「稼働率99.999%」とは
72台に1台が長時間停止すること
「毎年、ストレージの約70台に1台は、重大障害によって長時間停止しているかもしれない」と聞いたら、みなさんはどう感じるだろうか。「けっこう高い確率で壊れるなあ。ボロいストレージなのかな」と思われるかもしれない。しかし、この「約70台に1台」は、ストレージ・ベンダーがストレージ装置の高可用性をアピールする際によく使う「稼働率99.999%」とほぼ同じ意味である。想像している以上にストレージは壊れているのかもしれない。
稼働率とは、ある装置やシステムが「動いていてほしい時間」に対して、「実際に動いていた時間」を割合で示したものだ。ある期間内に予期せぬ稼働停止が一度も起こらなければ稼働率は100%、本来利用したい時間の1/2しか利用できなければ稼働率は50%になる。「IT機器の稼働率」はIT機器の「壊れにくさ」「止まりにくさ」を示す数値であり、100%に近いほど「堅牢なIT機器」となる。
多くのIT機器ベンダーは稼働率99.999%を「ファイブナイン」と称して自社製品の可用性の高さを宣伝している。この99.999%という数値は、24時間365日、IT機器を稼働させた場合、1台あたり約5分(正確には315.3秒)しか止まらないという計算結果になる。
しかし、実際にIT機器に重大障害が起これば、残念なことに5分ではとうてい復旧できないケースが多い。ストレージ装置で全体障害が発生した場合を想定すると、障害が発生した際には障害自体を何らかの方法で検知し、データセンターに保守員やインフラ担当者が駆けつけ、マシンの状況やログから障害の原因箇所を特定し、復旧のためにパーツの交換やストレージの再起動を行う。ケースによってはデータのバックアップからの復元や、途中まで実行されていたタスクの手戻り処理などの作業が発生する。こう考えればおわかりのとおり、ある程度長時間(数?十数時間)のシステム停止は避けられない。
ここでもう一度、99.999%に立ち戻ろう。
1件の障害が発生すると、その修復に明らかに何時間もかかるはずなのに「稼働率は99.999%で、年平均に換算すると停止時間は5分以下」となるのはどうしてだろう。
