および指し手を判別するスコア精度の高さにあると言われているが、スコアはディープラーニングの技術を用いて算出されている。そのスコアは大量の対戦データから導き出されたもので、囲碁の定石と異なることも多く、対戦を見ていたプロの中には「人間の直感を備えているようだ」と解説する人もいた。この対戦は大きなニュースとなり、ディープラーニングは、人間の思考を凌駕するアルゴリズムとして大きな注目を集めた。
ディープラーニングの応用分野は囲碁のようなゲームにとどまらず、さまざまな領域に及ぶ。最も応用が進んでいるのは、画像認識の分野だ。たとえば、近年さかんに研究されている車の自動運転を取り上げると、その実現には、対向車、歩行者、道路形状など、周囲の状況把握が必須要素となる。そうした場合、人間は視覚を通じて「交差点で対向車が右折しようとしている」「歩行者が横断歩道を渡っている」などの周囲の状況認識を行うが、自動運転では、視覚の代わりにカメラやセンサーによって得られた画像の内容を何らかの方法によって把握する必要がある。その画像内容の把握に、ディープラーニングが用いられ、さまざまな自動車メーカーのテストで、その認識能力が自動運転に大きく寄与し得ることが報告されている(*1)。ここでも、人間のように認識するアルゴリズムとしてのディープラーニングへの期待は大きい。
・・・・・・・・
(*1)「Audi、自動運転成功の鍵はディープラーニングと発表」http://bit.ly/is12_deep001
・・・・・・・・
ニューラルネットワークから
ディープラーニングへ
