閾値監視の限界
情報システムの安定稼働には、ネットワーク、ハードウェア、ソフトウェアなどシステムの構成要素を総合的に監視し、サービスの中断やビジネスへの影響につながりかねない障害をいち早く検知して対応することが不可欠である。
多くの情報システムでは「統合監視ツール」を導入し、システムを構成する各コンポーネントのリソース使用状況やログを監視して、障害検知を実行している。動的に推移するリソースの使用状況やアプリケーションのパフォーマンス監視方法としては、監視対象のメトリック(計測値)ごとに閾値を設定し、その閾値を上回る(または下回る)場合にアラートを発報する「閾値監視」が一般的である。
しかし閾値監視には次のような課題がある。
・ 閾値を超えて初めて異常を検知するため、性能の段階的劣化など、メッセージを伴わないサイレント障害を早期に検知できない。
・ 監視対象のメトリックはその時々のサーバー負荷により推移し、一時的に閾値を超えたからといって異常であるとは限らない。閾値を低く設定しすぎると誤検知になる可能性が高まり、逆に高く設定すると障害の発見が遅れるリスクがあり、設定が難しい。
・ 仮想化技術やクラウドの利用により複雑化したシステムでは、監視すべきメトリックが多く、個々のメトリックに対して閾値を検討し、設定することは運用上の大きな負担となる。
こうした課題に対応可能な新たな監視手法として今、障害予兆検知が注目を浴びている。
障害予兆検知を支える技術
障害予兆検知とは、一定期間収集したメトリックから通常時のメトリックの推移パターンを統計理論や機械学習を用いてモデル化し、そのモデルと比較して通常時と異なる兆候を検知する監視手法である。
この監視方式は決して新しくはなく、2010年前後に大手ベンダー数社が相次いで統計理論を活用したシステム障害予兆検知ツールをリリースしたことで話題となった。いずれもCSVファイルや性能監視ソフト、パケットキャプチャなどから取得したデータを統計処理することで、データの推移や相関をモデル化し、障害の予兆を検知する機能を備えている。
近年の機械学習やコグニティブ技術の急速な発展に伴い、2016年ころからこうした技術を活用した障害予兆検知ツールがリリースされ、再び注目を集めている。主要なツール・サービスを図表1に挙げる。
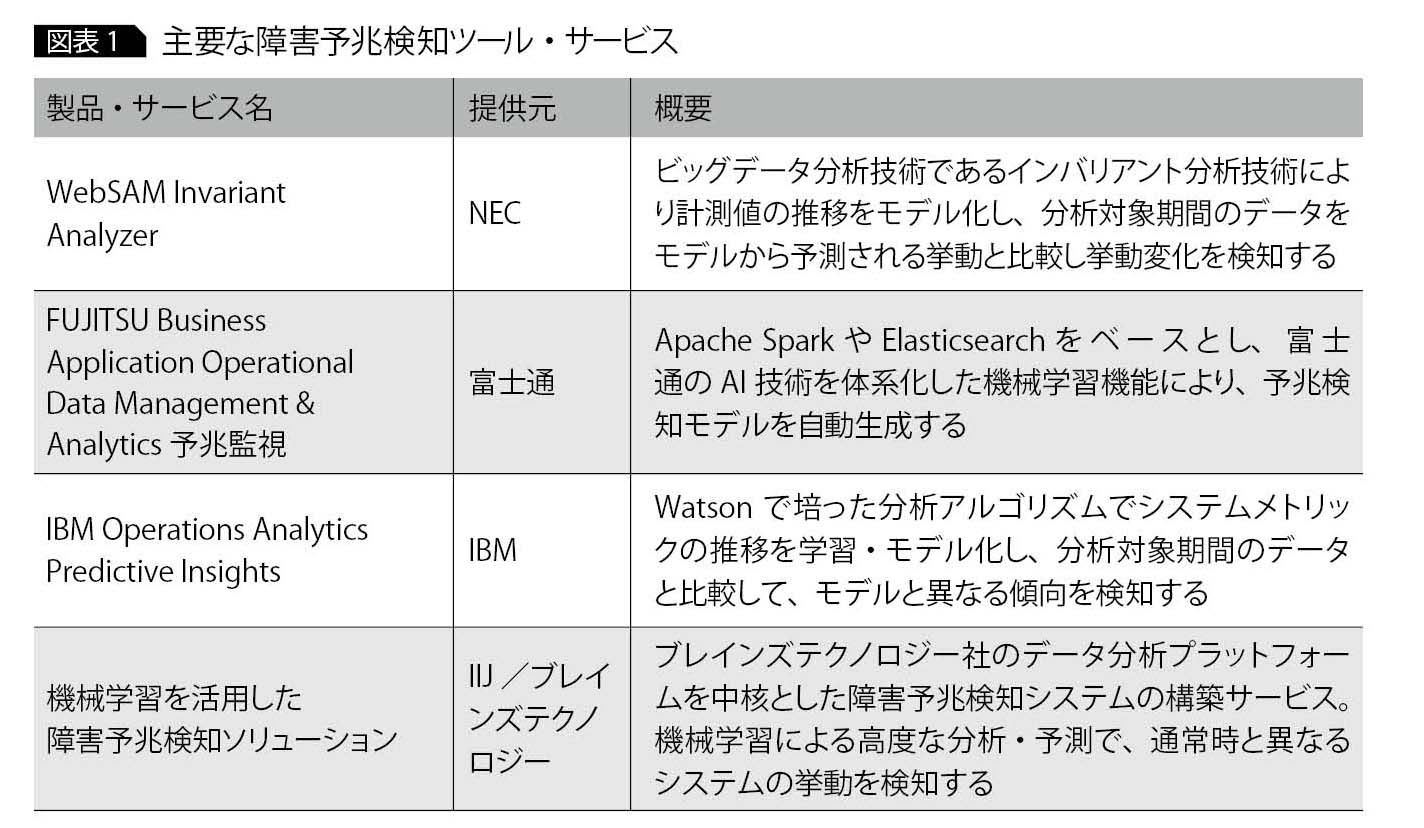