この答えは、確率計算の母数が全出荷台数であるからだ。つまり高い稼働率が達成できているのは、出荷されたすべての装置が「まんべんなく5分止まる」のではなく、大多数の「稼働率100%」のマシンと少数の「重大障害が発生した」マシンの平均値を取っているからである。
仮に、1件の重大障害で6時間マシンが停止すると仮定し、稼働率が99.999%(1台あたり平均5分のマシン停止)になるように計算すると、72台に1台、確率にして約1.36%の割合で重大障害が起きていることになる。「毎年、約1.36%の確率で重大障害が起こる」と言われるのと、「稼働率 99.999%」とでは、受ける印象がかなり違うのではないだろうか(図表1)。

仮に同じ稼働率を提示する別々の機器が存在した場合、出荷台数が多い機器では重大障害の発生件数が当然のように多くなるし、逆に出荷台数が少ない機器では重大障害の発生件数は少ないことになる。つまり重大障害の発生件数の多寡だけで、機器全体の品質を評価してはいけないということだ。
ディスクの大容量化が
2重障害リスクを高めている
ここからは話をストレージ装置に絞って考えてみたい。
はじめに理解しておきたいことは「可用性が高いと言われるストレージであっても、障害によって停止するリスクは一定程度ある」ということだ。これは、どのベンダーのストレージであっても同様である。「運を天に任せる」にはリスクが高すぎる、と感じるのは私だけではないだろう。
企業向けに提供されるストレージの大半は高可用性をうたっている。内部部品を2重化もしくは冗長化し、単一障害ではストレージの全体停止が起こらないアーキテクチャになっている。それにもかかわらず重大障害が起きてしまうのは、ごくまれながら部品、または機能にまたがる「2重障害」が発生しているからだ。
ストレージの構成部品のなかでも、とくにディスク・ドライブ(以下、ディスク)はここ数年で2重障害のリスクが高まっている。その原因は、ディスクの大容量化によって、「リビルド」と呼ばれる障害時の復旧処理が長時間化しているからだ。
ディスクは通常、RAIDと呼ばれるデータ保護方式によって冗長化され、1個のディスクが壊れた際には、壊れたディスクのデータをスペア・ディスク(退避用ディスク)に自動復旧させる機能をもっている。この処理を「リビルド」(再構築)という。