人間に匹敵する思考・認識が可能なアルゴリズムとして注目を集めるディープラーニングであるが、その技術的なバックグラウンドは、ニューラルネットワークと呼ばれる機械学習手法にある。
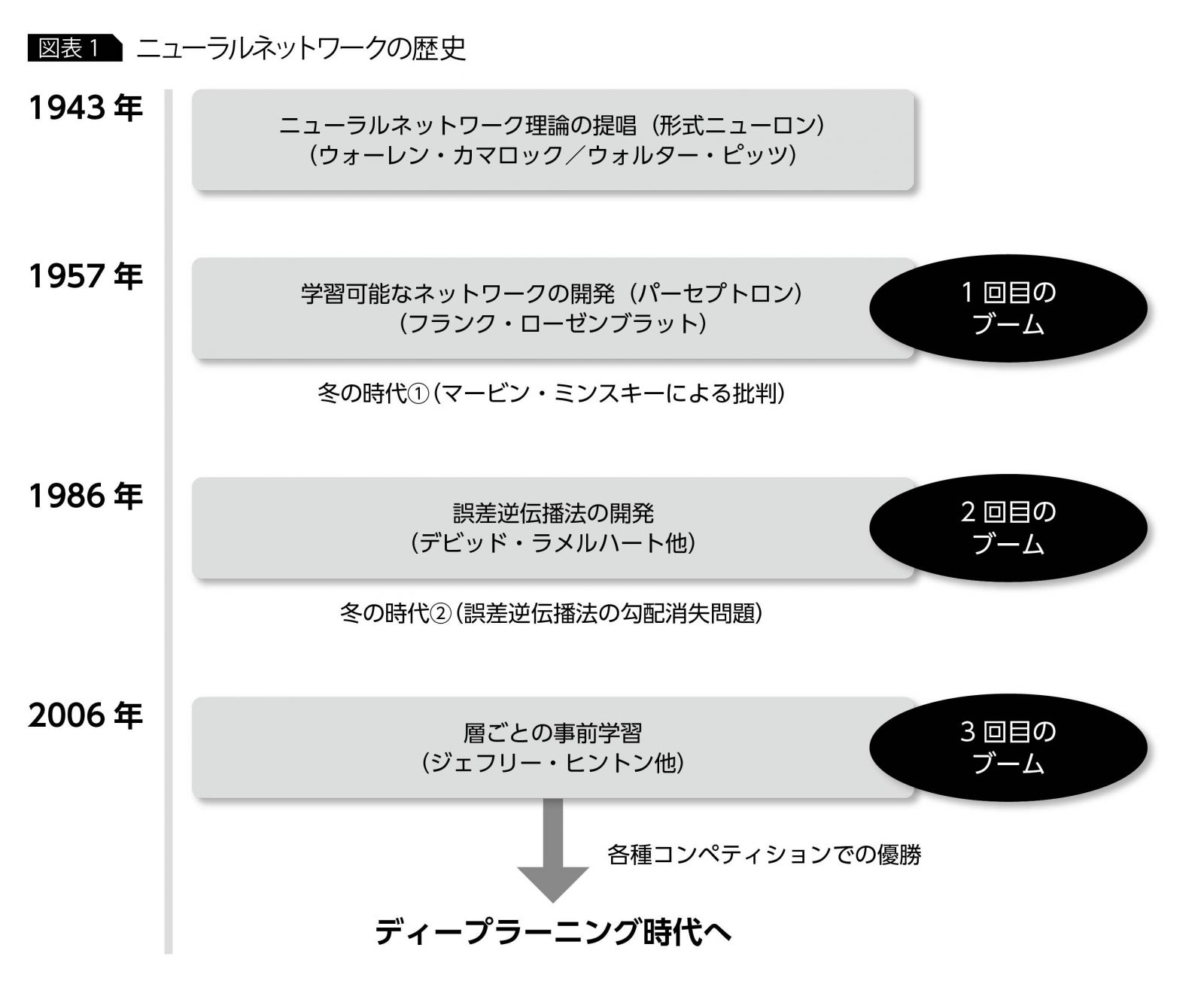
ニューラルネットワークの誕生からディープラーニングへの発展を簡単に振り返ると、その起源は1943年にまで遡る。この年に「形式ニューロン」という人間の脳を模した数理モデルが提唱され、1957年にはデータによる学習が可能な「パーセプトロン」というニューラルネットワークが開発される。パーセプトロンは1960年代に一大ブームを引き起こすが、マービン・ミンスキーにより弱点を指摘され(xor問題)、急速に勢いを失い、冬の時代を迎える。ニューラルネットワークは、何度か、このようなブームと冬の時代を繰り返すが、2006年のトロント大学のヒントン教授による技術革新と、同時期に画像認識コンペティションでの圧倒的な認識精度での優勝という出来事があり、3回目のブームを迎えることになる。この3回目のブーム上で、多層構造をもち、近年の研究成果を踏まえた「畳み込みネットワーク」や「自己符号化器」などのニューラルネットワークがディープラーニングと呼ばれる傾向にある(ただし、ディープラーニングに明確な定義は存在しない)(図表1)。
ニューラルネットワーク概要
ディープラーニングはニューラルネットワークの技術の延長上にあるため、その理解にはニューラルネットワークそのものの理解が欠かせない。ここでは、ニューラルネットワークについての概念的および数理的側面を解説する。
ニューラルネットワークの構造