ベンダー各社が提供する障害予兆検知ツールには、それぞれ独自の技術やノウハウが組み込まれているが、いずれも次の2つの主要技術に支えられている。
分析技術
メトリックのパターン学習や分析には、ベンダー各社がAI技術の開発などで培った機械学習機能、統計理論をもとにしたデータの変動予測やデータ間の関係性を見出す技術が用いられている。
可視化技術
いずれのツールも検出した障害予兆に関連し、サイレント障害の要素や影響範囲を円グラフやマップで可視化したり、予兆を検出したメトリックを時系列でグラフ化し、さらに関連のありそうなメトリックを重ねて表示するなどの機能を備えている。
IBM の障害予兆検知ツール
IBMの障害予兆検知ツールとして、「IBM Operations Analytics Predictive Insights」(以下、IOAPI)がある。2015年3月に初版がリリースされ、本稿執筆時点の最新バージョンは1.3.6である。
IOAPIは、次の機能を提供する。
データ・マッピング機能
監視ツールのデータベースやファイルなど、任意のデータソースからシステムの性能情報など抽出・分析対象とするデータをIOAPIデータベースへ取り込むよう設定する。
データ抽出・分析機能
データソースからシステム性能情報を読み込み、平常時の挙動をパターン学習して分析モデルを生成し、データを分析モデルと照らし合わせて通常時の挙動から逸脱した状態を早期に検知する。
分析結果の視覚化機能
メトリックの推移をグラフ化し、分析結果を視覚化する。ダッシュボードに異常イベントの時系列発生数や発生ノードなどを表示し、異常イベントを視覚的に把握できる。
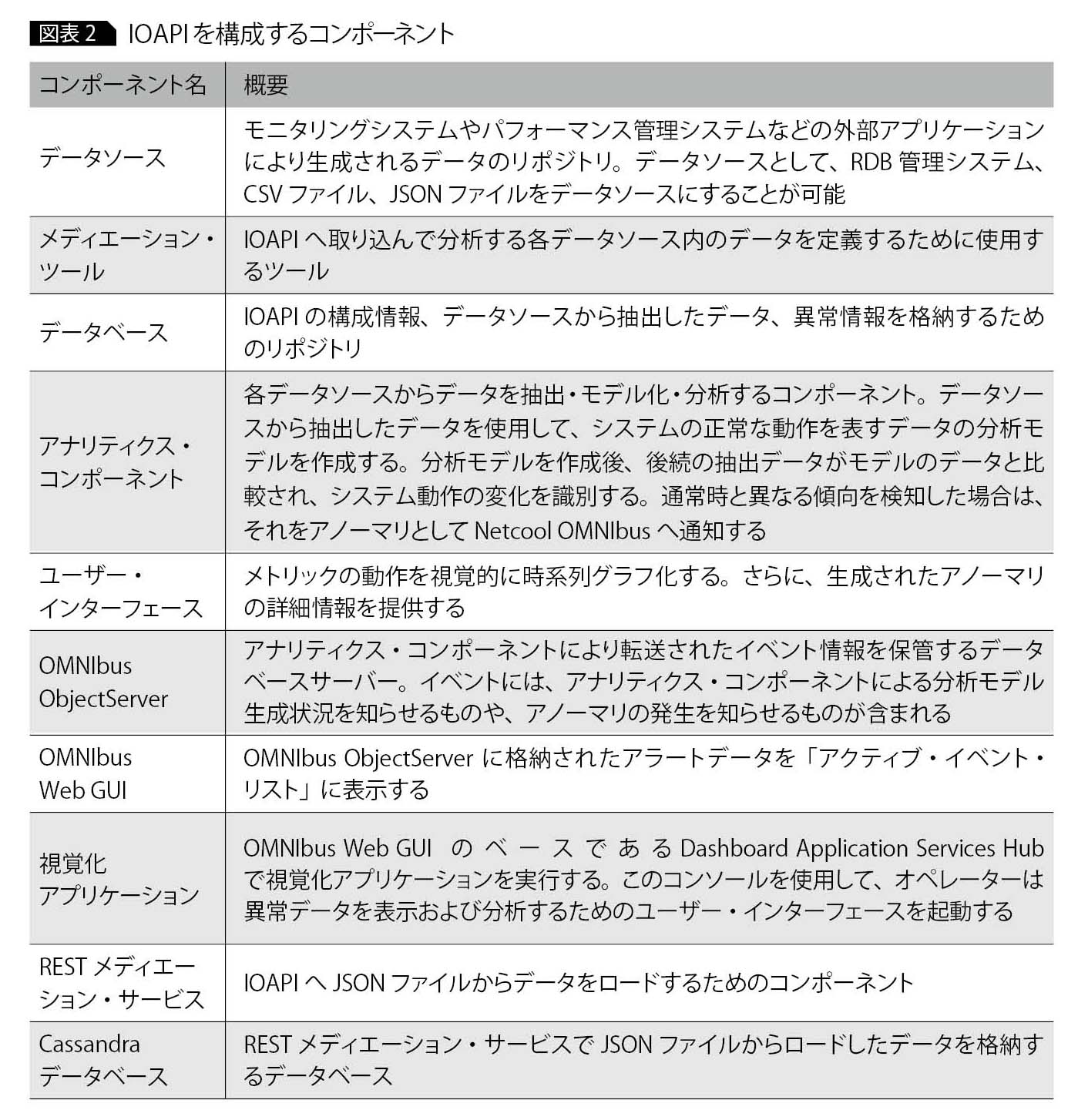
IOAPIは、図表2に記載したコンポーネントで構成される。
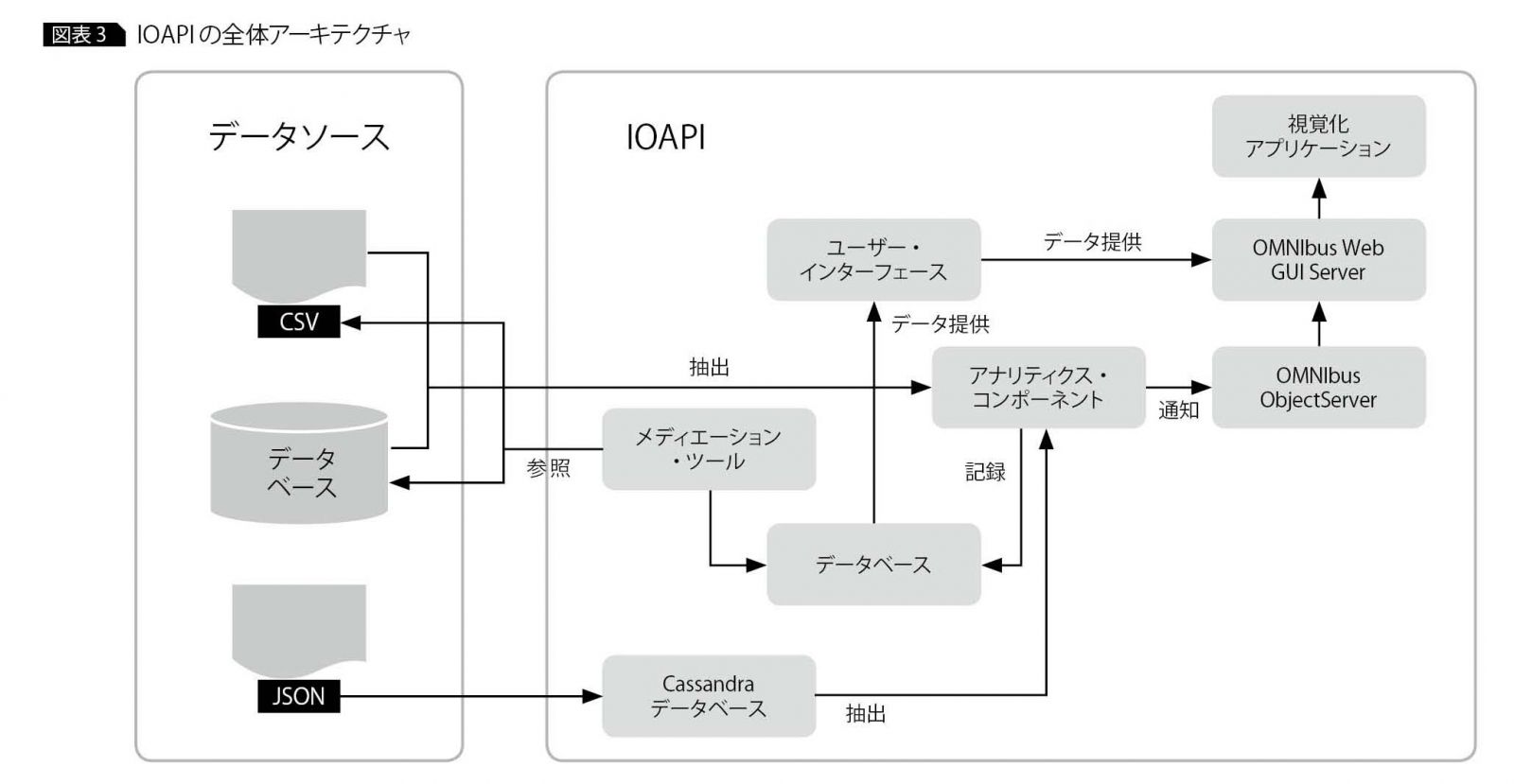
各コンポーネントを含む全体アーキテクチャを図表3に示す。
IOAPIによるデータ分析の流れは、大きく以下の3つのステップで構成される。
① データの準備
IOAPIへデータを取り込むためのデータソースを準備する。データソースのタイプとしてCSVファイル、データベース、JSONファイルの3つがサポートされる。
② データモデルの定義とデプロイ