ストレージの構成や設定にもよるが、大容量タイプ(7200rpm)のディスクの場合、リビルドが完了するまでの時間はディスク容量1TBあたり1日程度が目安だ。2017年現在、市販されている一番大きなディスクのサイズは1本10TBなので、この目安を参考にするとリビルド完了まで約10日間かかることになる。数時間で復旧するならともかく、10日間も復旧に時間ががかるとなった場合、リビルド完了前に同じRAIDグループで別のディスクが故障する可能性は高くなる。もし2本目が故障したら2重障害となり、システムが停止すると同時に重要なデータが失われることになる。ディスクが大容量化している昨今、このリビルド完了までの待ち時間は相当なリスクとなっている(図表2)。

大容量ドライブを使用する際には、2本のディスク障害まで復旧できるRAID6方式を採用するケースも増えているが、依然としてリビルド処理にかかる時間の長さはシステム運用上の課題となっている。
また、ストレージのハードウェア自体に障害が起こらなくても、予想外の出来事でストレージが停止してしまうこともある。たとえば、「パーツ交換時、誤って正常なパーツを交換してしまった」「障害監視機能を停止してしまい、障害に気づかなかった」「ストレージの緊急停止ボタンを押してしまった」という「人災」によるストレージ停止が、実際に起きていることを忘れてはならないだろう。
仮想化の普及が
システム再稼働を遅らせている
障害であれ人災であれ、ストレージがダウンするとそのダメージは想像以上に大きく、システム全体の停止期間は数日に及ぶこともある。システムの停止期間が長期化する理由は、ストレージ自体の回復作業もさることながら、ストレージの停止に伴って緊急停止したシステム全体の再稼働に時間がかかるからだ。とくに、近年では再稼働に要する時間は長期化する傾向にある。
システムの再稼働に時間がかかるようになった原因の1つに、サーバーが仮想化されたことが挙げられる。最近ではVMware ESXやHyper-Vなどのハイパーバイザーによって、サーバーを仮想化するシステムが多くなった。サーバーを仮想化する際、仮想マシンのOSイメージは外部ストレージに保管することが多く、ストレージがダウンした際には必ず仮想マシンのOS再起動が必要となる。このOSの再起動作業に、意外に時間がかかってしまう。