ニューラルネットワークは、人間の脳の働きを模倣する数理モデルとして提唱された。人間の脳には、千数百億個とも言われる神経細胞(ニューロン)があり(図表2)、この大量のニューロンが連携して電気信号のやり取りによって思考、認識などの処理が行われている。たとえば、「木を認識する」という行為を考えた場合、まず、木から反射された光が人間の目の網膜に到達し、そこで光が電気信号に変換される。この電気信号は、網膜の背後にある視神経に伝達され、そこから脳の視覚野にある神経細胞まで大量のニューロンが電気信号のリレーをすることによって初めて木の認識が可能となる。
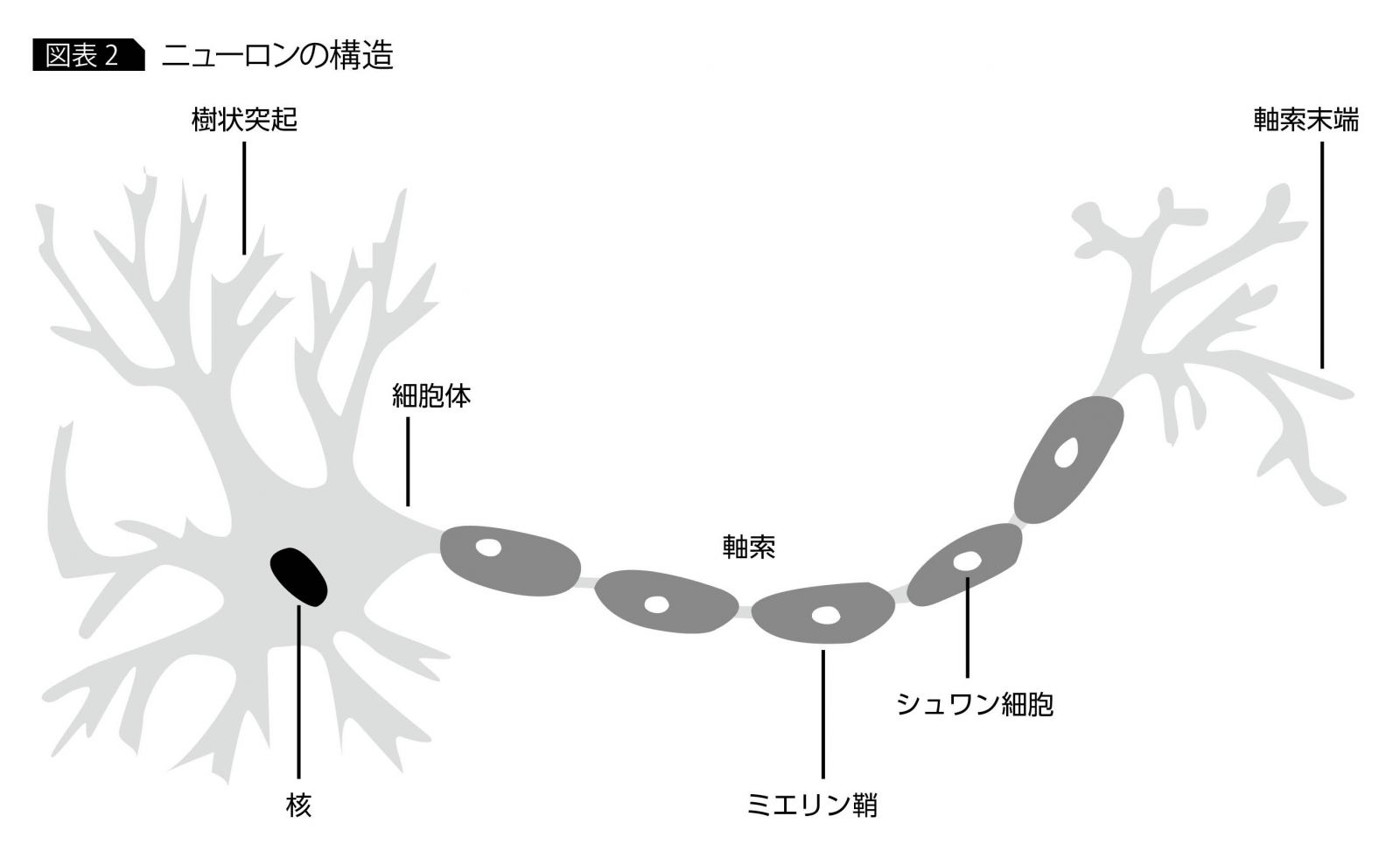
最初に、この電気信号の伝達メカニズムに着目し、その動作と数理モデルを考えてみよう。脳という複雑怪奇な器官の中にあるにもかかわらず、各ニューロンは、比較的単純な動作原理に還元される。個々のニューロンは、電気信号の入力側ニューロンから電気信号を受け取って蓄積し、閾値を超えると、関連ニューロンに電気信号を伝達する。この閾値の超過と関連ニューロンへの電気信号の伝達のことを「発火」という。また、各ニューロンは、入力側・出力側ともに複数のニューロンと接続されているが、その接続のことを「シナプス」と言い、その接続強度はニューロンの組み合わせによって異なっている。これを数理的に表したものが図表3である(1つの○が1ニューロンに相当)。
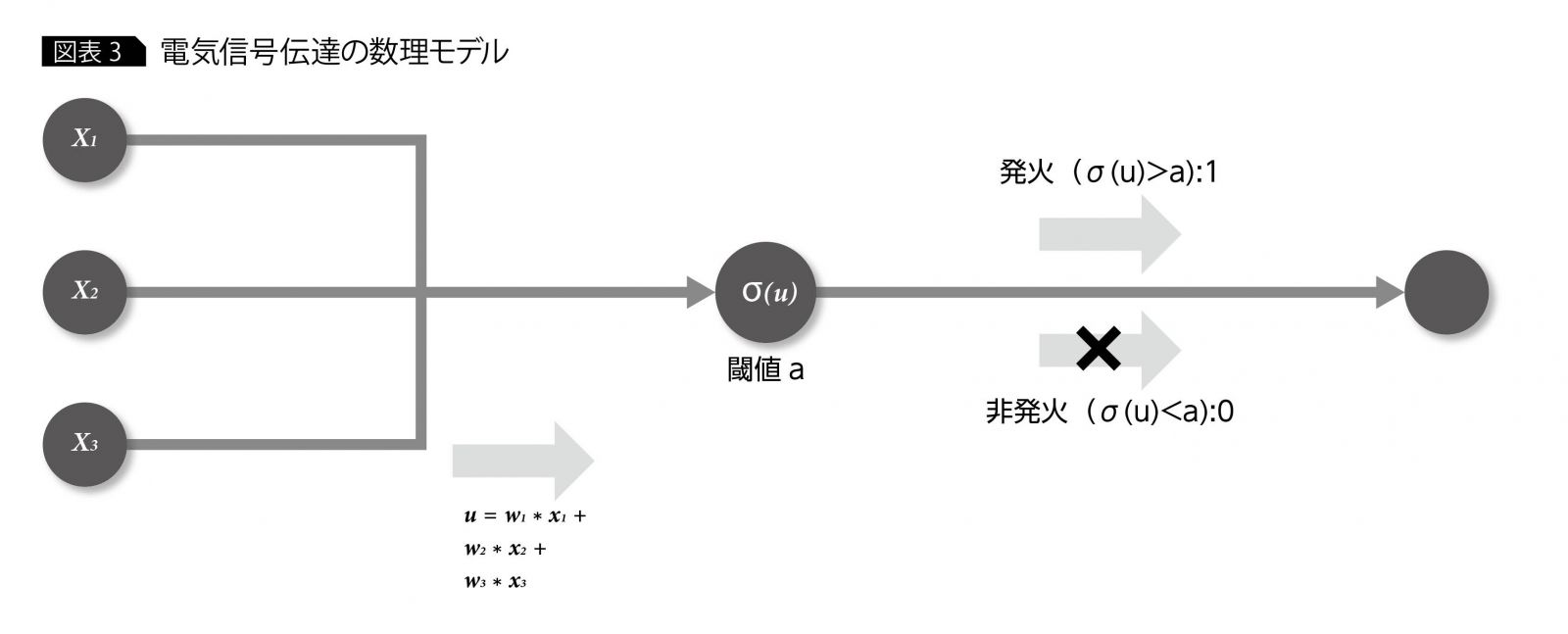