メディエーション・ツールを使用してデータソースに接続し、データソースのタイプ、接続情報、データソースから抽出して分析対象とするメトリックなどを含むデータモデルを定義し、IOAPIデータベースにデプロイする。
③ データの抽出と分析
アナリティクス・コンポーネントは、前ステップで作成したデータモデルの定義に従ってデータソースから抽出したメトリックを各分析アルゴリズムによって分析し、動作を学習する。どの分析アルゴリズムを使用するかは、IOAPIの内部ロジックにより決定される。
アルゴリズムによりメトリックのモデルが作成されると、その後抽出されたデータをモデルと比較し、モデルからの逸脱が認められた場合に異常状態(アノーマリ)として検出する。検出したアノーマリについては、その情報をデータベースに書き込むとともに、異常イベントを「OMNIbus ObjectServer」へ送信する。
独自アルゴリズムによる分析
IOAPIでは、データの抽出・分析時にコグニティブ技術が適用される。具体的には、IBM ワトソン研究所で開発されたさまざまな障害を検知する独自アルゴリズムを使用して、データを分析する(図表4)。これらのアルゴリズムを適用することで、たとえば次のようなことが可能となる。

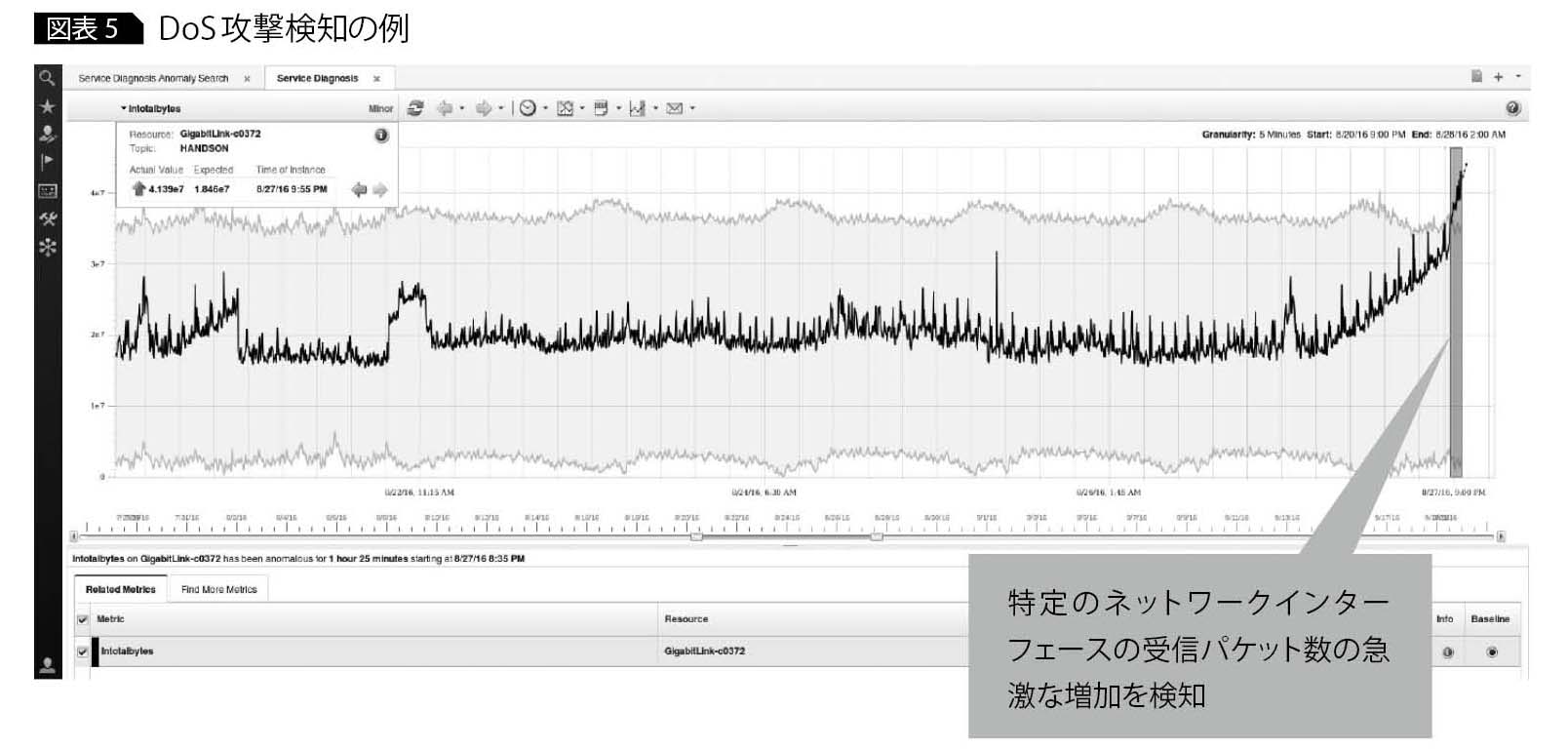
DoS攻撃や性能劣化の検知
DoS攻撃や性能劣化は、一般的に閾値監視では検知しにくいとされる。通常時のアクセス数や性能情報の推移を把握していないと、気づきにくいからだ。しかし閾値を低く設定すると不要なアラートの原因となり、逆に高く設定すると検知が遅れて、業務やサービスに影響を及ぼすことになる。
IOAPIを使用すれば、平常時の挙動パターンと照らし合わせて監視するので、アクセス数や性能情報にいつもと違う推移が見られた際、早期発見が可能になる(図表5)。
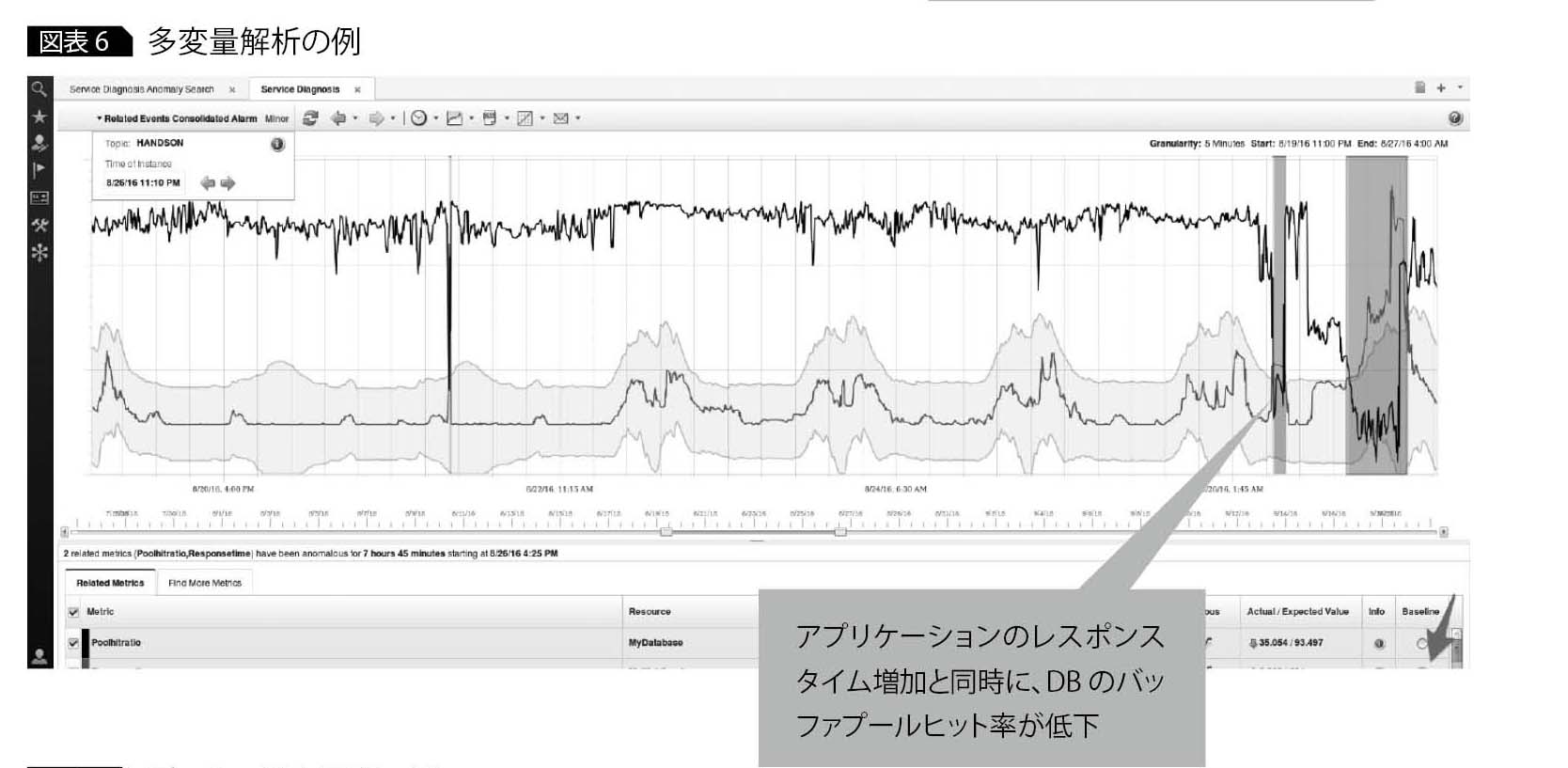
多変量解析による原因分析
パフォーマンス低下などのサイレント障害に関する原因を分析する場合、複数の性能情報をスプレッドシートでグラフ化し、それらの相関から原因を探るケースがある。