システムが緊急停止した場合、OSは再起動時にファイルシステムが正常な状態で終了していないことを察知する。これに対処するためファイルシステムの整合性をチェックし、復旧する作業を実行する。WindowであればCHKDSK、 Linuxであればfsckがこれにあたる。このファイルシステムの整合性確認も起動時間の長期化の要因になる。1台のストレージから数十・数百もの仮想マシンを再起動するケースでは、それだけで何時間もかかる場合もある(図表3)。
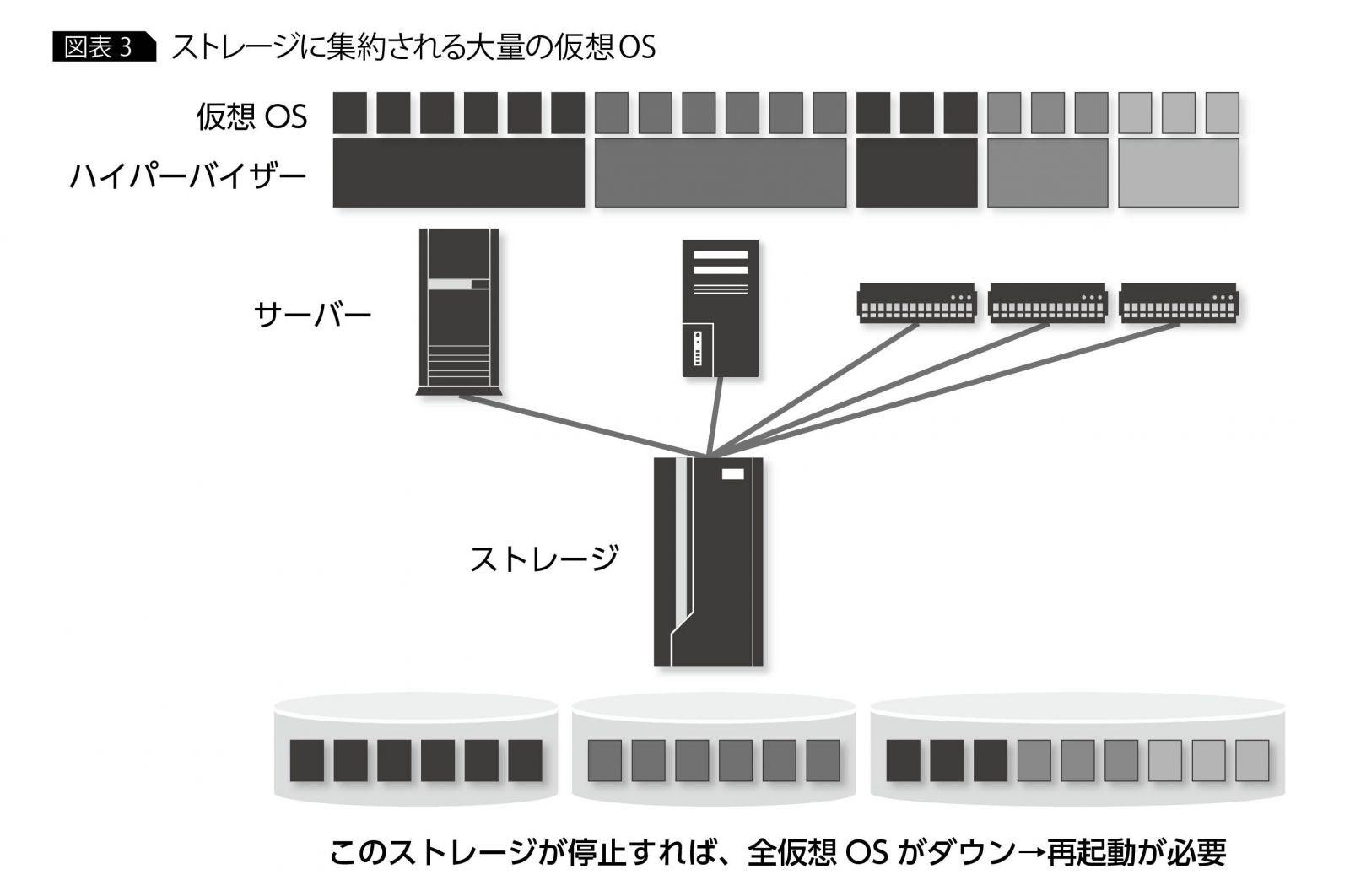
さらに付け加えると、OSとして起動できたからといって、すぐにシステムをユーザーに開放できるとは限らない。システム管理者はストレージ障害によって失われたデータの有無を確認する必要がある。もし、システム障害発生中も関連業務が継続されていたら、システム停止中の業務データを手作業で反映させなければならない場合もある(図表4)。
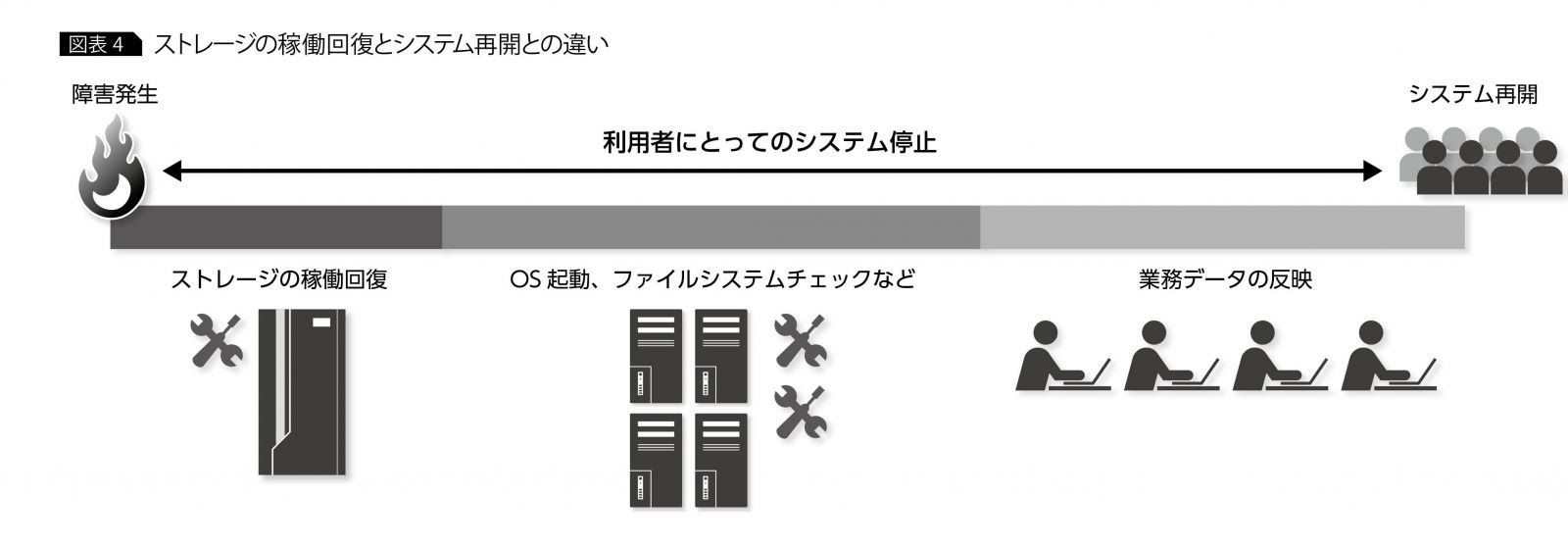
こうした作業すべての完了を待つとなると、実際にユーザーがシステムの利用を再開できるのは、障害発生から数日先になってしまう可能性すらある。
ストレージ筐体2重化にも
2つの課題が残る
一般に市販されている企業向けストレージ装置は、各コンポーネントがすでに2重化されているケースが多い。しかし、そうであっても少ない確率ながらストレージの重大障害が一定の確率で発生し得ることを、ここまでに紹介した。しかもその状態が起きたときのシステム停止時間は非常に長くなる傾向にある、という実情についても紹介した。ゆえに少なくとも、自社の存続を左右するビジネスを担うシステムや、社会インフラの一翼を担い、その停止が社会全体へ重大な影響を及ぼすシステムについては、一般的な製品がもつ障害対策を超えたシステム設計が必要になることは理解してもらえたであろう。
では、ストレージの機器の重大障害に対して、具体的にどういう対策を取り得るのか。それはストレージ筐体自体を2重化することである。誤解を避ける意味であえて再度記すが、ここで言う「筐体の2重化」とはストレージ筐体内部のパーツの2重化ではなく、機器そのものを2台用意することにほかならない。