中央のニューロンに着目すると、まず、入力側の3つのニューロンから u=W1*X1+W2*X2+W3*X3 という値を受け取っている。ここで、X1、X2、X3 が電気信号に当たり、W1、W2、W3がニューロン間の結合強度に当たる。つまり、入力側ニューロンの電気信号の強さとニューロン間の結合度合いに応じて、中央のニューロンが受け取る電気信号の値が調整されることになる。
出力側に注目すると、真ん中のニューロンが蓄積した電気量(σ(u))がある一定の閾値aを超えるかどうかによって、1または0どちらかの値が出力される。1が出力される場合が、ニューロンの発火に当たる。ちなみにσは活性化関数と呼ばれる関数でシグモイドやReLUといった関数が使用されるが、ここでは、蓄積した電気量をもとに発火するかどうかを判断する関数と考えて差し支えない。
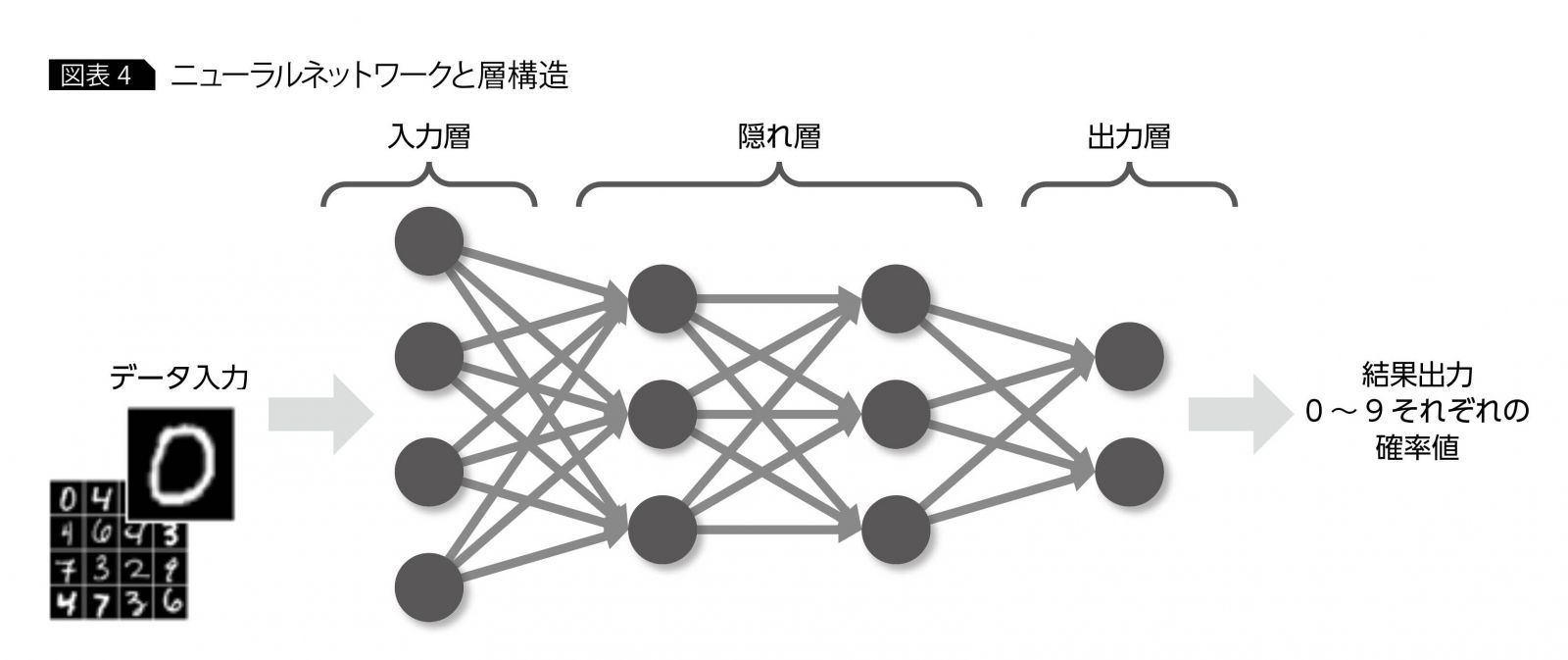
次に、このようなニューロンが多数結合されたニューラルネットワーク全体の構造を見てみよう。ニューラルネットワークは、複数のニューロンがさまざまな形で結合されるが、無秩序に結合されるわけではなく、複数ニューロンが集まった“層”と呼ばれる構造を内部にもつ(図表4)。最初の層は、入力層と呼ばれ、データが入力される層になり、最後の層は、出力層と呼ばれ、結果を出力する層になる。たとえば、 0~9までの手書き文字画像を判別するニューラルネットワーク”を考えてみると、入力層の各ニューロンは、手書き文字画像の1ピクセルを入力値として取り、出力層は、入力画像が0?9それぞれの値である確率を出力することになる。入力層と出力層の間の層は、隠れ層(または中間層)と呼ばれる。この隠れ層のデザインの自由度は高く、その自由度の高さがニューラルネットワークの優れた表現能力の要因となっている。