IOAPIでは多変量解析によって複数のメトリクスの関係を学習し、あるメトリクスで異常を検知した際に関連のあるメトリクスを自動検出する。これにより、「Webアプリケーションのレスポンスタイム増化と同時に、DBのバッファプールヒット率の低下も発生していた」など、メトリックの相関関係を洗い出せるので、障害時の根本原因分析を迅速化できる(図表6)。
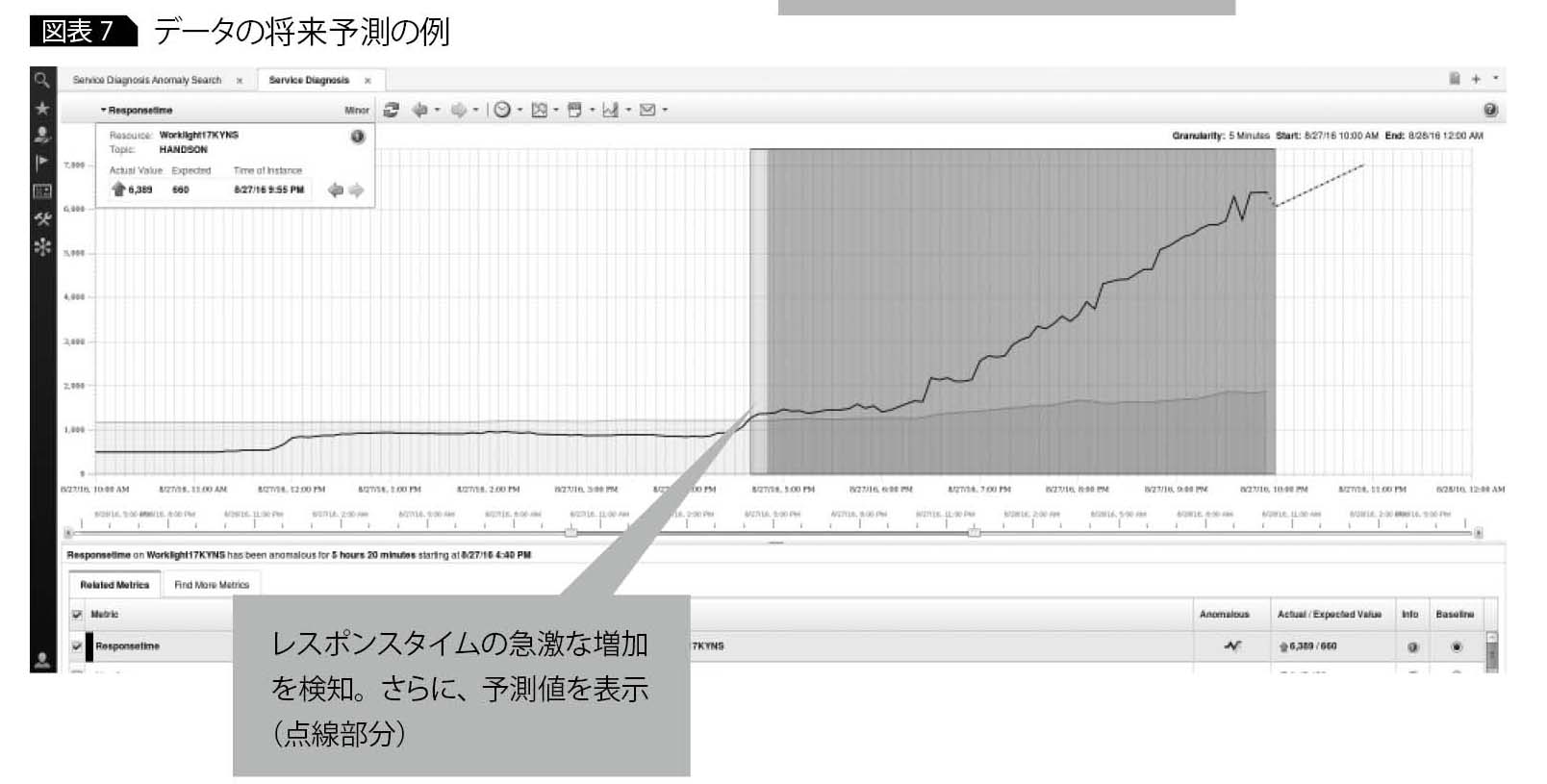
データの将来予測
多変量解析は、データの将来予測を可能にする。たとえば、あるWebアプリケーションのレスポンスが急激に増化している場合、IOAPIでレスポンスタイムの予測値を確認することで、SLAの維持が困難となるリスクを事前に把握し、対応が可能となる(図表7)。
コグニティブ技術を活用した
次世代システム監視
IOAPIなどのコグニティブ技術を活用した監視ツールを利用することで、システム障害の予兆を検知し、業務やサービスへの影響を未然に防ぐというプロアクティブな監視が可能となる。またこれらのツールが備える分析機能を用いて、リアクティブな監視における障害の原因分析とサービス復旧の迅速化が期待できる。
ビジネスとITの結びつきがより強くなり、顧客へ絶え間なくサービスを提供し続けることの重要性がますます高まっている今、早期に予兆を検知して、システム障害を未然に防ぐプロアクティブな監視も取り入れるべきである。
しかし、障害予兆検知は万能ではない。あくまでも通常時と異なる兆候を早期に検知するのであって、障害の発生を100%未然に防止することを保証するわけではない。ログ監視や死活監視、従来の閾値監視は依然として必要である。
システムやアプリケーション、サービスのパフォーマンス劣化など、動的に推移するメトリックの継続的な監視と分析が必要なものは障害予兆検知で対応し、ログメッセージやコンポーネントの死活などは従来の監視で対応するハイブリッドな監視こそが、コグニティブ時代のシステム監視のあり方であると考える。
著者|江川 聡子

日本アイ・ビー・エム システムズ・エンジニアリング株式会社
クラウド・ソリューション
クラウド・アプリケーション
シニアITスペシャリスト
IBMシステム管理製品(Tivoli)の担当者としてシステム運用管理ソリューションに長年携わり、システム構築・移行サービスの技術レビューやコンサルテーション、問題解決支援などに携わる。近年は複数のユーザープロジェクトに従事し、IBMシステム管理ソリューションの適用を担当している。