仮に片方のストレージがダウンしても、もう一方のストレージを利用してシステムが稼働し続けられるようにすれば、ストレージ障害によるシステム停止の確率を極限まで下げることができる。
ストレージ筐体を2重化する代表的な方法としては、①ストレージの筐体間ミラーリング、②OS(ファイルシステム)やミドルウェアによるミラーリングの2つがあるが、いずれの方法にも課題があった(図表5)。
① ストレージの筐体間ミラーリング
ストレージ機器がもつミラーリング機能(遠隔コピー機能)でデータを2台のストレージに2重書きすることで、OSやアプリケーションに依存せず、シンプルな設定・運用でストレージの筐体2重化を実現できる。
しかし、ストレージの機能でミラーリングする場合、ミラー先のディスクは通常時はサーバーに接続されていない状態で存在する。通常接続しているストレージ機器(ミラー元)が全面ダウンとなった場合、当然ながらサーバーはストレージへのアクセスができなくなってしまうため、システムとしては必ずダウンしてしまう。障害が起き、サーバーが停止した状態で新たにミラー先のディスクを手動で接続変更することで、再起動が可能となる。つまり、切り替えの際にシステムが必ず停止してしまうのが大きな課題点だ。
加えて、ストレージ切り替えの判断は、ユーザーが行う必要があるので、担当者間で意思疎通に時間がかかったり、責任者による決断が遅れるとその分だけ回復処理も遅れることになる。
② OSやミドルウェアによるミラーリング
OSやミドルウェアから複数のボリュームに対して、適用業務プログラムに透過的にデータを2重に書き込む機能を利用する方法だ。
代表的な例としてはAIXのLVMミラーやOracle ASMのミラーリングなどが挙げられる。別々のストレージ上にあるボリュームでミラーを構成すれば、1台のストレージが停止してもシステムは稼働し続けられる。この機能で2重書きを行う場合、必ずしも同じストレージ機器へ書き込む必要がないので、機器選択を柔軟にできるというメリットがある。
課題は、OSやミドルウェア固有の機能に依存する点である。複数のOSやミドルウェアを利用している環境では、ミラーリングの設定や解除、障害時の再同期処理などの方法を複数覚えなければならず、運用上の負担が大きい。作業の種類が増えれば、障害時のオペレーション・ミスのリスクも高くなる。当然だがミラーリング機能を有していないOSやミドルウェアを使っている場合、この方式は選びたくても選択できない。