ニューラルネットワークの学習
これまで、脳との関連からニューラルネットワークの構造について述べてきたが、実問題への適用を考えてみよう。ニューラルネットワークは、ただ脳の働きをモデル化するためだけに開発されたわけではなく、実問題へ適用されることが前提となっている。実問題への適用は、次の2ステップからなる。
・学習
・推論
学習は、ある問題を解くためにニューラルネットワークをチューニングするステップで、チューニングのためにデータを用いる。一方、推論はチューニング済みのネットワークを使って、回答を出すステップである。
推論と比較して、学習のステップは複雑なので、前述の「0?9までの手書き文字画像を判別するニューラルネットワーク」を題材に少し詳しく説明する。
学習には、0?9までの手書き文字画像とその各々の画像に対する正解のセットを用いてネットワークのチューニングを行う。この時にチューニング対象となるのは、ニューロン間の結合強度を表す“重み”である(正確にはバイアスと呼ばれる値もチューニング対象であるが、重みの一種として考えることも可能なので、ここでは重みで統一する)。学習の根本的な方針は、各画像に対するネットワーク出力値と正解の誤差が小さくなるように重みをチューニングしていくことである(図表5)。
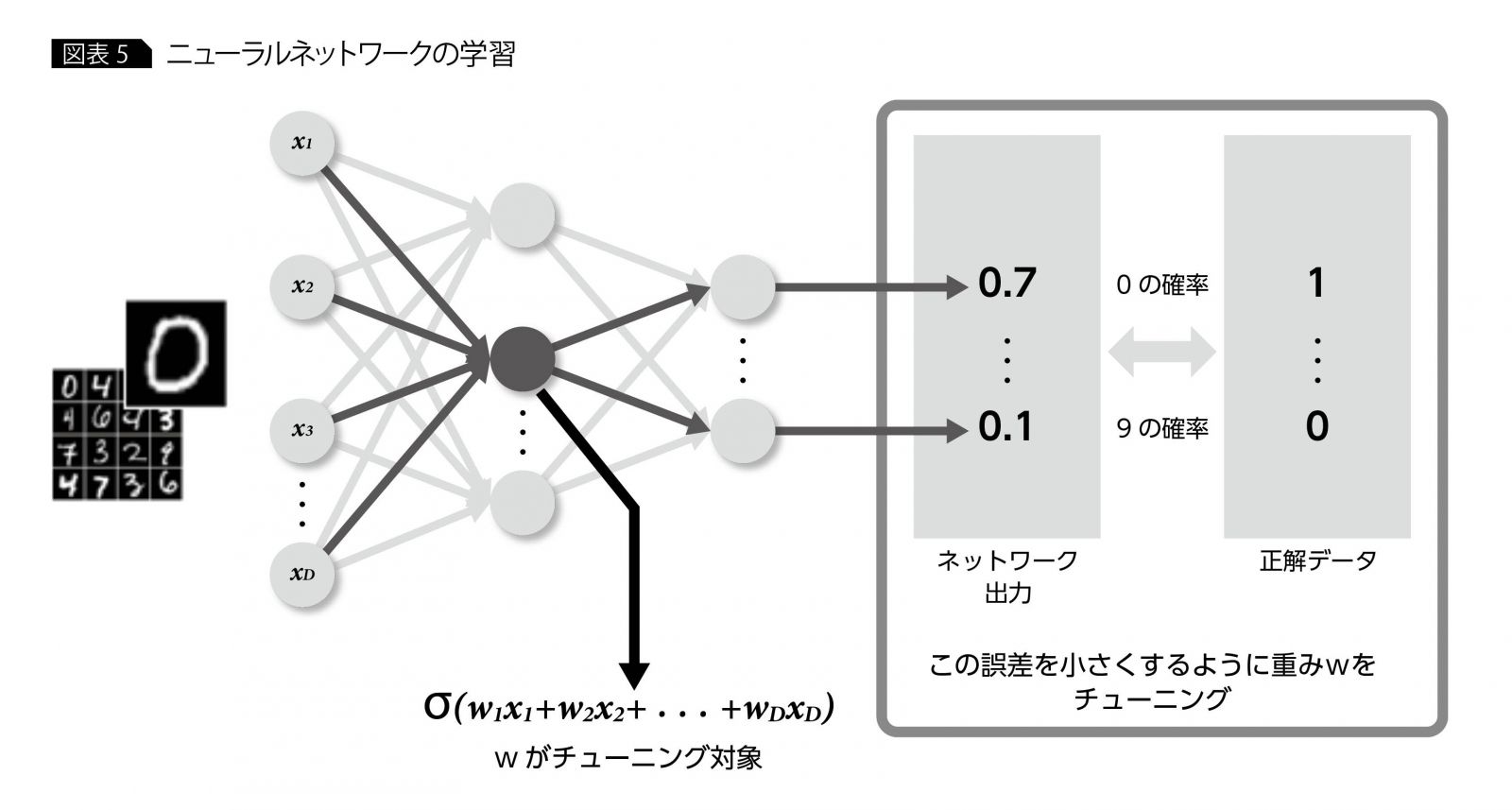
この誤差は数値で表現する必要があるため、ネットワーク出力値と正解の値で計算される誤差関数と呼ばれる関数を定義する。結局、誤差を小さくするように重みをチューニングすることは、誤差関数の値が小さくなるように重みをチューニングしていくことになる。誤差関数は、以下のクロスエントロピーなど、問題に応じて何種類かの代表的な関数を使うことが多い(図表6)。
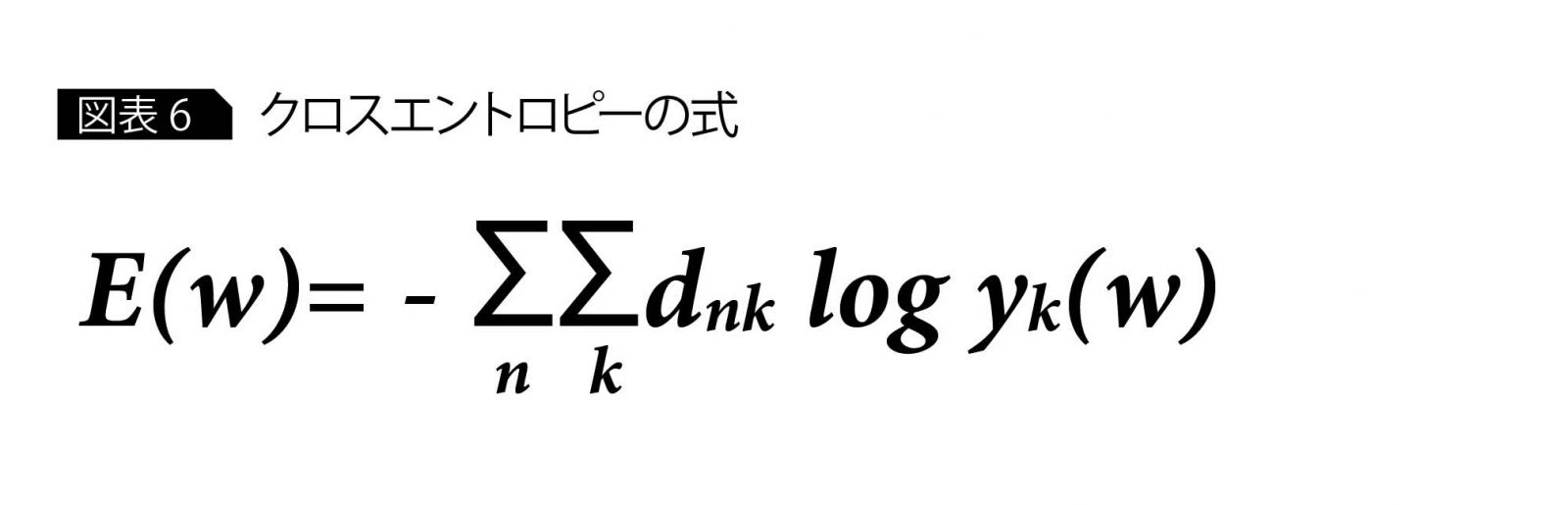
さて、この誤差関数が小さくなるように重みをチューニングしていくことを考える。
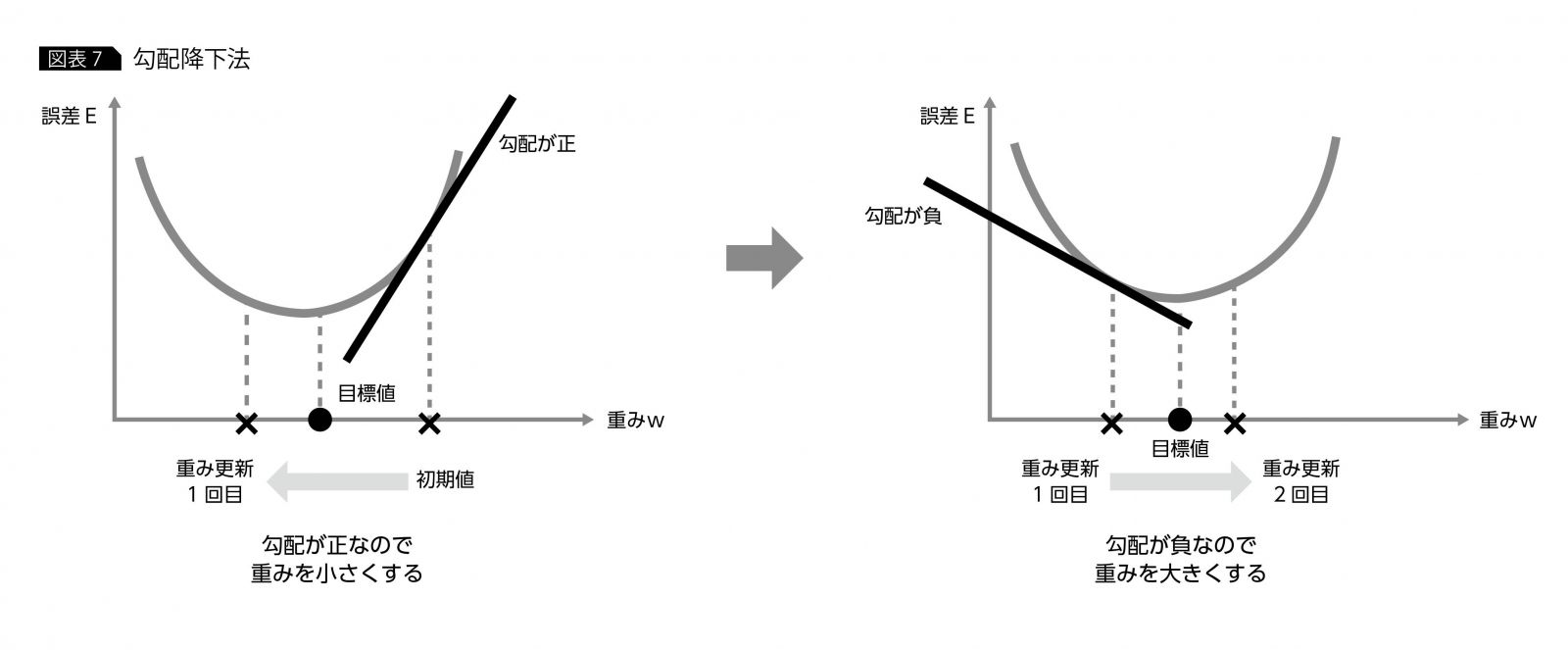
図表6のクロスエントロピーの式の場合だと、誤差関数の値E(w) が最小になるような 重みw を求めればよい。しかし、yk(w) は、かなり複雑な式で明示的に求めるのは困難なので、一般的には、E(w) を最小にするような w の近似値を求めるというアプローチをとる。この近似値を求める際に使われる手法が、“勾配降下法”と“誤差逆伝播法”である。数学的に厳密な説明は省略するが、勾配降下法は、重みw の初期値における誤差関数の勾配を求め、その勾配が正の場合は、重みの値を小さくするように更新し、勾配が負の場合は、重みを大きくするように値の更新を行う。次に、その1回目の更新後の重みにおける勾配を求め、初期値の場合と同様に勾配の正負に応じて、さらに重みの更新を行う。この更新作業を繰り返すことによって、重みを徐々に目標に近づけていく(図表7)。