ストレージ筐体2重化の課題を克服した
IBM HyperSwap機能
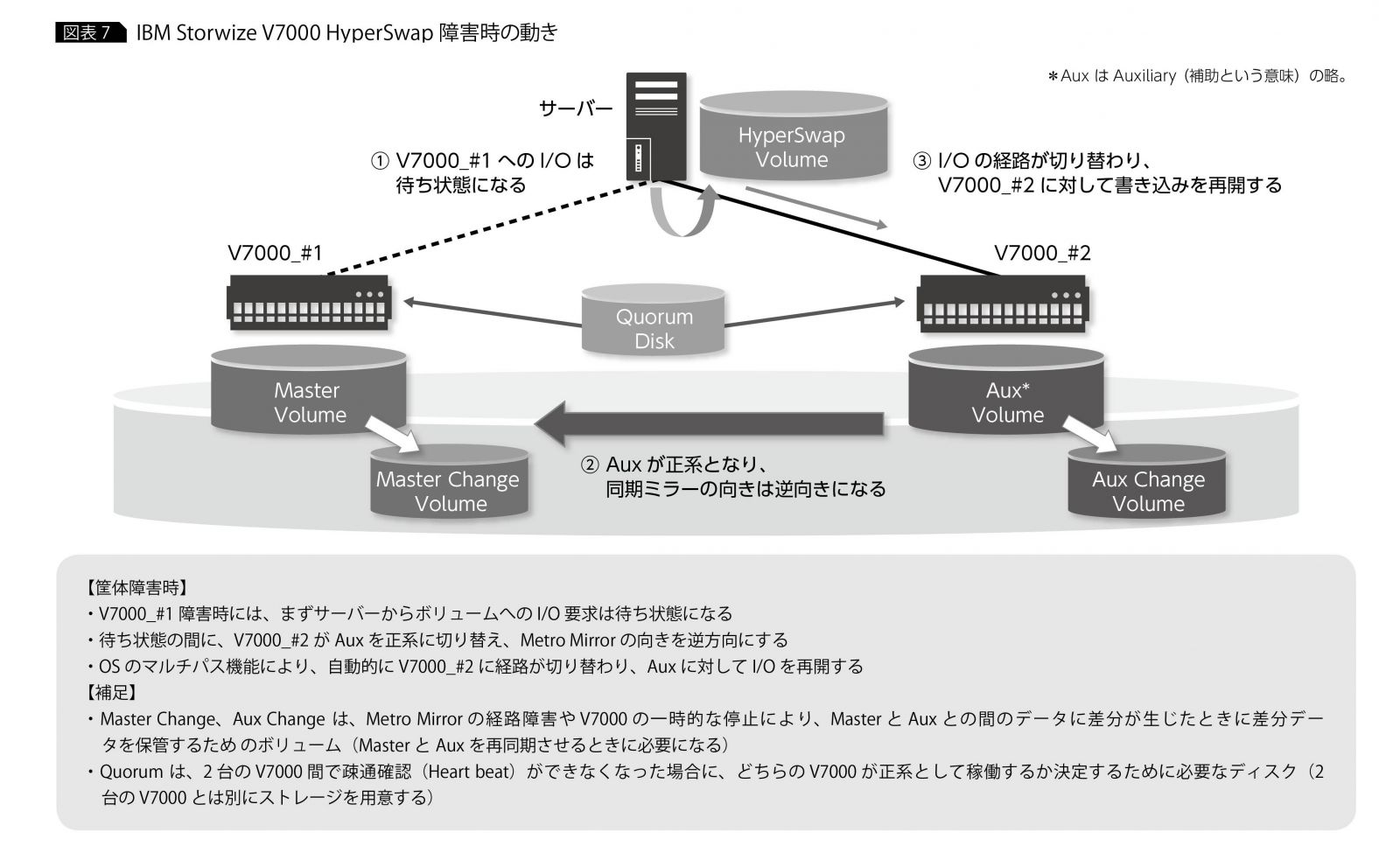
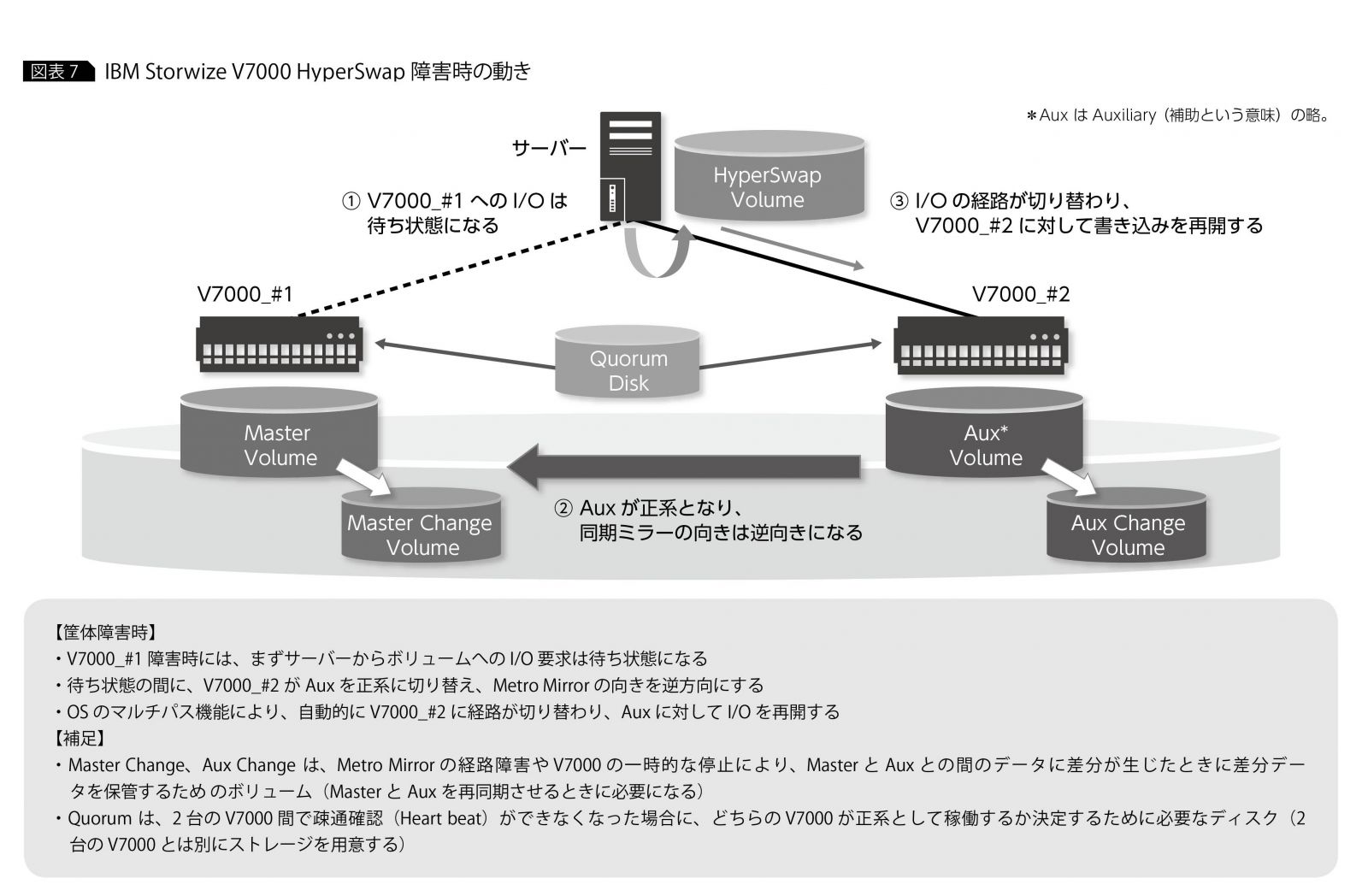
①や②の課題を克服できる技術として最近注目を集めているのが、「IBM HyperSwap」(以下、HyperSwap)というストレージ機能だ。HyperSwapは、通常時には2台のストレージ筐体間でデータを2重書きしておき、障害時には数十秒程度の短時間でオンラインのままストレージ筐体を自動的に切り替えることができる。サーバー・システムはストレージの障害に気づくことなく継続稼働できるし、ストレージの機能なのでアプリケーションごとに運用を変える必要もない、という優れものだ。現在、IBMの主要なストレージは、このHyperSwapを構成できるようになっている。
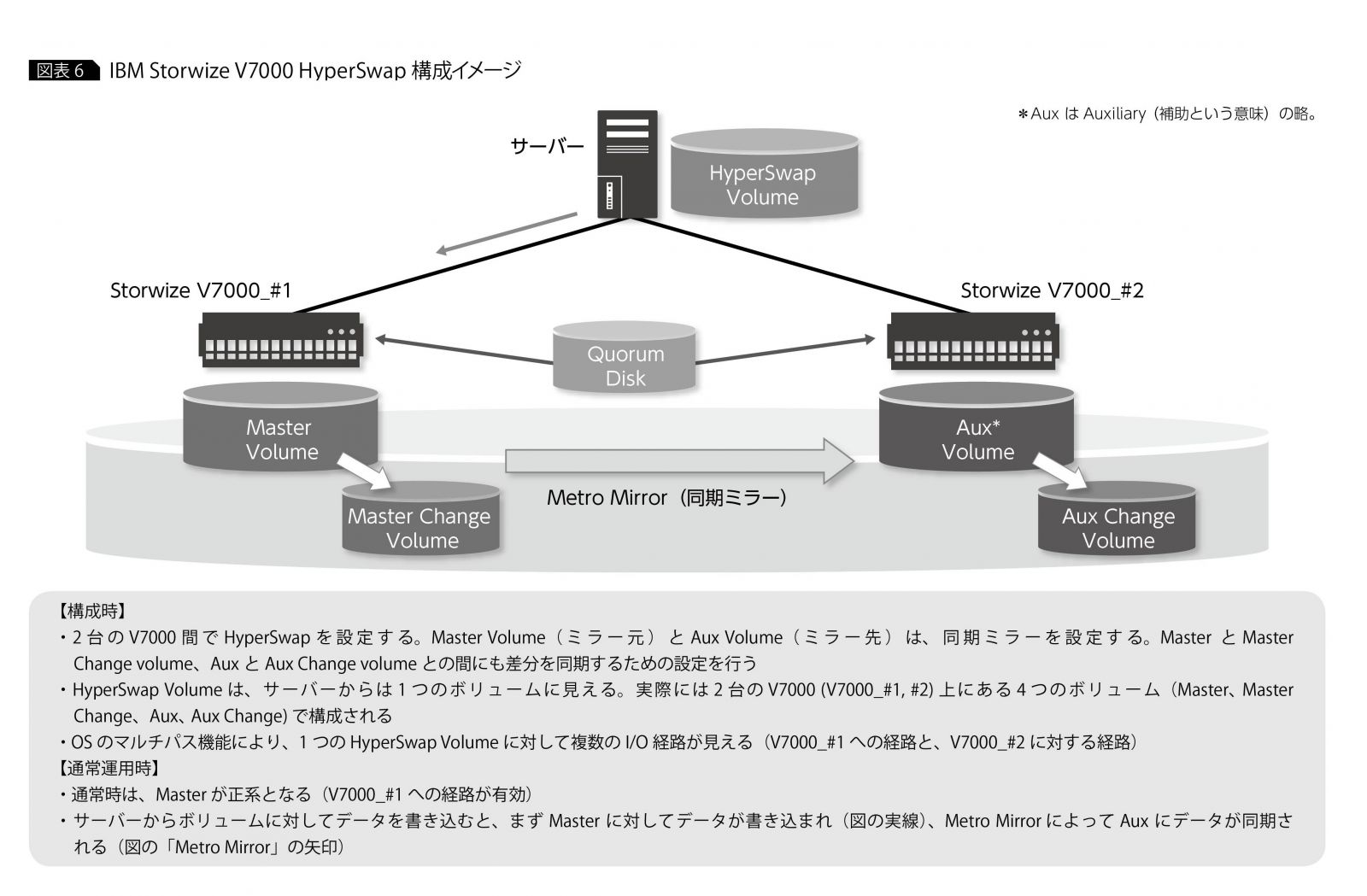
HyperSwapの構成や動作は至ってシンプルだ。まず、HyperSwapを構成する際には、2台のストレージのボリューム間でミラーリングを設定し、この両方のボリュームをサーバーに割り当てておく。システムからは、実態としてはミラー元、ミラー先の2つのボリュームが、OSのマルチパス機能によってまとめられ、複数のI/O経路をもった1つのボリュームとして仮想的に認識される。システムからは、このボリュームに対してI/Oを行う。
通常時は、システムはミラー元のボリュームへの経路を介してI/O処理を行う。ミラー元のボリュームで更新されたデータは、ストレージのミラーリング機能によってミラー先のボリュームにコピーされる。これにより、ミラー元とミラー先のボリュームは常にまったく同じデータを保持していることになる(図表6)。