勾配降下法を使用するには、勾配情報が必要となるが、この勾配を求めるための手法が“誤差逆伝播法”と呼ばれるものである。これは、出力側に近い勾配の値を算出し、順々に入力側の勾配を求めていくことから、逆伝播と呼ばれている(図表8)。
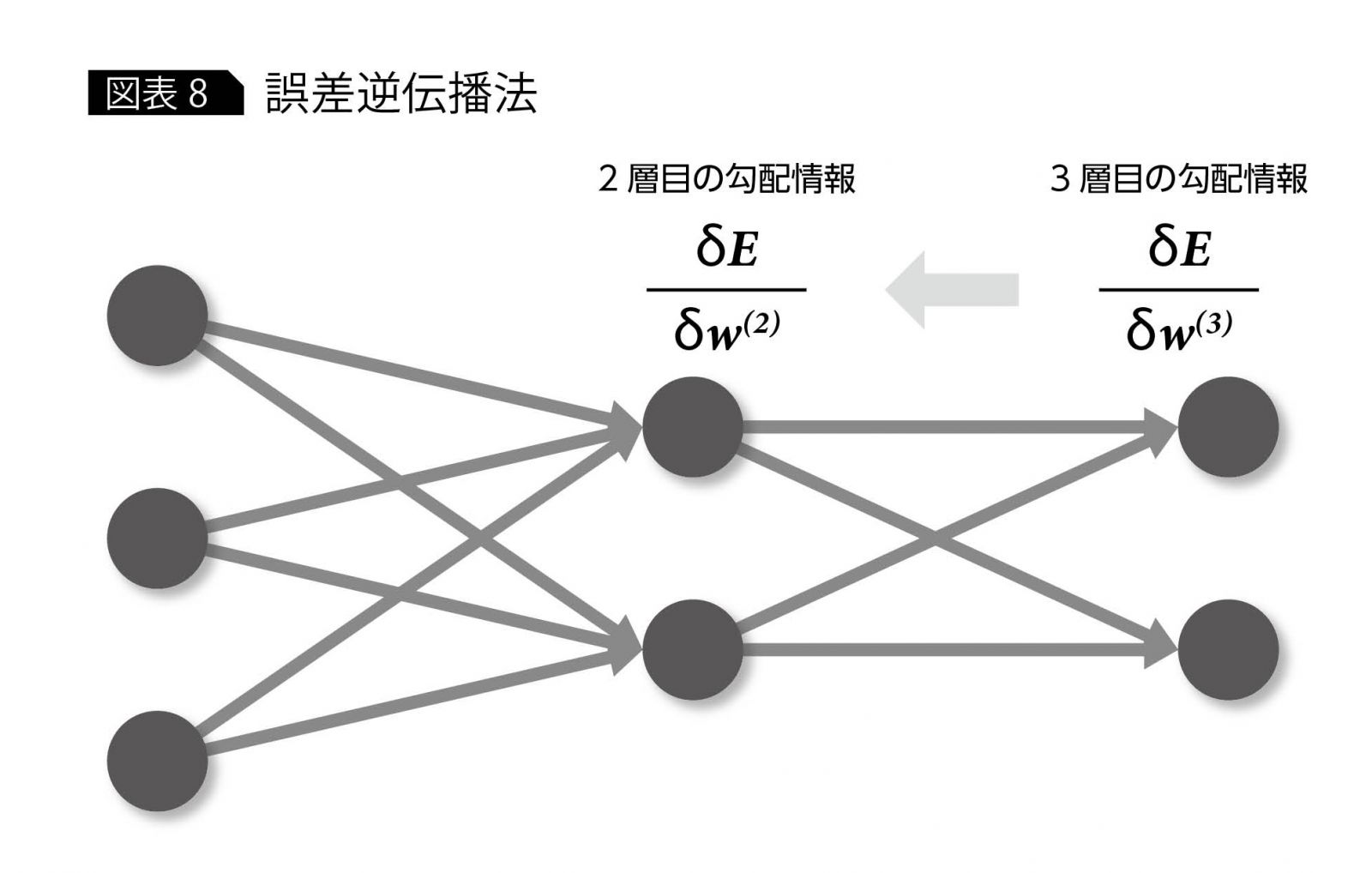
ただし、誤差逆伝播法には、重みの初期値の選び方が悪いと、勾配の値が0になってしまい、勾配降下法において初期値から移動できなくなってしまうという問題があり、長年、多層ニューラルネットワーク研究の大きな足かせとなっていた(勾配消失問題)。この問題が、前述した2006年のヒントン教授による技術革新で解決されたことにより、今日のディープラーニング・ブームのきっかけとなったが、詳しくは後の連載でまた触れることとする。
ニューラルネットワークの
動作イメージ
ニューラルネットワークは、勾配降下法と誤差逆伝播法を用いてデータを基に学習を行っていくが、ここでは、学習されたネットワークがどのように動作するかを考えてみよう。
例として、入力画像から人間の顔を判別するニューラルネットワークを取り上げる(図表9)。ニューラルネットワークは、入力画像全体を直接認識して人間の顔かどうかと判別するのではなく、“人間の顔かどうか?”という問題をいくつかの小さな問題に分割する。たとえば、“左上に目があるか?”、“真ん中に鼻があるか”などである。この1つ1つの小問題が隠れ層のニューロンに相当し、複数の小問題に対する回答を総合して、最終的な問題の回答を作成する。左上に目があり、真ん中に鼻があれば、人間の顔の可能性が高く、左上に目があるが、真ん中には鼻がなければ、人間の顔の可能性は低いというような動きである。