ストレージ筐体のダウンによりミラー元のボリュームが使えなくなると、ストレージとOSのマルチパス機能が連携して、しかかり中のI/Oを一時的に待ち状態にしている間に、自動的にミラー先のボリュームに対する経路に切り替えて、I/O処理を継続する。ストレージのミラーリングの機能によりミラー元とミラー先のボリュームはまったく同じデータを保持しているので、しかかり中のI/Oの宛先がミラー先のボリュームに切り替わってもデータの整合性は保たれる。システムから見ると、ストレージ筐体がダウンしたとしても、複数あるI/O経路の一部が利用できなくなったのと何ら変わりがない動きになるのだ(図表7)。
HyperSwapは、もともとメインフレームとハイエンド・ディスク装置の組み合わせでのみ実装できる技術だったが、最近ではIAサーバーとミッドレンジ・ストレージ装置の組み合わせでも利用できるようになり、採用のハードルはずいぶん下がっている。これまで、都市銀行をはじめとする金融機関や、電気・ガスなどの社会インフラに携わる企業、通信販売、インターネット・ショッピングなどで、ストレージ機器の2重化はすでに採用されてきた。HyperSwapのような運用しやすいストレージ2重化の技術が出てきたことで、今後はより多くの企業でストレージ2重化の検討が進むと予想される。
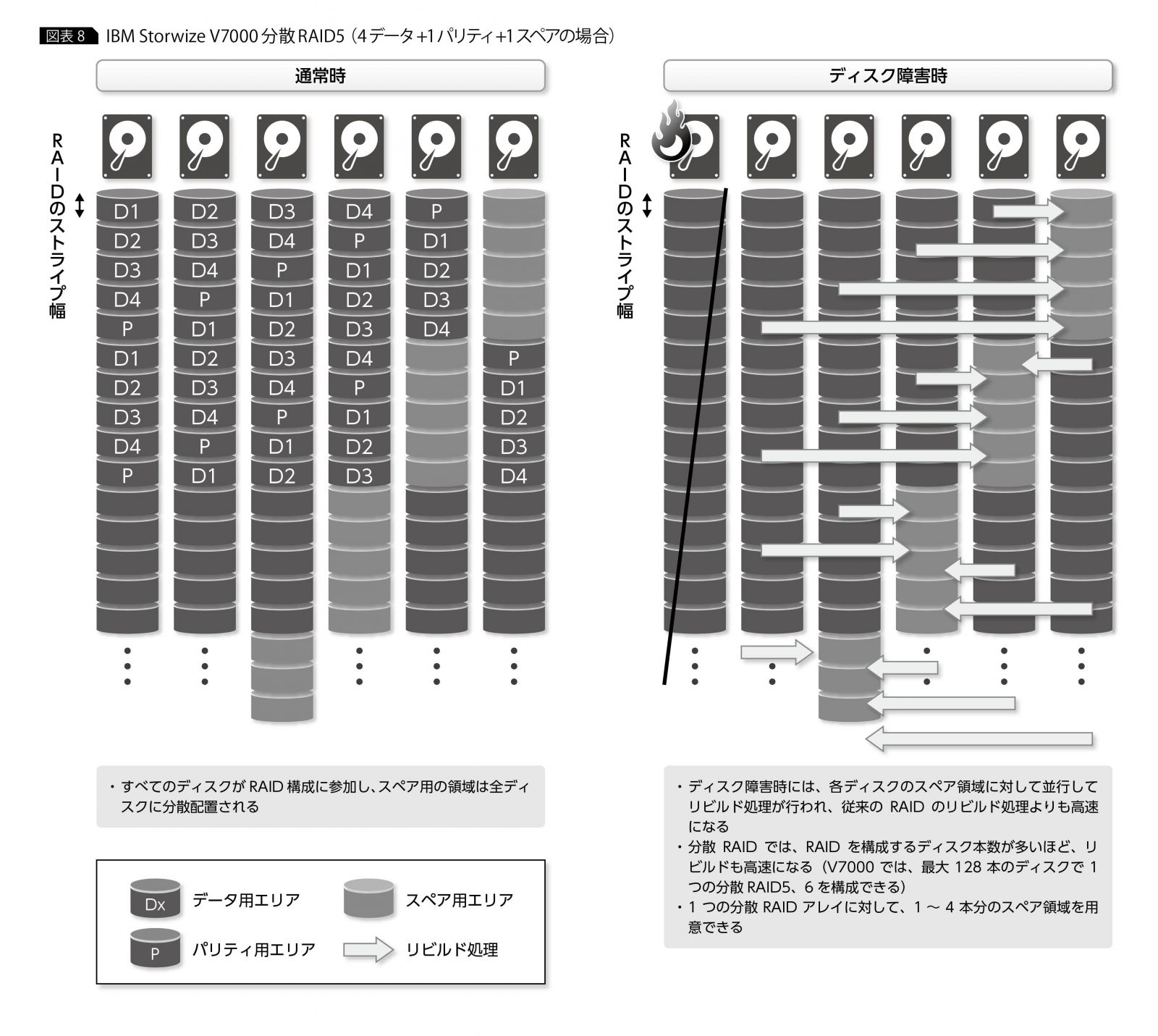
ストレージ筐体全体の2重化以外にも、ストレージの重大障害への対応は広がっている。たとえば、先に述べた大容量ディスクの2重障害への対応として、最近では新しいデータ保護方式によりリビルド時間を短縮するアプローチが取られている。RAIDのリビルド処理に時間がかかるのは、1本のスペア・ディスクに対してデータのリビルド処理が行われ、ディスクへの書き込み速度がボトルネックとなってしまうからだ。
ディスク2重障害への
分散RAIDと運用面の対策
そこで、「分散RAID」と呼ばれる新しい方式では、RAIDグループに含まれるすべてのディスク上にスペア用の領域を一定の割合で用意し、ディスク障害が発生した際には残りの全ディスクを使ってリビルド処理を行うことで、リビルドの高速化を実現している。
分散RAIDの考え方は、IBMストレージでは最初「XIV Storage System」で採用され、現在ではStorwizeファミリーでも利用できるようになっている(図表8)。分散RAID自体は無償なので、大容量ドライブを利用される際には積極的に活用を検討してもらいたい。
ハードウェアによる重大障害の防止以外に、ふだんの運用のなかでやるべきことをやっておくことも大切だ。
たとえば、ストレージには最新のマイクロコードを定期的に適用しておきたい。最新のマイクロコードには、発見された不具合の修正パッチが含まれている。「防げるはず」の障害を起こしてしまうと、担当者は相当後悔するはずだ。
法定点検などの機会を利用して、ストレージ電源OFF/ON時の対応も確認しておきたい。みなさんも自宅のマンションや会社のビルで火災訓練に参加したことがあるだろう。ストレージが停止したときに備えて「防災訓練」を経験しておくことは、現場の担当者が障害発生時にパニックにならないために効果的だ。
24時間365日止められないシステムで、こういった対応が困難なケースも出てくるかもしれない。そんなときこそ、HyperSwapに代表されるストレージ2重化のソリューションを利用して、メンテナンス作業や障害のリハーサルを実施できるインフラにしておきたい。
*
本稿では、ストレージの重大障害とその対策について論じた。少し気が重くなるかもしれないが、どこかで真剣に考えなければならないテーマである。自動車を運転するときには必ず自動車保険に入るのに、停止影響が非常に大きなシステムのストレージであっても「保険」をかける人が少ないのはなぜだろうか。今や、重要システムでサーバーを2重化(クラスタリング)するのは当たり前になっている。そろそろストレージの2重化に着手してもよい頃合いだ。「備えあれば憂いなし」というが、心の平穏を得るためにも重大障害に対して可能な限りの対策を考え、後悔のない対応をしておきたい。
[IS magazine No.17(2017年9月)掲載]
著者
佐野 鉄郎 氏
日本アイ・ビー・エム株式会社
システムズ・ハードウェア事業本部
ソリューション事業部
シニアITスペシャリスト
2000年、日本IBM入社。これまで、ストレージSEとして、ハイエンド・ディスクの製品担当をはじめとして、ストレージ・ソリューションの提案活動、インフラ環境のコンサルティング、パートナー企業とのビジネス開発など、幅広い業務に携わる。現在は公益(電力・ガス)系のお客様を中心に、提案活動に努めている。