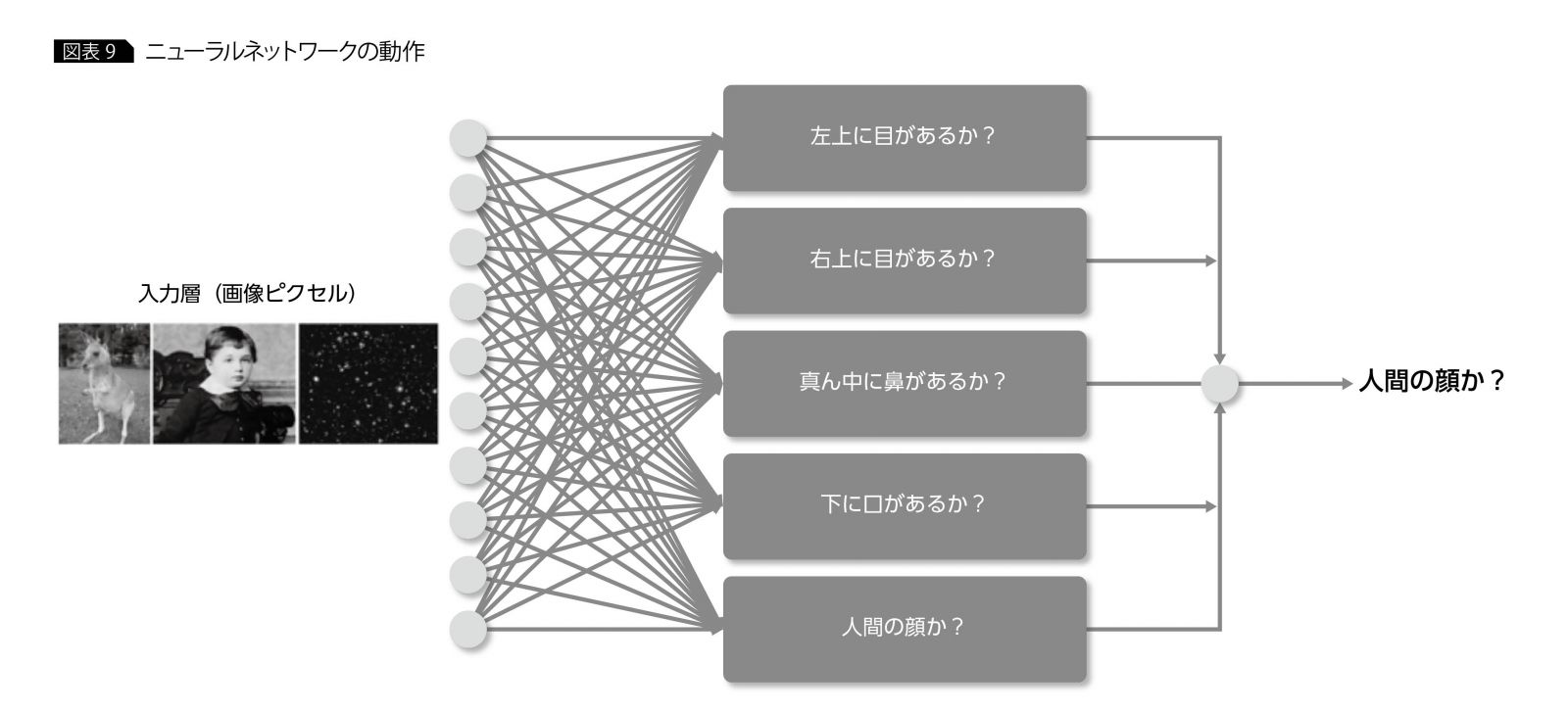
この小問題は、人間の顔を判別するうえで、特に注目すべきポイントとしてネットワークが自動的に抽出したものであり、この抽出のことを特徴量抽出と呼ぶ。特徴量抽出は、ニューラルネットワークおよびディープラーニングの大きな特色となっており、人間の概念化作用とも類似していることから、人工知能の分野で、大きく注目されている。
*
今回は、ディープラーニングを理解するうえで必要となるニューラルネットワークの知識について解説を行った。次回は、ディープラーニングの代表的な手法である畳み込みネットワークを取り上げる。
・・・・・・・・
著者|植田 佳明 氏
日本アイ・ビー・エム システムズ・エンジニアリング株式会社
アナリティクス・ソリューション
アドバイザリーITスペシャリスト

2001年、日本IBM入社。2005年に日本アイ・ビー・エム システムズ・エンジニアリングに出向し、当初はIAサーバー基盤、WebSphere Application Server関連のプロジェクトや技術サポートを担当。2012年よりSPSSを中心としたアナリティクス製品のサポートやデータ分析プロジェクトに従事し、近年ではWatson・ディープラーニングといった人工知能、コグニティブ関連の活動にも携わっている。
[IS magazine No.12(2016年7月)掲載]
・・・・・・・・
連載 ディープラーニング入門 全4回 CONTENTS
第3回 再帰型ニューラルネットワークの「基礎の基礎」を理解する
・・・・・・・・